一种适用于水下姿势聚类的方法及装置与流程
- 国知局
- 2024-11-12 14:08:22
本发明涉及水下手势识别,具体为一种适用于水下姿势聚类的方法及装置。
背景技术:
1、在许多水下任务中,自动水下机器人(auv)由人类潜水员陪同,由于无法说话,他们通过不同的手势进行非语言交流。然而,由于缺乏注释数据集,水下手势识别在计算机视觉中是一个相对欠发达的领域。主要有两个挑战:首先,水下图像存在对比度低、模糊、色彩失真和模糊等问题;因此,传统的手势识别方法在分析它们时面临着问题。其次,现有的手势识别模型主要是有监督的,并且只能从用于训练模型的预定义集合中识别手势,显然不可能列举所有手势,不可能为人类潜水员在野外可能使用的每一个可能的手势收集数千张标记图像。
2、此外,水下手势识别算法的可扩展性和可维护性也存在一定的问题。随着水下作业领域的不断发展和应用需求的不断增加,手势识别算法需要不断地进行更新和升级。然而,目前的水下手势识别算法在可扩展性和可维护性方面仍存在一定的不足,难以满足未来应用的需求。
3、因此,急需对此缺点进行改进,本发明则是针对现有的技术及不足予以研究改良,提供有一种适用于水下姿势聚类的方法及装置。
技术实现思路
1、本发明的目的在于提供一种适用于水下姿势聚类的方法及装置,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、第一方面,提供了一种适用于水下姿势聚类的方法,包括以下步骤:
4、s1、通过训练一个深度网络,将其图像嵌入与一组固定的目标点对齐,来学习有用的图像表示,让目标点均匀地分散在d维空间上;
5、假设是一组图像,是深度神经网络进行的映射操作,的输出均统一用l2归一化方法进行归一化(l2归一化方法是一种常见的数据预处理技术,主要用于将数据的每个特征缩放到相同的尺度,以改善模型的训练效率和性能);
6、z是一个d维的向量;
7、所谓目标点是指进行一个向量的映射,从图像的嵌入,统一映射到另外一个向量空间的表示;假设是映射后的向量,每个图像,需要通过一个映射p,映射到一个(y就是标签,y∈,y的取值为1-k,图像分类),优化目标的公式表示为:
8、——公式1;
9、其中,,表示欧几里得距离;
10、该优化问题以随机方式,通过在随机抽样的小批量上迭代求解;具体操作为:给定一小批图像(b表示batch),然后计算,然后公式1通过匈牙利算法,在这个小批量的上对p进行优化,优化目标是最小化源图像嵌入和目标转换向量之间的欧几里得距离;体现到具体实现上为:计算神经网络的参数的训练;通过训练参数,使得图像的嵌入能够通过,完成目标向量的映射;后续针对映射后的目标向量空间,进行分组和聚类操作;
11、s2、转换后的向量,均进行归一化操作;若都均匀分布,则不适合无监督聚类,聚类之间的分界线会模糊,需引入多模态分布,因为会在目标空间中产生分离;在本案中,使用混合高斯分布(gmm)将归一化后的向量,投影到球面:
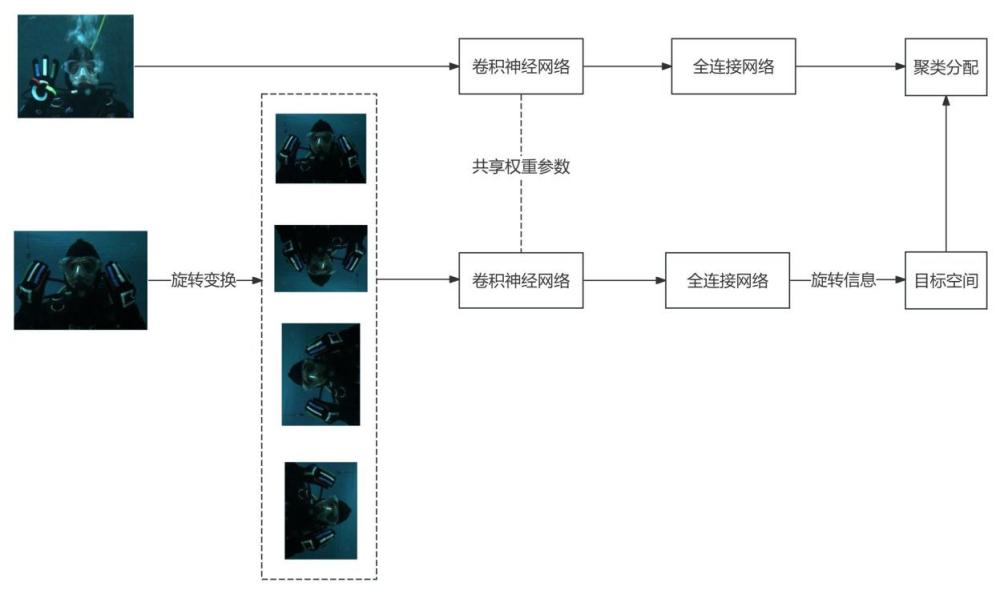
12、;
13、;
14、所述高斯分布的概率密度函数表示为k个高斯分布的加权平均,d是嵌入的向量空间维度,是权值,是正态分布,或者说高斯分布,其中期望是,协方差矩阵是;并认为每个高斯分布都是相似的,
15、,公式,表示进行l2归一化;
16、图片的聚类分配采用如下公式:
17、;
18、argmin是机器学习的常用公式,官方的定义:
19、;
20、s3、在优化聚类目标的同时,卷积神经网络模型学习图像表征,并对图像分类;采用alexnet作为卷积神经网络的基础网络,损失函数定义为:——公式2;
21、其中,是翻转变换,将标签为y的图像进行指定的几种翻转操作,y是标签,是网络的参数,是预测标签y的图像翻转后的结果(神经网络预测的结果都是一个概率分布);
22、所述卷积神经网络默认采用alexnet网络结构:
23、激活函数都用relu;2、3层卷积层之间加入3×3的最大池化操作;
24、跟原始的alexnet差异在于,原始的alexnet的结构由于算力不够,分成了2个部分,本案合并成一个部分;
25、所述卷积神经网络后的全连接网络,默认采用3层结构,每层4096个神经元,激活函数采用relu,并可根据具体情况进行调整。
26、进一步的,所述步骤s1中,l2归一化方法通过对数据集中的每个特征向量进行缩放,使得缩放后的特征向量的l2范数等于某个预定义的值,通常是1,l2范数即欧几里得距离或向量的模。
27、进一步的,所述步骤s2详细流程描述如下:
28、主要参数均可根据需要进行调整:
29、输入图像,表示两个卷积神经网络,k表示需要分类的数量,iters表示迭代次数,epoch表示训练的轮次,表示分布的方差,d表示嵌入向量的维度,λ表示学习率且是参数,g表示随机的进行图像翻转操作,r表示一个batch中图像翻转的实例数量;
30、损失函数loss见公式2;
31、对于每个epoch,也就是每轮训练:
32、迭代i=1到iters次:
33、从数据中取得一个小批量的,已经初始的分类;
34、计算;
35、通过最小化公式1,更新p;
36、针对图像的翻转变换,然后通过公式1,计算损失loss,根据损失loss更新网络参数梯度;
37、根据λ学习率,更新神经网络的参数;
38、迭代i=1到iters次:
39、从数据中取得一个小批量的;
40、对进行翻转{0°,90°,180°,270°};
41、将翻转后的图像输入神经网络,损失函数是loss;
42、根据λ学习率,更新神经网络的参数θ;
43、上面的两个部分,主要就是对公式1以及神经网络进行训练。
44、进一步的,所述alexnet网络结构具体包括:输入层、卷积层1、卷积层2、卷积层3、卷积层4、卷积层5,且各层的高、宽、通道数用表示,依次为:输入层(224×224×3)、卷积层1(55×55×96)、卷积层2(27×27×256)、卷积层3(13×13×384)、卷积层4(13×13×384)、卷积层5(13×13×256)。
45、第二方面,提供了一种适用于水下姿势聚类的装置,应用于如上述的适用于水下姿势聚类的方法,所述装置包括:存储器、处理器以及存储在所述存储器上并可在处理器上运行的计算机程序指令,所述处理器执行所述计算机程序指令时实现如上述的适用于水下姿势聚类的方法。
46、第三方面,提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,所述计算机执行指令被处理器执行时用于实现如上述的适用于水下姿势聚类的方法。
47、本发明提供了一种适用于水下姿势聚类的方法及装置,具备以下有益效果:
48、本发明提出了一个无监督聚类方法,以端到端方式构建深度神经网络,在没有额外处理的情况下提供姿态图像的直接聚类分配;采用多模态深度聚类,训练深度网络将图像嵌入与从高斯混合模型分布中采样的目标点对齐,通过图像嵌入的混合分量关联来确定聚类分配;同时,深度网络被训练来解决预测图像旋转,促进更好的聚类,适用水下不稳定的拍摄环境。
49、本发明能够通过学习已知空间的特征,准确归类未知的图片,通过学习一部分已知的手势样本,达到正确归类未知样本的目标。
本文地址:https://www.jishuxx.com/zhuanli/20241112/327435.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表