一种能源行业大数据的语料库自动构建方法及系统与流程
- 国知局
- 2024-11-06 15:10:38
本发明涉及自然语言处理,具体为一种能源行业大数据的语料库自动构建方法及系统。
背景技术:
1、在过去十几年内,事件关系抽取的研究主要基于一系列人工标注的语料,但受限于成本和领域特性,现有的语料库规模较小且领域有限,限制了模型训练的效果和应用范围。因此,自动构建大规模、专业领域的事件关系语料库成为研究者持续关注的热点。尽管目前的研究已经在通用领域取得一定的成果,但在能源领域,事件关系抽取的语料构建仍处于初级阶段,因此,如何在通用领域的基础上进一步开展能源领域的事件关系语料构建研究,是当前研究者们面临的一个重要问题。
2、目前在能源事件关系抽取领域尚未发现公开的大规模语料,由于能源事件关系的复杂性,通用领域的语料构建方法不能很好地应对能源事件关系语料构建任务,限制了相关研究的进展。因此,如何针对能源事件关系的复杂性设计高精度和高效率的自动标注方法以构建大规模能源事件关系语料,是深入研究能源事件关系抽取亟需解决的问题。
技术实现思路
1、鉴于上述存在的问题,提出了本发明。
2、因此,本发明解决的技术问题是:通用领域的语料构建方法不能很好地应对能源事件关系语料构建任务,效率和精度不足。
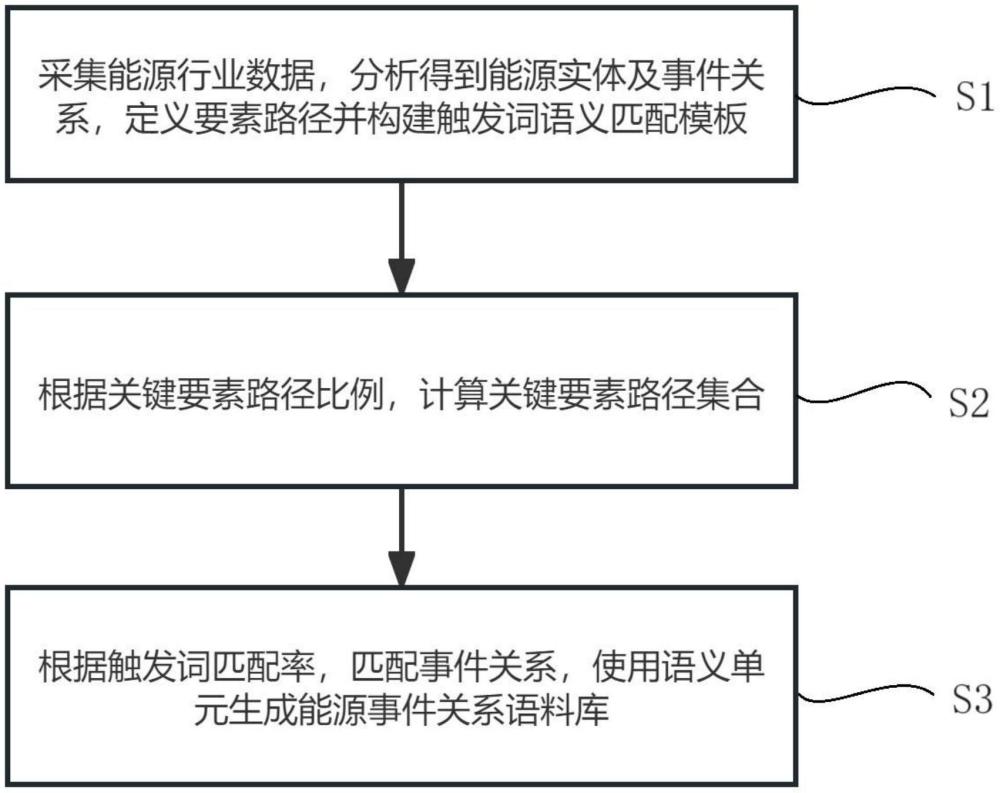
3、为解决上述技术问题,本发明提供如下技术方案:一种能源行业大数据的语料库自动构建方法,包括:采集能源行业数据,分析得到能源实体及事件关系,定义要素路径并构建触发词语义匹配模板;根据关键要素路径比例,计算关键要素路径集合;根据触发词匹配率,匹配事件关系,使用语义单元生成能源事件关系语料库。
4、作为本发明所述的能源行业大数据的语料库自动构建方法的一种优选方案,其中:所述要素路径包括触发词t1通过要素1的角色类型边连接至要素1,随后经由要素关系连接至要素2,并通过要素2的角色类型边连接至触发词t2;其中,触发词t1和要素1属于事件e1,触发词t2和要素2属于事件e2,角色类型边表示能源事件内部要素与触发词单元之间的关系,使用多条要素路径标注复杂事件。
5、作为本发明所述的能源行业大数据的语料库自动构建方法的一种优选方案,其中:计算所述关键要素路径集合包括,计算要素路径重要性apsij,表示为:
6、
7、其中,count(pai,etpj)表示知识库中第j个语义关系类型etpj下包含第i个要素路径pai的样本数;count(etpj)表示知识库中第j个语义关系类型etpj下所有的样本总数;
8、计算事件关系相关性erri:
9、
10、其中,sum(etp)表示知识库中语义关系类型集合etp中所有语义关系类型数;count(etpci)表示知识库含有第i个要素路径pai的语义关系类型数;ε表示防止分母为0的常数;
11、计算关键要素路径比例krarpij:
12、krarpij=apsij*erri
13、计算每一个事件语义关系类型的关键要素路径比例krarpij,排序选出最前面k个要素路径作为当前关键要素路径集合。
14、作为本发明所述的能源行业大数据的语料库自动构建方法的一种优选方案,其中:所述匹配事件关系包括,根据触发词匹配率,从触发词语义匹配模板中选取关键要素路径覆盖比例最高的语义类型,匹配事件关系,计算触发词对候选频率tpceij,表示为:
15、
16、其中,count(epi,tpsj)表示文本中第i个触发词对epi在第j个事件语义类型对tpsj下的样本数;count(tpsj)表示文档中第j个语义类型对tpsj包含所有触发词对的数目;
17、计算触发词语义匹配频率tpmfi:
18、
19、其中,sum(etp)表示语义类型对集合etp中语义类型对的总数;count(etpsi)表示包含触发词对epi的语义类型对的数目;
20、计算触发词匹配率tmrij:
21、tmrij=tpcfij*tpmfi
22、对一个触发词对,选择tmrij最大的事件语义关系类型为触发词对匹配的事件关系。
23、作为本发明所述的能源行业大数据的语料库自动构建方法的一种优选方案,其中:所述语义单元包括,根据触发词对与知识库映射的framenet语义单元的查询关系,进行事件关系扩展和噪声过滤;当知识库映射的framenet语义单元中可查询到文本中触发词对时,知识库映射对应框架的语义单元中的单词、词组被用来扩展触发词对的规模,进而扩展事件关系的标注规模,得到大规模自动标注的能源事件关系语料;若知识库映射的framenet语义单元中未查询到文本中触发词对,则对应触发词对作为噪声过滤。
24、作为本发明所述的能源行业大数据的语料库自动构建方法的一种优选方案,其中:所述语义单元还包括,建立事件关系抽取模型,采用两阶段对事件关系抽取模型训练和回标,并验证自动标注的结果的准确性;
25、第一阶段,建立事件关系抽取模型并进行预训练,事件关系抽取模型以bert模型为基础,bert模型的损失函数旨在语言建模和句子预测,引入关键要素路径比例作为辅助任务,通过多任务学习框架,在训练过程中同时优化语言模型和事件关系特征提取,表示为:
26、
27、其中,表示预训练阶段的损失函数;表示bert模型的mlm损失函数;表示bert模型的nsp损失函数;λ1表示权重参数;ni表示预训练数据中要素路径的总数;nj表示预训练数据中语义关系类型的总数;第二阶段,将经过人工标注的高质量数据集划分为训练、验证、测试集,经过预训练的事件关系抽取模型通过高质量数据集进行微调,减小预测与真实结果的偏差,表示为:
28、
29、其中,表示微调阶段的损失函数;m表示高质量数据集中样本总数;yj表示高质量数据集的真实标签;表示高质量数据集的预测标签;λ2表示权重参数;l表示特征向量zj的数量;ψl(zj)表示高质量数据集的归一化特征变换函数。
30、作为本发明所述的能源行业大数据的语料库自动构建方法的一种优选方案,其中:生成所述能源事件关系语料库包括,使用两阶段训练后的事件关系抽取模型对大规模自动标注的能源事件关系语料进行回标,回标数据与高质量数据集的数据构成能源事件关系语料库。
31、第二方面,本发明还提供了能源行业大数据的语料库自动构建系统,包括,采集模块,采集能源行业数据,分析得到能源实体及事件关系,定义要素路径并构建触发词语义匹配模板;计算模块,根据采集的数据计算关键要素路径比例和触发词匹配率,获得关键要素路径集合;匹配模块,以bert模型为基础建立事件关系抽取模型,并进行二阶段训练,使用训练后的事件关系抽取模型对大规模自动标注的能源事件关系语料进行回标,生成能源事件关系语料库。
32、第三方面,本发明还提供了一种计算设备,包括:存储器和处理器;
33、所述存储器用于存储计算机可执行指令,所述处理器用于执行所述计算机可执行指令,该计算机可执行指令被处理器执行时实现所述能源行业大数据的语料库自动构建方法的步骤。
34、第四方面,本发明还提供了一种计算机可读存储介质,其存储有计算机可执行指令,该计算机可执行指令被处理器执行时实现所述能源行业大数据的语料库自动构建方法的步骤。
35、本发明的有益效果:本发明通过采集和分析能源数据,定义要素路径并构建触发词语义匹配模板,奠定了数据处理基础。计算关键要素路径集合,优化匹配模板,提高匹配精度。随后,通过匹配事件关系,使用语义单元生成高质量语料库,确保丰富的事件关系和实体信息。建立事件关系抽取模型并进行两阶段训练,生成的语料库具备高准确性和全面性,显著提升了大数据分析和应用的效率与可靠性。
本文地址:https://www.jishuxx.com/zhuanli/20241106/325652.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表