基于联邦学习的保护隐私且鲁棒的个性化图像识别方法
- 国知局
- 2024-11-18 18:16:19
本发明属于隐私计算中的联邦学习,尤其涉及一种基于联邦学习的保护隐私且鲁棒的个性化图像识别方法
背景技术:
1、近年来,随着硬件性能的改进和数据量的快速增长,机器学习的性能不断提高,应用场景逐渐丰富。在传统的集中式机器学习中,海量数据需要集中到一个机器上进行训练,然而如此不加监管的转移,对敏感数据是十分危险的。随着人们对数据隐私的日益重视和相关保护条例的出台,联邦学习作为分布式机器学习的范式之一,逐渐引起广泛关注。在联邦学习中,数据不需要进行转移,参与者在本地进行模型的训练,并向服务器发送训练结果,服务器聚合所有参与者提交的结果作为全局模型。联邦学习在保护参与者数据隐私的同时,可以达到和集中式学习相近的训练效果,解决不同机构间存在的数据孤岛问题。自2016年联邦学习的概念首次提出以来,相关研究和应用发展得如火如荼。目前,已有成熟的联邦学习系统应用于政务、医疗、金融等领域。
2、尽管训练数据不离开本地在一定程度上保护了参与者的隐私,但有大量研究表明,服务器可发起推理攻击,即根据参与者提交的模型或梯度来恢复数据的有效信息,因此仅依靠联邦学习机制本身来保护敏感数据是不充分的。目前,参与者可选择密码学相关的安全聚合方法或差分隐私机制,来避免服务器直接观察到所提交模型或梯度的初始值。此外,联邦学习的系统环境较为复杂,参与者数量庞大且没有身份认证,可能存在有恶意攻击者试图破坏全局模型的收敛过程、降低全局模型的性能或在全局模型中插入后门,进行数据中毒攻击、模型中毒攻击或后门攻击等。目前,服务器可采用异常检测手段来去除潜在攻击者提交的更新,只对判断为非恶意的更新进行聚合。
3、一般的联邦学习场景旨在训练单个总体模型,在数据非独立同分布的情况下,参与者应用该模型的方向不尽相同,单个模型无法满足参与者的个性化需求。因此,旨在为不同参与者训练不同模型的个性化联邦学习方法被提出,多任务学习是其中代表方法之一。在基于多任务学习的个性化联邦学习中,每一类参与者在训练过程中生成一个适用于本地数据分布的模型,不同类参与者模型间的差异或大或小。然而,现有的多任务学习框架不能在保护训练数据隐私的同时,有效防御模型中毒攻击、后门攻击等攻击手段。因此,将隐私保护手段引入多任务学习中,并与适用于个性化场景的防御手段结合,是十分重要的。
4、四、现有技术的缺点及本发明所要解决的技术问题
5、现有的基于多任务学习的个性化联邦学习方法,不能同时进行隐私保护和攻击防御。有若干研究为解决梯度泄露问题,在参与者训练过程中加入差分隐私机制,但仅加入噪声仍不能有效防御多种攻击,训练过程或参与者得到的最终模型仍然易受到攻击者的影响。此外,一些研究关注个性化框架本身带来的防御效果,或将其与一般联邦学习场景中的防御手段简单结合,没有考虑对训练数据隐私的保护,和这些防御手段在多任务学习中的适用性。
技术实现思路
1、为解决上述问题,本发明提供一种基于联邦学习的保护隐私且鲁棒的个性化图像识别方法,在保护训练数据隐私的同时能够防御数据中毒、模型中毒等多种攻击,提高系统的运行效率,降低系统的维护成本。
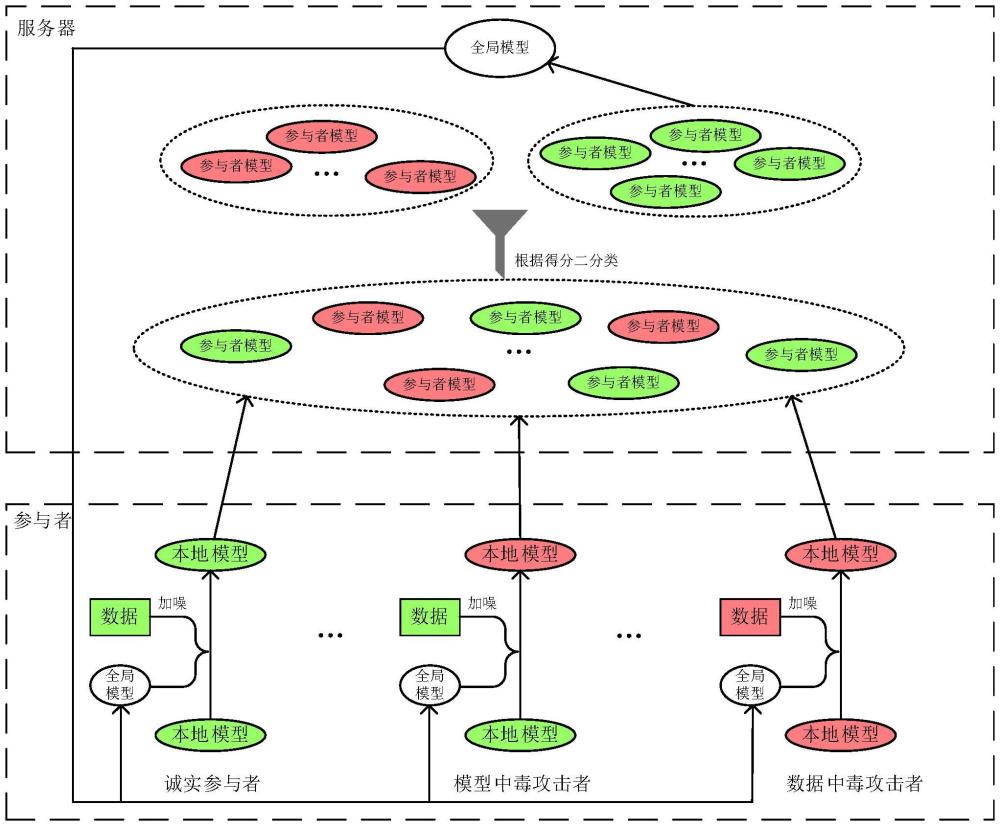
2、一种基于联邦学习的保护隐私且鲁棒的个性化图像识别方法,各参与者采用图像识别本地模型对图像进行个性化识别;其中,各参与者的图像识别本地模型的训练方法包括以下步骤:
3、s1:中心服务器向各参与者发送初始化后的图像识别全局模型;其中,各参与者的本地训练集所包含的图像样本数相同,且每个图像样本对应一个标签,所有参与者包含的图像样本对应的标签类别数为n,各参与者包含的图像样本对应的标签类别不完全相同,且各参与者包含的图像样本对应的标签类别数不超过n/2;
4、s2:判断是否为首轮迭代,若为是,各参与者基于本地训练集的平均梯度执行带差分隐私的随机梯度下降算法来更新自身的图像识别本地模型;若为否,各参与者根据本地训练集的平均梯度与图像识别全局模型的模型参数θg获取融合梯度,然后基于融合梯度执行带差分隐私的随机梯度下降算法来更新自身的图像识别本地模型;其中,图像识别本地模型与图像识别全局模型的结构相同;
5、s3:各参与者分别获取自身更新后的图像识别本地模型的模型参数θl与图像识别全局模型的模型参数θg之间的差值mk=θl-θg,其中,k=1,2,…,k,k为参与者的个数;
6、s4:中心服务器分别各参与者的差值mk计算一个分值scorek,并采用k-means聚类算法对所有分值scorek进行二分类;
7、s5:获取包含更多分值的类别中所有差值mk的平均值并将平均值与模型参数θg的和值作为图像识别全局模型在下一轮的模型参数;
8、s6:判断当前迭代次数是否达到上限,若为是,得到各参与者最终的图像识别本地模型,若为否,将步骤s5得到的图像识别全局模型发送给各参与者,然后重新执行步骤s2~s6。
9、进一步地,步骤s2中任意一个参与者的本地训练集的平均梯度的计算方法具体为:
10、s21:对每一个图像样本xi产生的梯度g(xi)进行裁剪,得到裁剪后的梯度
11、
12、其中,c为单个图像样本梯度的最大二范数,||·||2表示计算二范数;
13、s22:从高斯分布中采样噪声,并将噪声与裁剪后的梯度之和相加,得到本地训练集所包含的图像样本的平均梯度
14、
15、其中,l为本地训练集所包含的图像样本数量,σ为满足不等式的辅助变量,δ为差分隐私的概率,ε为差分隐私的隐私预算,i为单位矩阵。
16、进一步地,步骤s4中任意一个参与者k的差值mk对应的分值scorek的计算方法为:
17、s41:假设参与者k对应的差值mk=[mk,1,mk,2,…,mk,n],其中,mk,1~mk,n为参与者k对应的模型参数包含的各参数的差值,n为模型参数θl中包含的参数个数;
18、s42:获取参与者k与其余参与者的欧氏距离disk,j:
19、
20、其中,参与者j对应的差值mj=[mj,1,mj,2,…,mj,n],mj,1~mj,n为参与者k对应的模型参数包含的各参数的差值;
21、s43:将参与者k与所有参与者的欧氏距离disk,j的和值作为参与者k的差值mk对应的分值scorek。
22、进一步地,步骤s2中任意一个参与者的融合梯度的计算方法为:
23、
24、其中,为参与者k对应的融合梯度,为参与者k对应的平均梯度,λ为设定权重,θl[k]为参与者k对应的图像识别本地模型的模型参数。
25、进一步地,步骤s4中采用k-means聚类算法对所有分值scorek进行二分类的方法具体为:
26、s4a:随机选择两个分值作为两个簇的起始质心c1和c2;
27、s4b:分别计算每一个分值screk与起始质心c1之间的距离dk,1、与起始质心c2之间的距离dk,2:
28、dk,1=scorek-c1|
29、dk,2=|scorek-c2|
30、s4c:对于每一个分值scorek,对比其对应的dk,1和dk,2,并将各分值scorek划分到距离更小的簇中,完成当前二分类;
31、s4d:判断当前得到的二分类结果与上一次迭代得到的二分类结果是否相同,若为是,则完成二分类,若为否,进入步骤s4e;
32、s4e:获取当前二分类的两个簇包含的分值的平均值,并将两个平均值作为两个簇的质心;
33、s4f:基于两个簇的新的质心重复执行步骤s4b~s4d,直到完成二分类。
34、有益效果:
35、本发明提供一种基于联邦学习的保护隐私且鲁棒的个性化图像识别方法,首先,采用差分隐私机制保护用户隐私,与同态加密、安全多方计算等密码学手段相比,无需分发密钥或考虑用户的准入准出机制,提高系统的运行效率,降低系统的维护成本;其次,相比现有框架只关注隐私或中毒攻击,没有实现同时考虑上述二者的训练框架,本发明能够在个性化联邦学习中同时保护用户隐私和防御潜在攻击;综上所述,本发明是基于平均正则化多任务学习的个性化图像识别方法,在保护训练数据隐私的同时能够防御数据中毒、模型中毒等多种攻击,中心服务器应用该规则可有效过滤掉占比低于50%的潜在攻击者。
本文地址:https://www.jishuxx.com/zhuanli/20241118/327936.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。