一种基于动量更新的多任务小粒度权重平均方法及系统
- 国知局
- 2024-11-19 09:46:17
本发明涉及图像处理和机器学习,特别是指一种基于动量更新的多任务小粒度权重平均方法及系统。
背景技术:
1、多任务学习(multi-task learning,mtl)目标是利用多个学习任务中所包含的有用信息来帮助为每个任务学习得到更为准确的学习器,是机器学习领域的经典应用之一。在传统机器学习算法领域中,多任务场景下需要将其分为独立的单任务,为每个任务定制独立的超参数和特征提取方法,导致不同任务间无法共享信息,尤其是在一些相关任务中,不同任务的信息往往能为彼此带来增益,而独立的任务设置让彼此互不相干无法互相辅助支撑。多任务学习的优势在于,使不同任务在计算过程中分享底层信息,在相关任务的训练过程中,可以使不同任务优化过程相互联动,在一定程度上降低训练难度,同时降低了参数量,节省了计算资源,避免过拟合的风险。
2、对多任务学习来说,如何平衡各个任务的损失以避免在学习过程中仅实现一个任务的有效收敛,是一个极其重要的问题。一般而言,在训练多任务模型前,将所有的损失用固定权重放缩到同一个数量级并求和即可进行多任务学习,但在某些情况下,单个任务的收敛速度较快,其对应的损失超出原有的数量级,导致神经网络会将优化重心转移到其他的任务,从而会破坏收敛好的任务损失的稳定状态。因此,如何寻找一种方法能够使所有任务同时达到收敛的稳定状态是多任务学习领域中研究的重点。
3、目前针对该问题,alex kendall等人提出了基于不确定性估计对多任务损失进行加权的方法,[kendall a, gal y, cipolla r. multi-task learning usinguncertainty to weigh losses for scene geometry and semantics[c]//proceedingsof the ieee conference on computer vision and pattern recognition. 2018:7482-7491.],通过模型对任务的认知不确定性和偶然不确定性进行预测,使不确定度小的获得更大的权重,以此提升多任务学习的效果。michelle guo等人提出了动态任务优先级方法,[guo m, haque a, huang d a, et al. dynamic task prioritization formultitask learning[c]//proceedings of the european conference on computervision (eccv). 2018: 270-287.],使用各自任务专用的评估指标,将任务的优化程度通过评估指标量化为优先级数值,让效果较差的任务分支具有更大的损失占比。shikun liu等人提出了动态加权平衡的方法计算多任务损失权重,[liu s, johns e, davison a j.end-to-end multi-task learning with attention[c]//proceedings of the ieee/cvfconference on computer vision and pattern recognition. 2019: 1871-1880.],该方法旨在按照各个损失的下降速度来动态计算损失权重,使用当前轮次与上个轮次的损失比值来表征损失下降速度,将损失下降较快的任务权重适当放低,损失下降较慢甚至上升的任务权重进行放大,以此来实现多任务的平衡。但由于只在每个轮次的初始时刻使用前两个轮次的历史平均损失进行更新,之后整个轮次都使用相同的权值,在轮次内部,对批次粒度的损失变化状态缺少敏感性,致使任务损失权值动态变化的周期过长,导致损失曲线震荡难以有效收敛。同时,对于从历史轮次平均损失值指导当前轮次导致时间跨度过长,难以保证指导量的有效性。因此,亟需重新设计新的多任务损失函数,确保多任务学习模型在训练过程中稳定地收敛。
技术实现思路
1、为了解决现有方案多任务学习模型批次粒度的损失变化缺乏敏感性无法稳定收敛的技术问题,本发明实施例提供了一种基于动量更新的多任务小粒度权重平均方法及系统。所述技术方案如下:
2、一方面,提供了一种基于动量更新的多任务小粒度权重平均方法,其特征在于,所述方法包括:
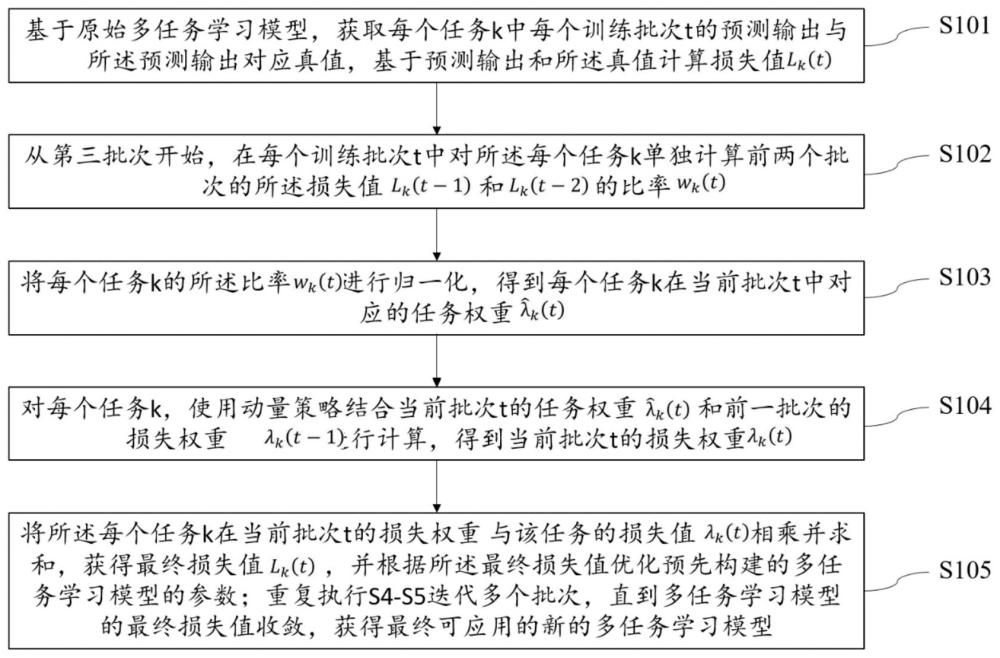
3、s1、基于原始多任务学习模型,获取每个任务k中每个训练批次t的预测输出与所述预测输出对应真值,基于所述预测输出和所述真值计算损失值;
4、s2、从第三批次开始,在每个训练批次t中对所述每个任务k单独计算前两个批次的所述损失值和的比率;
5、s3、将每个任务k的所述比率进行归一化,得到每个任务k在当前批次t中对应的任务权重;
6、s4、对每个任务k,使用动量策略结合当前批次t的任务权重和前一批次的损失权重进行计算,得到当前批次t的损失权重;
7、s5、将所述每个任务k在当前批次t的损失权重与该任务的损失值相乘并求和,获得最终损失值,并根据所述最终损失值优化预先构建的多任务学习模型的参数;重复执行s4-s5迭代多个批次,直到多任务学习模型的最终损失值收敛,获得最终可应用的新的多任务学习模型。
8、可选地,s1中,损失值计算方法包括:l1范式和l2范式的一种或多种。
9、可选地,s2中,从第三批次开始,在每个训练批次t中对所述每个任务k单独计算前两个批次的所述损失值和的比率,包括:
10、从第三批次开始,根据下述公式(1)在每个训练批次t中对所述每个任务k单独计算前两个批次的所述损失值和的比率:
11、 (1)。
12、可选地,s3,将每个任务k的所述比率进行归一化,得到每个任务k在当前批次t中对应的任务权重,包括:
13、根据下述公式(2)将每个任务k的所述比率进行归一化,得到每个任务k在当前批次t中对应的任务权重:
14、 (2)
15、其中,t与k为超参数,t的大小代表了多个任务的相似性,当t较大,各个任务的权重会趋向相同;k用于保证权重之和统一。
16、可选地,s4中,对每个任务k,使用动量策略结合当前批次t的任务权重和前一批次的损失权重进行计算,得到当前批次t的损失权重,包括:
17、对每个任务k,根据下述公式(3),使用动量策略结合当前批次t的任务权重和前一批次的损失权重计算得到当前批次t的损失权重:
18、 (3)
19、其中,m为动量权重,取值范围在0到1之间。
20、可选地,s5中,将所述每个任务k在当前批次t的损失权重与该任务的损失值相乘并求和,获得最终损失值,包括:
21、根据下述公式(4),将所述每个任务k在当前批次t的损失权重与该任务的损失值相乘并求和,获得最终损失值:
22、 (4)
23、其中,loss为多任务学习模型的最终损失值。
24、另一方面,提供了一种基于动量更新的多任务小粒度权重平均系统,该系统应用于基于动量更新的多任务小粒度权重平均方法,该系统包括:
25、损失生成模块,用于基于原始多任务学习模型,获取每个任务k中每个训练批次t的预测输出与所述预测输出对应真值,基于所述预测输出和所述真值计算损失值;
26、比率计算模块,用于从第三批次开始,在每个训练批次t中对所述每个任务k单独计算前两个批次的所述损失值和的比率;
27、迭代计算模块,用于将每个任务k的所述比率进行归一化,得到每个任务k在当前批次t中对应的任务权重;对每个任务k,使用动量策略结合当前批次t的任务权重和前一批次的损失权重进行计算,得到当前批次t的损失权重;
28、模型优化模块,用于将所述每个任务k在当前批次t的损失权重与该任务的损失值相乘并求和,获得最终损失值,并根据所述最终损失值优化预先构建的多任务学习模型的参数;重复执行s4-s5迭代多个批次,直到多任务学习模型的最终损失值收敛,获得最终可应用的新的多任务学习模型。
29、另一方面,提供一种基于动量更新的多任务小粒度权重平均设备,所述基于动量更新的多任务小粒度权重平均设备包括:处理器;存储器,所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,实现如上述基于动量更新的多任务小粒度权重平均方法中的任一项方法。
30、另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现上述基于动量更新的多任务小粒度权重平均方法中的任一项方法。
31、本发明实施例提供的技术方案带来的有益效果至少包括:
32、本发明实施例中具备,(1)易用性:本实施例提出的基于动量更新的多任务小粒度权重平均方法没有超参数,不需要根据任务类型手动调整参数,可方便移植到不同的数据上;
33、(2)优异性:本实施例提出的基于动量更新的多任务小粒度权重平均方法可引导多任务学习模型在学习过程中更新周期更短,并且生效粒度更小,权重能够响应短期变化,综合考虑了短期与长期的损失变化,能够得到对下一步损失计算相对来说更有利的权重,从而达成整体的稳定。
本文地址:https://www.jishuxx.com/zhuanli/20241118/330152.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。