一种基于大数据分析的充电桩高峰期排队时间预测方法与流程
- 国知局
- 2024-11-21 11:57:00
本发明涉及大数据分析,尤其涉及一种基于大数据分析的充电桩高峰期排队时间预测方法。
背景技术:
1、随着电动汽车的普及,充电桩成为电动汽车用户的必备设施。然而,充电桩数量有限,特别是在高峰时段,充电桩的使用需求剧增,导致排队等待时间增加,影响了用户体验。准确预测充电桩高峰期的排队时间,对于提高充电桩的利用效率和优化资源分配具有重要意义。传统的时间序列预测方法,如arima(自回归积分滑动平均模型)和lstm(长短期记忆网络),在处理充电桩排队时间预测方面存在一定的局限性。
2、现有的时间序列预测方法主要依赖于线性模型和递归神经网络(rnn),如arima和lstm。arima模型假设时间序列数据是线性的,对于非线性和复杂的时间依赖关系处理能力有限。此外,arima模型对数据的平稳性要求较高,需要对原始数据进行差分操作,以达到平稳性,这在实际应用中增加了数据预处理的复杂性。
3、lstm作为一种递归神经网络,通过引入记忆单元和门控机制,能够在一定程度上捕捉长时间依赖关系。然而,lstm模型在处理长时间序列数据时存在梯度消失和梯度爆炸问题,导致模型训练困难且计算效率低下。此外,lstm在捕捉序列中远距离依赖关系时,性能仍然存在不足。
4、transformer模型的引入为时间序列预测带来了新的希望。transformer模型通过自注意力机制和多头注意力机制,能够有效捕捉序列中各个位置之间的相关性,特别是在处理长时间序列数据时,表现出色。位置编码机制为序列中的每个位置添加了位置信息,使模型能够更好地理解时间序列的顺序和周期性变化。然而,transformer模型主要应用于自然语言处理领域,在时间序列预测任务中的应用仍然相对较少。
5、现有的充电桩排队时间预测方法多采用传统的时间序列模型和基于统计学的方法,如线性回归、arima和lstm等。这些方法虽然在一定程度上能够捕捉到充电桩使用的时间规律,但对于复杂的非线性关系和长时间依赖关系的处理能力有限,导致预测精度和鲁棒性不高。此外,现有方法对数据特征的提取和表示较为单一,无法充分利用充电桩使用数据中的丰富信息,如地理位置、用户行为和环境因素等。
6、因此,如何提供一种基于大数据分析的充电桩高峰期排队时间预测方法是本领域技术人员亟需解决的问题。
技术实现思路
1、本发明的一个目的在于提出一种基于大数据分析的充电桩高峰期排队时间预测方法,本发明结合位置编码、transformer编码器和自监督对比学习方法,精准预测充电桩高峰期排队时间,具备高精度、高鲁棒性、高效率和实时优化的优点。
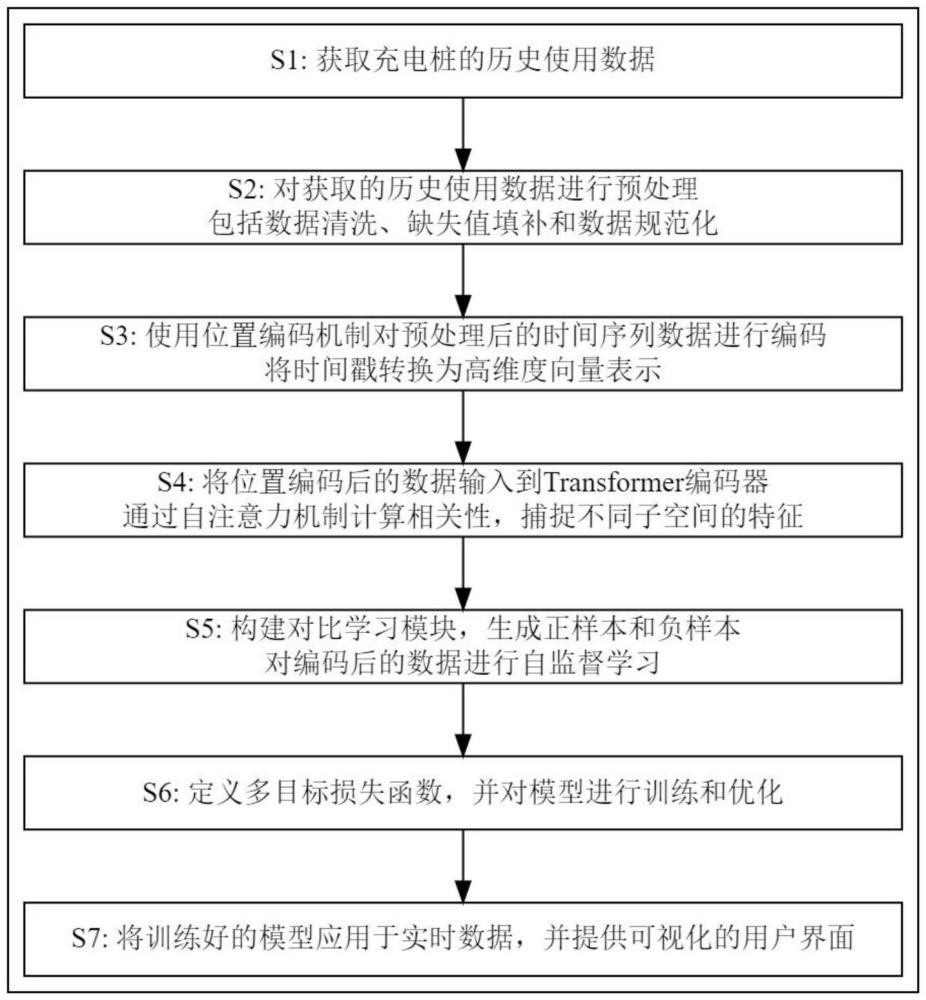
2、根据本发明实施例的一种基于大数据分析的充电桩高峰期排队时间预测方法,包括如下步骤:
3、s1、获取充电桩的历史使用数据;
4、s2、对获取的历史使用数据进行预处理,包括数据清洗、缺失值填补和数据规范化;
5、s3、使用位置编码机制对预处理后的时间序列数据进行编码,将时间戳转换为高维度向量表示;
6、s4、将位置编码后的数据输入到transformer编码器中,通过自注意力机制计算序列中每个位置与其他位置的相关性,并利用多头注意力机制捕捉不同子空间的特征;
7、s5、构建对比学习模块,通过生成正样本和负样本,对编码后的数据进行自监督学习;
8、s6、定义多目标损失函数,并对模型进行训练和优化;
9、s7、将训练好的模型应用于实时数据,并提供可视化的用户界面。
10、进一步的,所述s3具体包括:
11、s31、将预处理后的历史使用数据按时间顺序排列,形成时间序列数据,其中每个时间戳对应的记录包括充电桩的使用状态、使用时长、排队时间、充电量、用户id、地理位置和天气状况;
12、s32、使用位置编码机制对时间序列数据中的每个时间戳进行编码,位置编码采用正弦函数和余弦函数生成,将时间戳转换为高维度向量表示,位置编码公式为:
13、
14、其中,pos表示时间戳的位置索引,i表示维度索引,dmodel表示位置编码向量的维度;
15、s33、将位置编码向量与时间序列数据中的使用状态、使用时长、排队时间、充电量、用户id、地理位置和天气状况特征向量进行拼接,形成新的高维度特征向量:
16、encoded_data(t)=[original_data(t)||pe(t)];
17、其中,||表示向量拼接操作,original_data(t)表示时间序列数据中使用时长、排队时间、充电量、用户id、地理位置和天气状况特征向量,pe(t)表示对应时间戳t的位置编码向量,encoded_data(t)表示时间戳t的高维度特征向量;
18、s34、对拼接后的高维度特征向量进行归一化处理:
19、
20、其中,normalized_data(t)表示归一化处理后的时间戳t的数据,μ(t)表示时间戳t处特征向量的移动平均值,σ2(t)表示时间戳t处特征向量的移动方差,α、β和γ表示可训练参数,用于调整归一化过程的灵活性和稳定性;
21、s35、将归一化处理后获得的高维度特征向量作为最终编码数据。
22、更进一步,所述s4具体包括:
23、s41、将位置编码和归一化处理后的高维度特征向量输入到transformer编码器中,所述transformer编码器包括堆叠的编码层,每个编码层包括多头注意力机制和前馈神经网络;
24、s42、在每个编码层中,使用多头自注意力机制来计算序列中每个位置与其他位置的相关性:
25、
26、其中,q表示查询矩阵,k表示键矩阵,v表示值矩阵,dk表示键向量的维度,λ表示可训练的权重系数,rij表示位置关系矩阵,用于加强特定位置i,j之间的依赖关系;
27、s43、将多头注意力机制的输出进行拼接并通过线性变换,形成编码层的输出:
28、multihead(q,k,v)=concat(head1,head2,…,headh)wo;
29、其中,和wo表示可训练的权重矩阵,h表示头的数量;
30、s44、对多头自注意力机制的输出进行残差连接和归一化处理:
31、output=layernorm(normalized_data(t)+multihead(q,k,v)+β·pe(t));
32、其中,layernorm表示层归一化操作,β表示可训练参数;
33、s45、将残差连接和层归一化处理后的输出输入到前馈神经网络中,前馈神经网络包括两个线性变换和一个relu激活函数:
34、ffn(x)=σ((xw1+b1)w2+b2)+α·dropout(x);
35、其中,w1和w2表示权重矩阵,b1和b2表示偏置向量,σ表示激活函数,α表示可训练参数,dropout(x)表示丢弃法操作,用于防止过拟合;
36、s46、对前馈神经网络的输出进行残差连接和层归一化处理:
37、output=layernorm(normalized_data(t)+
38、ffn(normalized_data(t))+γ·pe(t));
39、其中,γ表示可训练参数;
40、s47、重复s42-s46,直至通过所有堆叠的编码层,最终输出高维度特征向量作为transformer编码器的结果。
41、更进一步,所述s5具体包括:
42、s51、将编码后高维度特征向量通过一个投影头映射到一个新的特征空间,映射公式为:
43、zi=w2·relu(w1·hi+b1)+b2;
44、其中,zi表示映射到新特征空间的特征向量,hi表示输入的高维度特征向量,w1和w2表示全连接层的权重矩阵,b1和b2表示全连接层的偏置向量,relu表示修正线性单元激活函数;
45、s52、计算正样本对和负样本对之间的余弦相似度:
46、
47、其中,sim(zi,zj)表示样本i和样本j的特征向量之间的余弦相似度,zi表示样本i的特征向量,zj表示样本j的特征向量,·表示向量的点积运算,||·||表示向量的范数;
48、s53、定义对比损失函数,使用基于温度参数的对比损失:
49、
50、其中,lcontrastive表示对比损失值,表示样本i和正样本之间的余弦相似度,sim(zi,zk)表示样本i和样本k之间的余弦相似度,τ表示温度参数,n表示样本总数;
51、s54、最小化对比损失函数,调整模型参数。
52、更进一步,所述多目标损失函数为:
53、ltotal=λ1lmse+λ2lcontrastive+λ3lsmooth;
54、其中,λ1,λ2和λ3表示权重系数;
55、lmse表示均方误差损失:
56、
57、其中,n表示样本总数,yi表示第i个样本的真实值,表示第i个样本的预测值;
58、lsmooth表示时间序列平滑损失:
59、
60、其中,t表示时间步长,表示时间步t的预测值,表示时间步t+1的预测值。
61、本发明的有益效果是:
62、(1)丰富时间特征表示:位置编码机制通过正弦函数和余弦函数生成高维度向量,为时间序列中的每个位置添加了位置信息,使模型能够捕捉时间序列中的顺序和周期性变化。相比传统方法中简单的数值表示,位置编码使时间特征更具表达力,提高了模型对时间依赖关系的理解。
63、(2)提升长时间依赖关系捕捉能力:采用transformer编码器,通过自注意力机制和多头注意力机制,有效捕捉序列中各个位置之间的相关性。transformer模型能够并行计算,处理长时间序列数据时表现出色,相比rnn和lstm,能够更好地捕捉长距离时间依赖关系,提高了对充电桩使用数据中周期性和突发性变化的解析能力。
64、(3)增强特征表示的鲁棒性和泛化能力:自监督对比学习模块通过生成正样本和负样本,利用对比损失函数最大化正样本和负样本之间的距离,提升模型特征表示的区分能力和鲁棒性。正样本为与输入样本相似的样本,负样本为与输入样本不相似的样本,通过这种自监督学习方法,模型能够更有效地学习到充电桩使用数据中的潜在模式,提高特征表示的质量。
65、(4)综合优化预测精度和特征区别能力:设计多目标损失函数,结合均方误差(mse)、对比损失和时间平滑损失,综合考虑预测误差、特征表示区分能力和时间序列平滑性。多目标损失函数平衡了多个优化目标,确保模型在提高预测准确性的同时,保持特征表示的区分能力和时间序列的连续性与平滑性,实现更全面的性能优化。
66、(5)提高计算能力:transformer编码器具有强大的并行计算能力,能够高效处理大规模时间序列数据。相比传统的递归神经网络(rnn)和长短期记忆网络(lstm),transformer在计算效率和模型训练速度上具有显著优势,使得本方法能够在充电桩大数据环境中快速应用和部署。
67、(6)实时预测和优化:通过将训练好的模型应用于实时数据,提供精准的排队时间预测,并结合可视化的用户界面,提升用户体验和运营效率。实时预测和优化不仅帮助用户合理安排充电时间,减少排队等待,还为运营商提供了有效的充电桩调度和管理决策支持。
本文地址:https://www.jishuxx.com/zhuanli/20241120/333531.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。