一种基于生成对抗网络和长短时记忆网络的航迹预测方法
- 国知局
- 2024-11-25 14:58:50
本发明涉及航空航天领域,特别涉及一种基于生成对抗网络和长短时记忆网络的航迹预测方法。
背景技术:
1、航空技术的进步使得飞机轨迹补全算法成为航空领域研究的热点。该算法旨在解决飞行过程中由于多种原因导致的轨迹数据缺失问题,对飞行安全和数据准确性至关重要。目前,插值方法作为基础技术被广泛使用,包括线性插值、多项式插值和样条插值等,它们通过在已知点间建立数学模型来推断和补全轨迹数据。然而,由于飞行器轨迹的复杂性和多变性,这些方法在处理非线性和复杂系统时面临挑战。
2、为了克服现有方法的局限性,研究者们提出了多种新算法。针对ads-b数据的缺失问题,通过建立多约束条件判别模型筛选缺失点,并采用改进的邻近算法和多重插补法进行轨迹修复。此外基于航向角动态变化研究者们提出了丢失轨迹点插值拟合补全算法。孙立双等人提出了邻域等比补齐算法,利用邻域轨迹的连续性特征来确定补齐点位置。yu等人研究了基于神经加速度估计器的离散卡尔曼滤波轨迹预测算法,适用于军事飞行器轨迹预测和补全。此外,深度学习方法,如bi-lstm和transformer,也被应用于轨迹补全,利用其非线性处理能力和自注意力机制来提高预测准确性。
3、尽管已有研究取得了进展,但轨迹补全领域仍面临一些挑战。基于物理模型的方法需要大量先验知识和经验,难以适应复杂多变的实际情况。深度学习算法虽然提供了新的解决方案,但小样本学习问题仍然是一个难题,因为实际中获取足够的样本非常困难。目前,小样本学习的研究集中在数据增强、假设空间约束和搜索策略调整三个方面,旨在通过先验知识扩展小样本数据集,提高模型的泛化能力和可信度。然而,如何系统地设计小样本学习策略,以及如何处理样本量过少导致的模型结构和参数不一致性问题,仍是研究中需要进一步探索的难点。
技术实现思路
1、本发明的目的在于克服现有技术存在的缺陷,解决小样本条件下的飞行器轨迹缺失预测问题。
2、为实现以上目的,本发明提出一种基于生成对抗网络和长短时记忆网络的航迹预测方法,包括如下步骤:
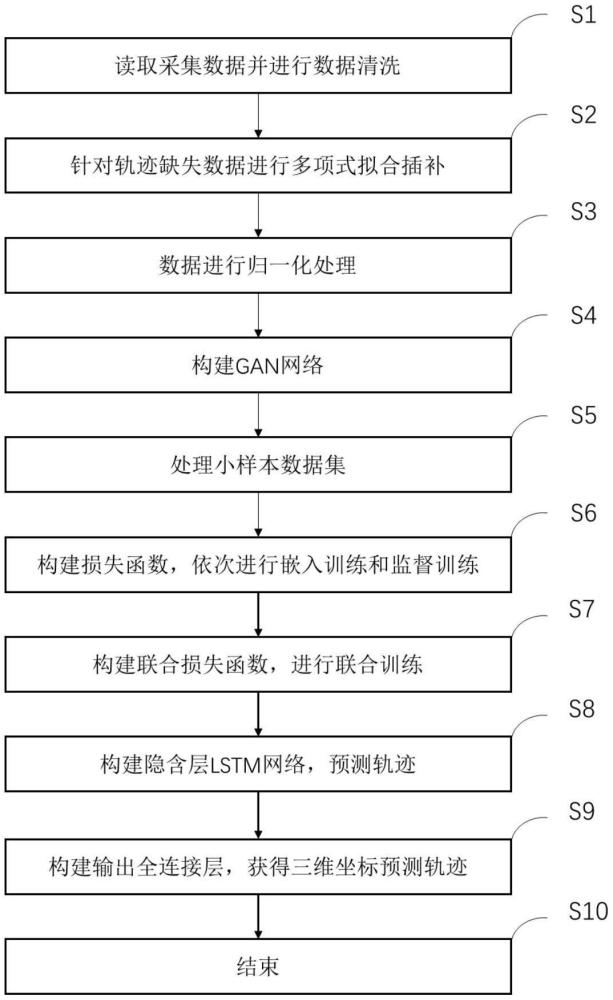
3、s1、读取采集数据并进行数据清洗。
4、s2、针对轨迹缺失数据进行多项式拟合插补。由于轨迹向量与时序具有一定的线性相关性,因此可以利用已知数据构建拟合多项式来填补缺失轨迹数据。拟合多项式为:
5、
6、其中,ym是预测的因变量值,α0是截距项,αi是回归系数,xi是x中第i个自变量的值,n是数据总数。
7、s3、将三维轨迹特征数据进行归一化处理。将原始数据映射到区间[0,1]的归一化公式为:
8、
9、其中,下标x为轨迹向量中第x维数据,下标i为第i个数据,f′为经过映射变换后的值,f为变换前的值,f′xi表示第x维中第i个原始数据值fxi经过归一化处理后的值。f为变换前所有向量的集合,即f={f1,f2,…,fi,…,fn},fx为变换前所有向量的集合中的第x维数据,n为数据总数。
10、s4、处理小样本数据集。具体过程为:首先根据意图对小样本数据集进行分割,将意图相同的航迹,保持其时间顺序提取至新数据集,使得分割后的数据集仅包含单类意图数据。
11、s5、构建timegan网络。timegan网络包括五部分,分别为生成网络、嵌入网络、恢复网络、鉴别网络和监督网络。每个网络的结构都为24层循环神经网络加全连接层构成。
12、s6、构建损失函数,依次进行嵌入训练和监督训练。通过对这四个网络的训练使得数据在经过嵌入网络与恢复网络后能够保持与原来相似的分布。首先给出输入x和噪声z在通过不同网络后的输出表示,其中噪声z为输入数据x形状一致的0至1均匀分布的随机噪声。输入x经过嵌入网络得到的输出用h表示,h经过恢复网络得到的输出用表示,h经过监督网络得到的输出用表示,h经过鉴别网络得到的输出用yreal表示;噪声z经过生成网络得到的输出用表示,经过监督网络得到的输出用表示,经过恢复网络得到的输出用表示,经过鉴别网络得到的输出用yfake表示,经过鉴别网络得到的输出用yefake表示。
13、并将五种网络的所有参数分别存到一个列表中,嵌入网络的参数列表用ev表示,恢复网络的参数列表用er表示,生成网络的参数列表用eg表示,监督网络的参数列表用es表示,鉴别网络的参数列表用ed表示。
14、具体过程为:在嵌入训练过程中计算均方损失:
15、
16、其中,n为数据总数,下标i为数据中第i个分量,xi为输入数据中的第i个分量,为中的第i个分量。利用均方误差来评估两者之间的差异,并采用adam优化器对eloss更新参数
17、其中,θ1为需要更新的参数,包括ev和er,α表示学习率,是一个超参数,用于控制每次更新的步长大小。为梯度的无偏估计,用于指导参数更新的方向。为梯度的无偏估计的方差。∈为一个很小的正数,用于数值稳定性,防止分母为零。
18、在监督训练过程中计算均方损失:
19、
20、其中,n为数据总数,下标i为数据中第i个分量,xi为输入数据中的第i个分量,为中的第i个分量。利用两者的均方误差作为监督网络的损失,并采用adam优化器对gloss更新参数
21、其中,θ2为需要更新的参数,包括eg和es,α表示学习率,是一个超参数,用于控制每次更新的步长大小。为梯度的无偏估计,用于指导参数更新的方向。为梯度的无偏估计的方差。∈为一个很小的正数,用于数值稳定性,防止分母为零。
22、s7、构建联合损失函数,进行联合训练。首先计算yfake和与yfake相同形状的全1向量的交叉熵损失,其次计算yefake和与yefake相同形状的全1向量的交叉熵损失,其中用于将任意实数映射到(0,1)区间内,n是样本的总数,yfake,i是yfake中第i个样本的的预测值(即模型的输出),yefake,i是yefake中第i个样本的的预测值。计算ggloss=gloss+glossfr+glossfre,采用adam优化器对ggloss更新参数
23、其中,θ3为需要更新的参数,包括eg和es,α表示学习率,是一个超参数,用于控制每次更新的步长大小。为梯度的无偏估计,用于指导参数更新的方向。为梯度的无偏估计的方差。∈为一个很小的正数,用于数值稳定性,防止分母为零。
24、计算yreal和与yreal相同形状的全1向量的交叉熵损失,其次计算yfake和与yfake相同形状的全0向量的交叉熵损失,其次计算yefake和与yefake相同形状的全0向量的交叉熵损失,其中用于将任意实数映射到(0,1)区间内,n是样本的总数,yfake,i是yfake中第i个样本的的预测值(即模型的输出),yefake,i是yefake中第i个样本的的预测值。计算gdloss=glossrr+glossff+glossffe,采用adam优化器对gdloss更新参数
25、其中,θ4为需要更新的参数,包括ed,α表示学习率,是一个超参数,用于控制每次更新的步长大小。为梯度的无偏估计,用于指导参数更新的方向。为梯度的无偏估计的方差。∈为一个很小的正数,用于数值稳定性,防止分母为零。
26、在每个训练批次中,都先对θ3更新两次,再对θ4更新一次。
27、s8、构建隐含层lstm网络,预测轨迹。具体过程为:通过下式构建遗忘门、更新门和输出门:
28、γf=σ(wf[ht-1,xt]+bf)
29、γu=σ(wu[ht-1,xt]+bu)
30、γa=σ(wa[ht-1,xt]+ba)
31、其中,γf、γu和γa分别表示遗忘门、更新门和输出门,σ为sigmoid函数,wf、wu和wa为对应部分的权重系数矩阵,h为输出特征,x为输入特征,下标t表示当前时刻,t-1表示上一时刻,bf、bu和ba为对应部分的偏移向量。通过下式计算候选神经元:
32、
33、其中,wc为该部分对应的权重系数矩阵,bc为该部分对应的偏移向量。通过下式计算更新后的神经元:
34、
35、通过下式计算当前时刻的输出特征:
36、ht=γa*tanh ct
37、s9、构建输出全连接层,获得三维坐标预测轨迹。具体过程为:通过下式构建全连接层:
38、yf=wf·ht+bf
39、其中,wf是全连接层的权重矩阵,bf是全连接层的偏置量,yf是全连接层的输出标量,包含一个时间步的预测轨迹信息。预测时每次预测一个维度的一个时间步的轨迹点,最终输出对应一个时间步三维坐标预测轨迹。
40、与现有技术相比,本发明的优点及有益效果在于:针对航迹预测任务中存在的轨迹数据缺失、长期依赖、梯度消失以及训练数据有限、实时性和泛化能力不强的问题,提出了小样本数据增强与小样本意图识别,以及利用数据之间的时空关联性和历史信息进行轨迹补全的航迹预测方法,同时保证了轨迹预测算法的快速性、鲁棒性和准确性;构造了能够对原始数据进行扩充的gan网络和对轨迹进行补全的lstm网络。
本文地址:https://www.jishuxx.com/zhuanli/20241125/335570.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表