神经机器翻译中的分歧建模的制作方法
- 国知局
- 2024-11-25 15:21:31
背景技术:
1、机器翻译(mt)是将一种语言的书面句子自动翻译成另一种语言。mt的神经模型(即神经机器翻译(nmt))可以尝试解决不同种类的不确定性。这可以包括模型本身不确定两个或更多个翻译中的哪一个是正确的模型不确定性,以及输入句子有多于一个正确翻译的内在不确定性。现有nmt模型可以使用softmax层来定义所有目标语言句子上的概率分布。虽然该方法可以通过相应地散布概率质量来解释不确定性,但它无法区分不同种类的不确定性。
2、该缺点可能导致神经机器翻译模型出现许多弊病(pathology)。一种此类弊病是,当在推理时增加集束尺寸时(当模型在更大的翻译空间中搜索时),与参考翻译相比,模型更偏好短翻译。可以通过将模型分数除以翻译长度的函数或对较长的候选翻译使用奖励来解决该弊病。然而,此类修复是事后补救(post-hoc),并没有解决这些弊病的根本原因。因此,当使用较大的集束尺寸时,此类nmt方法可以产生较低质量的结果或以其他方式遭受性能劣化。因此,采用此类方法的应用和服务可能无法提供合适或适当的结果。
技术实现思路
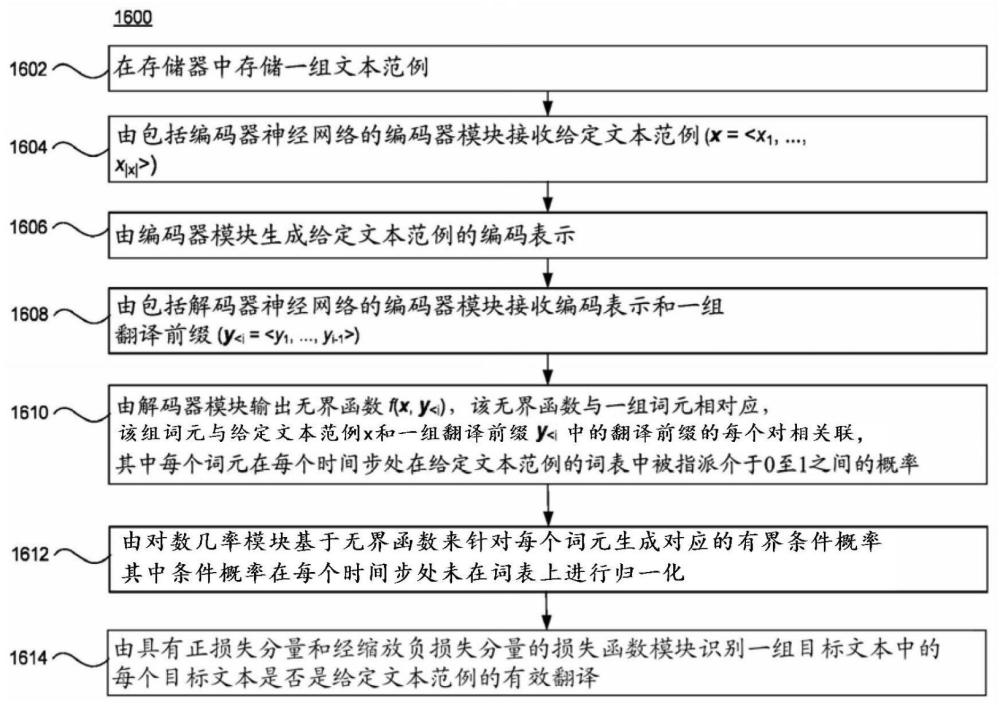
1、本技术的方面将机器翻译视为多标签分类任务。系统不是针对源句子x学习针对所有目标句子y的单一分布p(y|x),而是针对每个句子对(x,y)学习指示y是否是x的有效翻译的二元分类器。在该框架中,内在不确定性可以通过同时将两个(或更多个)正确翻译y1和y2的概率设置为1来表示。可以使用单独的二元分类器来计算每个翻译的概率,并且因此不要求所有翻译的概率总和为一。与使用softmax输出层的典型机器翻译模型(例如,transformer模型)相比,本文的分歧建模方法利用sigmoid激活(或另一有界激活函数),该sigmoid激活在每个时间步处将介于0至1之间的概率指派给词表(该组所有词元)中的每个词元。此外,本文中称为“非排他性序列的单标签对比目标”(scones)的损失函数允许在单一参考训练数据上训练模型。这允许对非排他性输出进行建模。该方法可以在内在不确定性方面提供优于现有技术的明显改善,并减轻那些其他技术所遇到的弊病。虽然该方法对于文本翻译情形特别地有益,但它也适用于如下模型的其他类型的分类问题:针对该模型,训练语料库通常包含单个参考,但在实践中可以接受多个标签。一个这种类型是文本分类,诸如对报纸文章、网站内容或医疗诊断进行分类的情况。
2、根据本技术的一个方面,一种被配置用于机器翻译模型的系统。该系统包括存储器,该存储器被配置为存储呈源语言的一组文本范例和呈不同于源语言的一种或多种语言的一组重写文本;以及一个或多个处理元件,该一个或多个处理元件操作地耦合到存储器。该一个或多个处理元件将机器翻译模型实现为具有编码器模块和解码器模块的神经网络。该编码器模块包括编码器神经网络,该编码器神经网络被配置为接收给定文本范例(x = <x1, ..., x|x|>)并且生成给定文本范例的编码表示。该解码器模块包括解码器神经网络,该解码器神经网络被配置为接收编码表示和一组翻译前缀(y<i = <y1, ..., yi-1>)并且输出无界函数f(x, y<i),该无界函数与给定文本范例x和该组翻译前缀y<i中的翻译前缀的每个对相关联的一组词元相对应,其中每个词元在每个时间步处在给定文本范例的词表中被指派介于0至1之间的概率。对数几率模块被配置为作用于无界函数以针对每个词元生成对应的有界条件概率,其中条件概率在每个时间步处未在词表上进行归一化。损失函数模块具有正损失分量和经缩放负损失分量,其中该损失函数模块被配置为识别一组目标文本中的每个目标文本是否是给定文本范例的有效翻译。
3、该组文本范例可以包括一组输入句子,并且该系统被配置为针对每个句子对(x,y)学习指示y是否是x的有效翻译的二元分类器。这里,内在不确定性可以通过将至少两个正确翻译y1和y2的条件概率同时设置为最大概率来表示。替代地或附加地,对数几率模块被配置为使用单独的二元分类器生成每个翻译的概率。
4、根据上述任何一项,给定文本范例的完整翻译的概率可以被分解成词元级概率的乘积。替代地或附加地,对数几率模块被配置为在每个时间步处将s型激活应用于无界函数。替代地或附加地,正损失分量将对数函数应用于每个参考词元的有界条件概率,并且经缩放负损失分量将对数函数应用于每个非参考词元的有界条件概率。替代地或附加地,在推理期间,该系统被配置为搜索具有成为待翻译文本片段的翻译的最高概率的翻译。
5、根据上述任一项,该系统被配置为表达与机器翻译模型相关联的内在不确定性。替代地或附加地,该损失函数模块被配置为调整负损失分量的缩放以最大化翻译性能。
6、根据上述任一项,编码器模块和解码器模块包括自注意力神经网络编码器-解码器架构。替代地,编码器模块和解码器模块可以包括序列到序列模型架构。
7、根据另一方面,一种机器翻译方法采用神经网络,并且该方法包括:在存储器中存储一组文本范例;由包括编码器神经网络的编码器模块接收给定文本范例(x = <x1, ...,x|x|>);由编码器模块生成给定文本范例的编码表示;由解码器模块接收编码表示和一组翻译前缀(y<i = <y1, ..., yi-1>);由解码器模块输出无界函数f(x, y<i),该无界函数与给定文本范例x和该组翻译前缀y<i中的翻译前缀的每个对相关联的一组词元相对应,其中每个词元在每个时间步处在给定文本范例的词表中被指派介于0至1之间的概率;由对数几率模块基于无界函数来针对每个词元生成对应的有界条件概率,其中条件概率在每个时间步处未在词表上进行归一化;以及由具有正损失分量和经缩放负损失分量的损失函数模块识别一组目标文本中的每个目标文本是否是给定文本范例的有效翻译。
8、在一个示例中,该组文本范例包括一组输入句子,并且该方法包括:针对每个句子对(x,y)学习指示y是否是x的有效翻译的二元分类器。这里,内在不确定性可以通过将至少两个正确翻译y1和y2的条件概率同时设置为最大概率来表示。替代地或附加地,针对每个词元生成对应的有界条件概率包括使用单独的二元分类器来生成每个翻译的概率。
9、根据上述任何一项,给定文本范例的完整翻译的概率可以被分解成词元级概率的乘积。替代地或附加地,针对每个词元生成对应的有界条件概率可以包括在每个时间步处将sigmoid激活应用于无界函数。替代地或附加地,正损失分量可以将对数函数应用于每个词元的有界条件概率,并且经缩放负损失分量可以将对数函数应用于每个词元的有界条件概率。
10、根据上述任一项,该方法可以进一步包括:在推理期间搜索具有成为待翻译文本片段的翻译的最高概率的翻译。替代地或附加地,该方法可以进一步包括:调整负损失分量的缩放以最大化翻译性能。
技术特征:1.一种被配置用于机器翻译模型的系统,所述系统包括:
2.如权利要求1所述的系统,其中所述一组文本范例包括一组输入句子,并且所述系统被配置为针对每个句子对(x,y)学习指示y是否是x的有效翻译的二元分类器。
3.如权利要求2所述的系统,其中内在不确定性是通过将至少两个正确翻译y1和y2的所述条件概率同时设置为最大概率来表示的。
4.如权利要求2所述的系统,其中所述对数几率模块被配置为使用单独的二元分类器来生成每个翻译的概率。
5.如权利要求1所述的系统,其中所述给定文本范例的完整翻译的概率被分解成词元级概率的乘积。
6.如权利要求1所述的系统,其中所述对数几率模块被配置为在每个时间步处将sigmoid激活应用于所述无界函数。
7.如权利要求1所述的系统,其中所述正损失分量将对数函数应用于每个参考词元的所述有界条件概率,并且所述经缩放负损失分量将对数函数应用于每个非参考词元的所述有界条件概率。
8.如权利要求1所述的系统,其中在推理期间,所述系统被配置为搜索具有成为待翻译文本片段的翻译的最高概率的翻译。
9.如权利要求1所述的系统,其中所述系统被配置为表达与机器翻译模型相关联的内在不确定性。
10.如权利要求1所述的系统,其中所述损失函数模块被配置为调整所述负损失分量的缩放以最大化翻译性能。
11.如权利要求1所述的系统,其中所述编码器模块和所述解码器模块包括自注意力神经网络编码器-解码器架构。
12.如权利要求1所述的系统,其中所述编码器模块和所述解码器模块包括序列到序列模型架构。
13.一种采用神经网络的机器翻译方法,所述方法包括:
14.如权利要求13所述的方法,其中所述一组文本范例包括一组输入句子,并且所述方法包括针对每个句子对(x,y)学习指示y是否是x的有效翻译的二元分类器。
15.如权利要求14所述的方法,其中内在不确定性是通过将至少两个正确翻译y1和y2的所述条件概率同时设置为最大概率来表示的。
16.如权利要求14所述的方法,其中针对每个词元生成对应的有界条件概率包括使用单独的二元分类器来生成每个翻译的概率。
17.如权利要求13所述的方法,其中所述给定文本范例的完整翻译的概率被分解成词元级概率的乘积。
18.如权利要求13所述的方法,其中针对每个词元生成对应的有界条件概率包括在每个时间步处将sigmoid激活应用于所述无界函数。
19.如权利要求13所述的方法,其中所述正损失分量将对数函数应用于每个词元的所述有界条件概率,并且所述经缩放负损失分量将对数函数应用于每个词元的所述有界条件概率。
20.如权利要求13所述的方法,进一步包括:在推理期间,搜索具有成为待翻译文本片段的翻译的最高概率的翻译。
21.如权利要求13所述的方法,进一步包括:调整所述负损失分量的缩放以最大化翻译性能。
技术总结本技术解决了神经机器翻译中的分歧。编码器模块接收给定文本范例并且生成给定文本范例的编码表示。解码器模块接收编码表示和一组翻译前缀。解码器模块输出无界函数,该无界函数与一组词元相对应,该组词元与给定文本样本和该组翻译前缀中的翻译前缀的每个对相关联。每个词元在每个时间步处在范例的词表中被指派介于0至1之间的概率。对数几率模块基于无界函数来针对每个词元生成对应的有界条件概率,其中概率在每个时间步处未在词表上进行归一化。具有正损失分量和经缩放负损失分量的损失函数模块识别一组目标文本中的每个目标文本是否是范例的有效翻译。技术研发人员:菲利克斯·斯塔尔伯格,山卡尔·库玛尔受保护的技术使用者:谷歌有限责任公司技术研发日:技术公布日:2024/11/21本文地址:https://www.jishuxx.com/zhuanli/20241125/337449.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表