一种融合轨迹关联技术的动态场景多目标跟踪方法
- 国知局
- 2024-12-06 12:32:41
本发明涉及计算机视觉与人工智能,尤其涉及一种融合轨迹关联技术的动态场景多目标跟踪方法。
背景技术:
1、多目标跟踪mot是计算机视觉领域的一项关键任务,在智能交通系统和视频监控等应用中起着重要作用[1]。特别是在视频监控领域,mot技术广泛应用于犯罪分析和预防,为维护社会安全提供了有力支持。此外,mot是姿态估计、行为识别和行为分析等高级计算机视觉任务的基础[2,3]。执行mot任务需要逐帧检测输入的视频序列以获取目标位置信息,提取目标的再识别外观特征,结合运动和再识别模型计算相似性,并为每个目标分配固定长度的id,最终获得跟踪目标的轨迹信息。随着深度学习技术的发展,基于深度学习的mot方法受到了极大的关注,尤其是由于物体检测技术的进步。高性能的物体检测模型[4]引发了对基于检测的跟踪方法的兴趣。目前,基于深度学习的方法将mot任务分解为物体检测、特征提取和数据关联等子任务,使得跟踪算法更加高效和准确。
2、然而,在动态环境中,mot面临一系列挑战。首先,目标的多样性和复杂性增加了跟踪的难度。目标形状的变化和相似目标的干扰常常模糊和扭曲行人运动模式,给跟踪算法带来了挑战,因为它们难以准确区分和跟踪这些目标。这可能导致将一个目标误识别为多个轨迹或将多个目标错误分类到同一轨迹下。这个问题在缺乏全局关联信息的在线跟踪器中尤为常见。为了更好地利用轨迹间的信息,一些方法[5,6]提出使用链接模型将短轨迹与轨迹连接起来。然而,这些方法往往导致轨迹片段不完整。虽然这些方法可以提高跟踪性能,但它们依赖于计算昂贵的模型,尤其是外观嵌入模型。其次,目标的快速移动也会导致跟踪偏差。在跟踪行人等目标类别时,这些因素经常引起跟踪干扰,使多目标跟踪更加困难。通常,iou被广泛用于衡量几何一致性[7-9]。一些方法[11,12]将transformer[13]引入多目标跟踪研究中,实现了跨帧外观相似性的精确测量,从而取得了良好的跟踪性能。然而,在实际操作中,运动模型可能并不总是准确的,特别是在行人进行不规则运动的情况下,例如在行人密度更高、运动模式更复杂多样的mot20数据集中,运动估计模型往往失效。最后,目标遮挡和环境噪声干扰导致轨迹中断和碎片化轨迹问题。线性插值[14]被广泛用于补偿这些漏检,但它在插值过程中忽略了运动信息,限制了跟踪精度。最近,strongsort[15]提出使用高斯过程回归对非线性运动进行建模以缓解这一问题。然而,这些插值方法并没有考虑到真实路径的实际轨迹,因为视频帧中的物体并不会沿着平滑的曲线移动,为了解决以上问题,需要采用更加有效的算法,能够更好地模拟目标的真实运动路径,并能够适应各种复杂的环境和动态变化,从而提高多目标跟踪的鲁棒性和准确性。在过去十年中,多目标跟踪受到了广泛关注,并产生了许多重要的研究成果。多目标跟踪中出现了两种主要的跟踪范式:检测后跟踪tracking-by-detection,简称tbd和联合检测跟踪joint-detection-tracking,简称jdt;tbd利用检测器在每一帧中检测目标,然后使用数据关联方法将检测结果与前一帧中跟踪的目标关联起来,以获得目标的运动轨迹。jdt在每一帧中同时执行目标检测和跟踪。在这些工作中,alex等人[16]提出了sort算法,该算法结合了卡尔曼滤波器和匈牙利算法,构建了一个tbd框架。nicolai等人[17]提出了deepsort方法,该方法利用了深度外观特征提取模型和使用马氏距离加权求和的级联匹配策略,成功将id切换数量减少了45%。sun等人[18]提出了transtrack方法,该方法利用注意力机制在单个网络中同时执行目标检测、特征提取和数据关联三个任务,建立了新的jdt范式。zeng等人[19]通过改进卡尔曼滤波解决了漂移噪声问题,提出了nct方法。此外,zhang等人[14]提出了bytetrack算法,该算法使用yolox[4]作为检测器,通过关联几乎所有检测帧进行跟踪,并利用低评分检测帧与轨迹之间的相似性来恢复真实目标和过滤背景检测。aharon等人[20]提出了bot-sort方法,通过改进卡尔曼滤波器状态向量和相机运动补偿来提高跟踪器的鲁棒性。cao等人[21]提出了oc-sort,使用基于观测的更新策略来减少累积误差。受上述启发,提出了一种适用于动态场景的多目标跟踪算法dstrack,以更好地适应各种复杂场景和动态变化的需求。
3、在处理缺失轨迹时,一些方法[5-6,22]采用全局关联模型来提高多目标跟踪(mot)的性能。这些方法通常基于外观信息生成不完整的轨迹片段,然后利用全局信息进行关联,以减轻遮挡和相似目标干扰造成的轨迹中断。例如,remot[22]通过自监督学习改进的外观特征将不完整的轨迹片段分割并合并。tpm[6]引入了一种轨迹平面匹配过程,将视觉上容易混淆的轨迹分配到不同的轨迹平面,从而减少相似轨迹之间的混淆。giaotrack[5]使用改进的resnet50-tp模型获取轨迹的外观特征,提取轨迹的全局和部分空间特征,以实现更稳健的表示。尽管这些方法取得了一定的成果,但它们严重依赖于目标的外观特征,带来了显著的计算成本。同时,轨迹中断可能导致轨迹碎片、漂移和其他轨迹噪声问题。当发生严重遮挡或模糊时,检测器不可避免地会导致大量漏检,这不仅影响目标的连续跟踪,还可能降低整个跟踪系统的性能。现有的线性插值方法[14]忽略了运动信息,并且没有考虑真实轨迹,限制了边界框恢复的准确性。strongsort提出的gsi算法[15]通过高斯非线性插值将碎片化轨迹转换为平滑曲线,在准确性和效率之间取得了良好平衡,但它忽略了真实轨迹的趋势。因此,需要设计一种新的轨迹链接融合模型和插值方法,可以更准确地处理目标轨迹,更好地应对遮挡和模糊等问题。
技术实现思路
1、本发明的目的在于提供一种融合轨迹关联技术的动态场景多目标跟踪方法,该发明是为了提高复杂动态背景下多目标行人的跟踪能力,通过采用先进的深度学习算法与计算机视觉技术,实现对行人特征的精准提取与追踪,为智能监控、自动驾驶等领域提供更为可靠的技术支持。
2、为了实现上述发明目的,本发明采用技术方案具体为:一种融合轨迹关联技术的动态场景多目标跟踪方法,包括以下步骤:
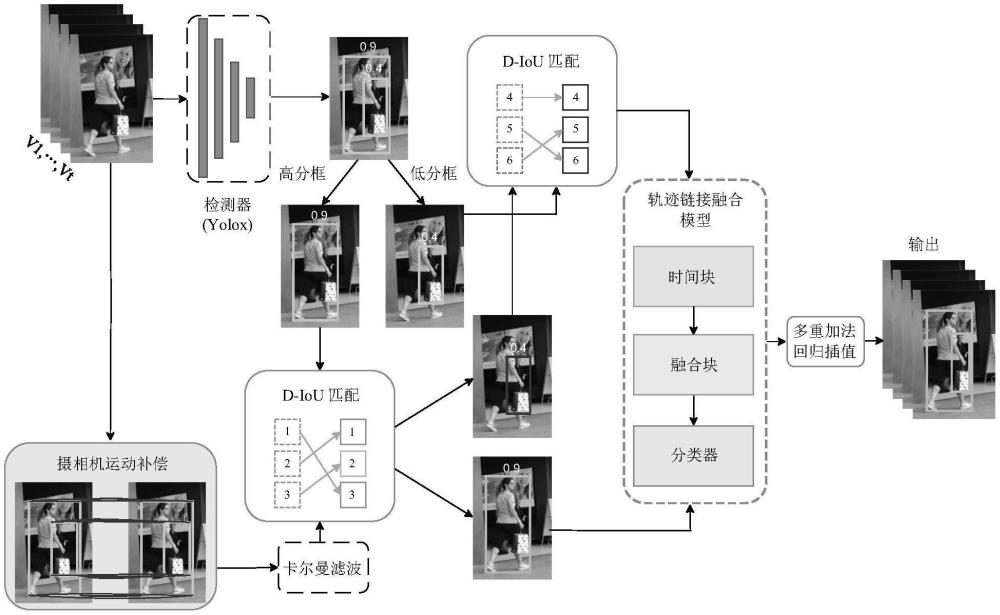
3、s1、视频帧预处理与目标检测:给定的多目标跟踪mot视频序列{vt∈rw×h×3}tt=1的每一帧图片vt按顺序传输到yolox进行目标检测,生成每一帧的边界框,同时将该帧图片vt通过相机运动补偿模型来提高跟踪对摄像机运动的鲁棒性;
4、s2、快速运动目标的跟踪优化:将目标检测到的检测框与跟踪框进行d-iou匹配算法完成最佳匹配,算法通过扩展匹配空间,将原始的非重叠检测结果和轨迹之间构建时空相似性,弥补由于运动估计产生的匹配偏差,实现更好的跨帧几何一致性,从而对快速运动目标的准确跟踪。
5、s3、轨迹链接与融合:跟踪结果输入到轨迹链接融合模型tlfmodel,满足一定时空距离的轨迹进行关联,以此将行人的短轨迹转变为完整的长轨迹。有效解决由相似目标引起的干扰问题,提升跟踪系统的准确性和可靠性。
6、s4、轨迹中断与碎片化的修复:所有的轨迹通过多重加法回归算法mari,算法通过积累预测结果并自适应地逼近基础真值轨迹,实现轨迹碎片的重连。实现目标遮挡和环境噪声干扰造成的轨迹中断和碎片化问题的跟踪。
7、进一步地,所述s1步骤包括以下步骤:
8、s11、给定mot视频序列{vt∈rw×h×3}tt=1,首先将视频序列的每一帧图片vt按顺序传输到yolox进行目标检测,生成每一帧的边界框,并将边界框划分为高分框和低分框。
9、s12、将该帧图片vt通过相机运动补偿模型提高跟踪对摄像机运动的鲁棒性。
10、s13、接下来,将t-1帧的轨迹trackletst-1与相机运动补偿后的结果共同输入到噪声自适应卡尔曼滤波(nsa)中,进行当前帧的预测。
11、进一步地,所述s2步骤包括以下步骤:
12、s21、检测框的高分框与卡尔曼滤波预测的跟踪框进行d-iou匹配算法的匹配,d-iou匹配算法在不改变边界框原始中心点的基础上,通过扩展匹配空间,在原始的非重叠检测结果和轨迹间构建时空相似性,以弥补匹配空间中由于运动估计产生的偏差,实现更好的跨帧几何一致性。
13、s22、检测框的低分框与卡尔曼滤波预测的跟踪框进行d-iou匹配算法的匹配,将低分框纳入跟踪过程以提高整体跟踪的完整性。
14、进一步地,所述s21步骤包括以下步骤:
15、s211、在图3的情况下,计算出边界框a的值为w2*h2,边界框b的值为w1*h1。
16、s212、在保持两个边界框中心点不变的情况下,分别将他们按照一定的比例进行扩展,即为图中的实线部分。并计算出扩展后的边界框c的值为dw2*dh2,边界框d的值为dw1*dh1。
17、进一步地,所述s211步骤包括以下步骤:
18、s2111、对于传统的iou匹配方法,仅在重叠的检测结果和轨迹之间形成时空相似性,计算为如下的形式:
19、
20、其中,a、b分别代表两个原始框,分母由a、b两个框之间的并集组成,分子由两个框之间的交集组成,iou的值由两个框之间的比值得到。在计算两个框之间的iou值后,通过匈牙利算法根据iou的值完成最佳匹配。
21、进一步地,所述s212步骤包括以下步骤:
22、s2121、d-iou算法在原始框的基础上引入一个比例性的扩展区域,为原始不重叠的检测和轨迹构建时空相似性。由于扩展区域与原始检测和轨迹成正比,d-iou不会改变他们的位置中心。计算为如下的形式:
23、
24、其中,c、d分别代表基于a、b两个原始框扩展之后的两个扩展框,分母由两个框c、d之间的并集组成,分子由两个扩展之间的交集组成,d-iou的值由两者之间比值得到。
25、s2122、扩展后的边界框的宽为dw1,dw2,高为dh1,dh2,此时扩展中心与原始坐标共享。则计算扩展比例系数α,β为:
26、
27、其中,α,β表示扩展比例系数,dw1,dw2表示扩展后的宽度,w1,w2表示原始框的宽度,dh1,dh2表示扩展后的高度,h1,h2表示原始框的高度。假设原始匹配表示为:
28、a=(x,y,w,h) (5)
29、其中,x,y分别表示边界框的左上角坐标,w,h分别表示边界框的高和宽,根据扩展区域比例参数α,β,计算出扩展区域为:
30、
31、其中,σ∈{α,β},为本发明针对参数α和β的选取,采用了网格搜索的策略,在-0.1-0.2之间搜索参数α和β的组合,组合种类是有限的,通过网格搜索获得最佳参数α和β的值。
32、进一步地,所述s3步骤包括以下步骤:
33、s31、tlfmodel通过充分利用tracklets之间的全局信息进行数据关联,算法采用与外观无关联的链接模型,仅依赖于时空信息来预测多个轨迹是否属于同一个id。
34、s32、在该过程中,算法遍历整个轨迹集合,每次选取多个轨迹进行处理,每个轨迹都必须满足以下时空标准才能被考虑进行关联预测:
35、tx<dist(i,j)<ty (7)
36、ts>diss(i,j) (8)
37、其中,dist(i,j)表示轨迹之间的时间间隔,diss(i,j)表示轨迹之间的空间距离,tx表示时间阈值的最小值,ty表示时间阈值的最大值;ts表示空间阈值的最大值。
38、s33、通过匈牙利算法的最优分配,满足上述时空标准的轨迹被关联在一起,将行人的短轨迹关联为完整的长轨迹。
39、进一步地,所述s32步骤包括以下步骤:
40、s321、n个轨迹t1,t2,…,tn-1,tn输入到模型中。其中,轨迹的信息可以表示为fi*代表第i帧的某个轨迹,(xi*,yi*)表示第i帧中某个目标框的位置,默认情况下,n的值设为30。
41、s322、对于少于30帧的短轨迹tm,使用0进行填充。
42、s323、包含cnn结构的时间块来对轨迹进行特征提取,时间模块使用7×7大小的卷积核进行特征的初步提取和时间关联特征的处理。经过激活函数激活后,得到处理后的时间块特征。
43、s324、结果映射并融合到具有cnn结构的融合块中,以整合不同维度信息。融合模块由3×3大小的卷积核、平均池化层和全连接层组成。
44、s325、整合不同的特征信息,即f、x和y,将这些tracklets的特征进行池化、压缩和连接。然后,将得到的多个特征层利用cat(·)进行拼接操作,整合成一个包含丰富时空信息的特征向量。
45、s326、通过多层感知机来预测关联的置信度分数,并得到最终的输出结果。在整个过程中,各个模块分支的权重是独立的。通过以上流程,将全局链接问题转化为一个线性分配任务,并得到预估的结果。
46、s327、在训练过程中,将关联任务表述为一个二元分类任务,利用二元交叉熵损失对其进行计算:
47、
48、其中,ci∈[0,1]为样本对n的预测关联概率,oi∈{0,1}表示基本真值。在此关联过程中,过滤掉不合理的带有时空约束的轨迹对。然后,将全局链路求解为具有预测连通性评分的线性分配任务。
49、进一步地,所述s4步骤包括以下步骤:
50、s41、输出的轨迹集送入到mari中进行处理。
51、s42、mari通过构造一组弱的学习数,并把多颗决策树的结果累加起来作为最终的预测输出,通过自适应的逼近基础真值的轨迹,可以实现精度和效率之间的良好权衡,最终的到跟踪目标的信息。
52、进一步地,所述s42步骤包括以下步骤:
53、s421、mari构造了一组弱的学习数,并把多颗决策树的结果累加起来作为最终的预测输出,自适应逼近残差减少方向的地面真值轨迹。基于插值理论,mari的第i帧轨迹的模型如下:
54、
55、x代表每一帧,yx代表对应于x帧的位置坐标变量。ε(i)代表高斯噪声,服从n(0,σ2)分布。
56、s422、将轨迹(ti,yi)1n输入到(12)的公式中,通过残差递归最终得到重连的轨迹。
57、
58、其中,γi为拟合回归数值,ri为终端区,l为可微损失函数。采用加法模型和前向分步算法,实现对地面真值的迭代优化。利用mari可以解决跟踪噪声抖动问题,同时在非线性运动场景下具有更高的精度和鲁棒性。
59、与现有技术相比,本发明的有益效果为:
60、1、本发明提出了一种针对动态场景和复杂环境的跟踪算法,具有良好的跟踪效果。首先,本发明设计了动态场景跟踪器dstrack,增强了在复杂、多样和人群密集的动态场景中对行人的跟踪能力。
61、2、为了解决类似目标干扰引起的跟踪问题,提出了tlfmodel模型,通过关联满足一定时空距离的轨迹,将短行人轨迹转变为完整的长轨迹,从而提高了轨迹的完整性和连续性。
62、3、为了解决快速移动目标的跟踪问题,设计了d-iou匹配算法,通过扩展匹配空间,构建原始非重叠检测结果与轨迹之间的时空相似性,以补偿由于运动估计导致的匹配偏差,从而在跨帧几何一致性方面取得了更好的效果。
63、4、为了解决目标遮挡和环境噪声干扰造成的轨迹中断和碎片化问题,设计了mari算法,通过积累预测结果并自适应地逼近基础真值轨迹,重新连接轨迹碎片,从而提高了轨迹的连续性和完整性。通过上述创新,本发明成功识别并准确跟踪动态场景中的行人目标。
本文地址:https://www.jishuxx.com/zhuanli/20241204/342009.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。