多模态问答方法、装置、电子设备及计算机可读存储介质与流程
- 国知局
- 2024-12-06 12:36:04
本技术实施例涉及但不限于金融科技,尤其涉及一种多模态问答方法、装置、电子设备及计算机可读存储介质。
背景技术:
1、随着社会经济的不断发展,科技的不断进步,人们的生活水平不断提高;在金融行业中,智能化的问答系统已经越来越多地应用到人们的日常生活当中;然而,目前的智能问答系统一般都是基于文本类型进行单模态的回答,即给定一段文本内容,根据用户的问题,从文本内容中寻找答案;但是这种问答方式存在着局限性,无法对更加复杂的模态类型进行回答,所能够解答的问题也存在着局限性,从而给用户带来了不良好的使用体验。
技术实现思路
1、以下是对本文详细描述的主题的概述。本概述并非是为了限制权利要求的保护范围。
2、为了解决上述背景技术中提到的问题,本技术实施例提供了一种多模态问答方法、装置、电子设备及计算机可读存储介质,突破解答的问题的局限性,给用户带来了更加良好的使用体验。
3、第一方面,本技术实施例提供了一种多模态问答方法,包括:
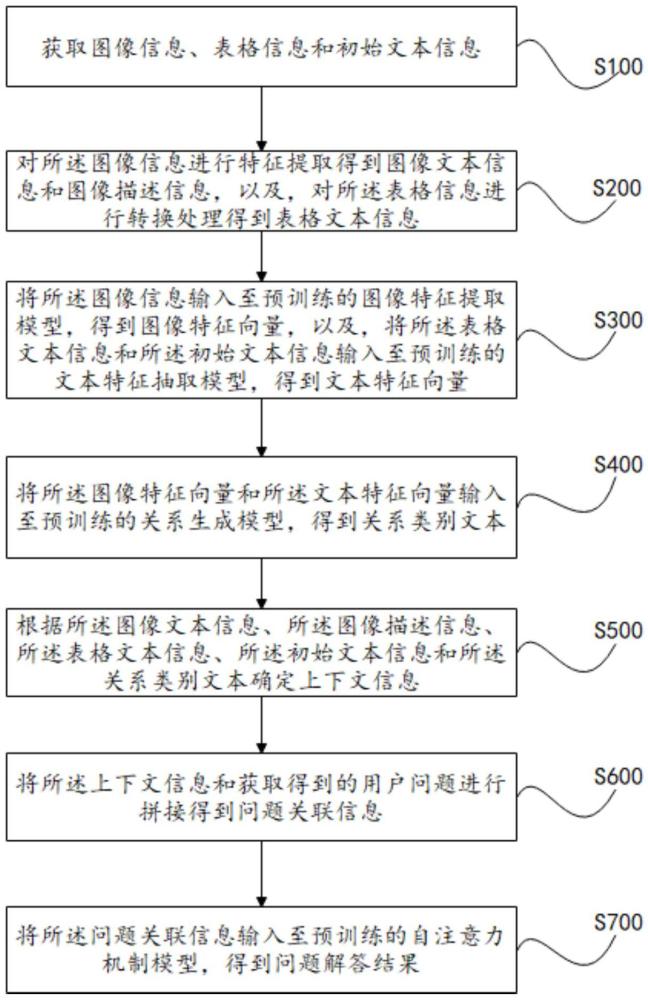
4、获取图像信息、表格信息和初始文本信息;
5、对所述图像信息进行特征提取得到图像文本信息和图像描述信息,以及,对所述表格信息进行转换处理得到表格文本信息;
6、将所述图像信息输入至预训练的图像特征提取模型,得到图像特征向量,以及,将所述表格文本信息和所述初始文本信息输入至预训练的文本特征抽取模型,得到文本特征向量;
7、将所述图像特征向量和所述文本特征向量输入至预训练的关系生成模型,得到关系类别文本;
8、根据所述图像文本信息、所述图像描述信息、所述表格文本信息、所述初始文本信息和所述关系类别文本确定上下文信息;
9、将所述上下文信息和获取得到的用户问题进行拼接得到问题关联信息;
10、将所述问题关联信息输入至预训练的自注意力机制模型,得到问题解答结果。
11、根据本技术的一些实施例,所述对所述图像信息进行特征提取得到图像文本信息和图像描述信息,包括:
12、将所述图像信息输入至预训练的光学字符识别模型,得到所述图像文本信息;
13、将所述图像信息输入至预训练的双语视觉语言模型进行图片特征编码,得到图片编码信息;
14、将所述图片编码信息输入至预训练的多头注意力机制模型的文本解码器,得到所述图像描述信息。
15、根据本技术的一些实施例,所述将所述图片编码信息输入至预训练的多头注意力机制模型的文本解码器,得到所述图像描述信息,包括:
16、根据所述图片编码信息和所述多头注意力机制模型确定多个候选词;
17、在所述候选词的数量大于预设的采样数值的情况下,将多个所述候选词均作为目标候选词;
18、在所述目标候选词对应的候选概率大于预设的采样概率的情况下,根据所述目标候选词确定所述图像描述信息。
19、根据本技术的一些实施例,所述将所述图像信息输入至预训练的光学字符识别模型,得到所述图像文本信息,包括:
20、根据所述光学字符识别模型对所述图像信息进行字符识别处理得到多个初始识别字符;
21、将多个所述初始识别字符和预设的识别数据库进行匹配处理,得到所述图像文本信息。
22、根据本技术的一些实施例,所述对所述表格信息进行转换处理得到表格文本信息,包括:
23、从所述表格信息确定行列数量、表头名称和表格位置信息;
24、根据所述行列数量、所述表头名称和所述表格位置信息,对所述表格信息进行格式变换处理,得到所述表格文本信息。
25、根据本技术的一些实施例,所述将所述问题关联信息输入至预训练的自注意力机制模型,得到问题解答结果后,所述方法还包括:
26、根据所述用户问题确定问题回答结果标识;
27、根据所述问题解答结果和所述问题回答结果标识确定回答损失值;
28、根据所述回答损失值对所述自注意力机制模型进行参数调整处理。
29、根据本技术的一些实施例,所述根据所述图像文本信息、所述图像描述信息、所述表格文本信息、所述初始文本信息和所述关系类别文本确定上下文信息,包括:
30、根据所述图像文本信息和所述图像描述信息确定图像特征信息;
31、将所述图像特征信息、所述表格文本信息、所述初始文本信息和所述关系类别文本进行组合处理,得到所述上下文信息。
32、第二方面,本技术实施例还提供了一种多模态问答装置,所述装置包括:
33、第一处理模块,用于获取图像信息、表格信息和初始文本信息;
34、第二处理模块,用于对所述图像信息进行特征提取得到图像文本信息和图像描述信息,以及,对所述表格信息进行转换处理得到表格文本信息;
35、第三处理模块,用于将所述图像信息输入至预训练的图像特征提取模型,得到图像特征向量,以及,将所述表格文本信息和所述初始文本信息输入至预训练的文本特征抽取模型,得到文本特征向量;
36、第四处理模块,用于将所述图像特征向量和所述文本特征向量输入至预训练的关系生成模型,得到关系类别文本;
37、第五处理模块,用于根据所述图像文本信息、所述图像描述信息、所述表格文本信息、所述初始文本信息和所述关系类别文本确定上下文信息;
38、第六处理模块,用于将所述上下文信息和获取得到的用户问题进行拼接得到问题关联信息;
39、第七处理模块,用于将所述问题关联信息输入至预训练的自注意力机制模型,得到问题解答结果。
40、第三方面,本技术实施例还提供了一种电子设备,包括:存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上第一方面所述的多模态问答方法。
41、第四方面,本技术实施例还提供了一种计算机可读存储介质,存储有计算机可执行指令,所述计算机可执行指令用于执行如上第一方面所述的多模态问答方法。
42、根据本技术提供的实施例的多模态问答方法,至少具有如下有益效果:在进行多模态问答的过程中,首先获取图像信息、表格信息和初始文本信息,接着对图像信息进行特征提取就可以得到图像文本信息和图像描述信息,以及对表格信息进行转换处理就可以得到表格文本信息;然后将图像信息输入到预训练的图像特征提取模型中,就可以得到图像特征向量;接着将表格文本信息和初始文本信息输入到预训练的文本特征抽取模型中,就可以得到文本特征向量;然后将图像特征向量和文本特征向量输入到预训练的关系生成模型中,就可以得到关系类别文本;接着根据图像文本信息、图像描述信息、表格文本信息、初始文本信息和关系类别文本就可以确定上下文信息;接着将上下文信息和获取得到的用户问题进行拼接处理就可以得到问题关联信息;最后将问题关联信息输入到预训练的自注意力机制模型就可以得到问题解答结果。通过上述技术方案,将图像信息、表格信息和初始文本信息三种不同模态的数据信息进行融合,以便于对用户所咨询的问题进行多模态回答,突破解答的问题的局限性,给用户带来了更加良好的使用体验。
本文地址:https://www.jishuxx.com/zhuanli/20241204/342241.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表