一种电渣重熔高温合金钛含量预报方法、系统及存储介质
- 国知局
- 2024-12-06 12:47:17
本发明属于高温合金生产,具体为一种电渣重熔高温合金钛含量预报方法、系统及存储介质。
背景技术:
1、高温合金是一类能够在600 ℃以上高温及一定应力条件下长期工作的特种金属材料,具有优异的高温强度、抗氧化和抗热腐蚀性能、良好的抗疲劳强度及断裂韧性等综合机械性能。高温合金广泛应用于航空发动机、燃气轮机、核电站、石油化工设备等关键部件中。特别是在航空发动机领域,高温合金已成为热端部件(如涡轮叶片、涡轮盘、燃烧室等)的首选材料,其用量占比高达发动机总量的40%~60%。在能源领域,高温合金用于核电站蒸汽发生器、反应堆组件等;在石油化工领域,用于催化剂、反应器、管道、阀门等高温高压设备。
2、常见牌号有gh4169、gh4738、gh145、inconel825以及a286等。这些高温合金均含有大量γ'-ni3(ti,al)强化相形成元素钛和铝,以提高合金的高温强度和蠕变性能。钛是增强合金抗热腐蚀性、提高表层组织稳定性的关键元素,并且钛可以稳定奥氏体组织,与基体中的碳和氮结合形成ti(c,n),增强合金的耐晶间腐蚀能力。然而,高温合金电渣重熔冶炼过程中普遍存在由于炉渣与金属液反应造成的钛元素严重烧损,导致钛含量在电渣锭轴向和高度方向极其不均匀,这严重恶化了合金机械性能及抗腐蚀性能。电渣重熔是高温合金生产过程中不可或缺的一步。因此,高温合金电渣锭钛含量的预报对生产高端高温合金非常重要。
3、电渣重熔过程因其复杂的多相耦合反应、高维变量、大规模性、强耦合、非线性及显著滞后等特点,形成了典型的“黑箱”操作环境。在电渣重熔生产中,传统的成分预测方法面临材料设备成本高、实验环境危险及钛含量定量预测局限等挑战。现有的电渣锭成分预报模型主要为基于离子和分子共存理论(imct)的热力学模型和基于双膜理论的动力学模型。尽管少数模型可以预报某些合金种类的成分,但是这些模型仍然存在明显的缺陷。比如基于双膜理论的动力学模型建立需要的几何参数(电极端部金属液膜的表面积和体积参数等)、热力学参数(渣池和金属熔池的温度分布等)和动力学参数(金属和炉渣组元的传质系数)等存在大量简化和假设,这导致现有模型准确性较低、模型泛化能力差,适用范围有限,无法为高温合金钛含量控制提供精确的指导。
技术实现思路
1、为解决现有技术存在的问题,本发明目的在于提供一种基于机器学习融合冶金机理的电渣重熔高温合金钛含量预报方法、系统及存储介质,可以准确地预报高温合金电渣锭的钛含量。
2、为实现上述目的,本发明的技术方案是:
3、根据本发明技术方案的第一方面,提供一种电渣重熔高温合金钛含量预报方法,包含如下步骤:
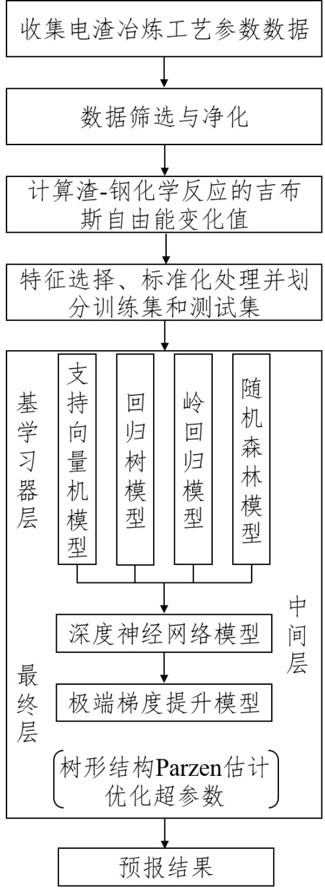
4、(1)收集已有的高温合金电渣重熔工业生产过程的冶炼数据,并对数据集进行筛选与净化;
5、(2)根据每一炉次高温合金电极成分和渣成分计算渣-钢化学反应的吉布斯自由能变化,吉布斯自由能变化数据与冶炼工艺参数数据共同作为模型的输入变量,电渣锭钛含量为模型的输出变量;然后采用斯皮尔曼相关系数法结合互信息法对输入变量进行特征选择,剔除对电渣锭钛含量没有影响的特征;
6、(3)经过特征选择后的吉布斯自由能变化数据与冶炼工艺参数数据进行标准化处理,并将数据集随机划分为训练集和测试集。
7、(4)构建基于渣-钢化学反应和冶炼工艺参数数据的多层堆叠泛化机器学习模型,并运用树形结构parzen估计(核密度估计)算法对各层机器学习算法进行调优,以实现电渣重熔高温合金钛含量预测模型的优化。
8、(5)采用优化的电渣重熔高温合金钛含量预报模型对不同冶炼条件下的电渣锭钛含量进行预测。
9、这里,parzen估计是一种非参数估计方法,用于估计概率密度函数。这种方法不需要假设概率密度函数的特定形式,而是直接从样本数据中推断出概率密度函数。parzen估计的核心思想是使用一个窗函数(也称为核函数)来衡量每个样本点对估计点的贡献,并通过所有样本点的加权平均来估计任意一点的概率密度。
10、进一步地,所述步骤(1)中,对数据集进行筛选与净化包括去除不相关或无效的数据。
11、进一步地,所述步骤(2)中,根据每一炉次高温合金电极成分和渣成分计算渣-钢化学反应的吉布斯自由能变化值,化学反应的表达式如式(1)~(6)所示。
12、 (1)
13、 (2)
14、 (3)
15、 (4)
16、 (5)
17、 (6)
18、其中,和分别为炉渣中组元活度和钢液中组元的活度系数,t为温度。
19、进一步地,所述步骤(2)中,作为模型输入变量的冶炼工艺参数数据包括熔炼电压、熔炼电流、电渣炉结晶器进水温度、结晶器出水温度、保护气氛氩气流量、电极成分、渣成分、渣量、脱氧剂加入量和锭重。
20、进一步地,所述步骤(2)中,采用斯皮尔曼相关系数法计算每个输入变量与输出变量之间的线性相关性,如式(7)所示:
21、 (7)
22、其中,为斯皮尔曼相关系数,为两个变量之前的等级差,为样本个数;
23、结合互信息法计算每个输入变量与输出变量之间的非线性关系,两者进行互补筛选,如式(8)所示:
24、 (8)
25、其中,和是两个离散变量,取值分别为和;是两个变量间的互信息值,和分别是和的边缘概率分布,是和的联合概率分布。
26、进一步地,所述步骤(3)中,标准化处理后的数据更接近于均值为0、标准差为1的分布,具体表达式如(9);随机选取75~85%的数据作为训练集,15~25%的数据作为测试集。
27、 (9)
28、其中,是原始特征值,是数据的均值,是原始数据的标准差,是标准化后的特征值。
29、进一步地,所述步骤(4)中,构建三层堆叠泛化机器学习模型,第一层为基学习器层,包括支持向量机模型、岭回归模型、回归树模型和随机森林模型,中间层使用深度神经网络作为元学习器;最终层采用极端梯度提升模型;三层堆叠泛化模型中所采用的学习器均是基于监督学习的回归分析算法。
30、进一步地,所述步骤(4)中,多层堆叠泛化模型中的各个层次或模块之间相互协作,通过融合不同层次的信息来做出更准确的决策。多层堆叠泛化模型中的每一层都具有正则化效应,防止模型过度拟合训练数据。同时通过在不同层次上引入随机性或噪声,进一步提高模型的泛化能力。
31、进一步地,所述步骤(4)中,开始三层堆叠泛化机器学习模型训练时,原始的训练集用于训练第一层的4个基学习器,并通过交叉验证来评估性能;第一层在训练集上的预测结果作为新特征,与最初的目标值一起构成中间层的训练集,使用这些新特征来训练中间层的深度神经网络模型;中间层的预测结果再次作为新特征,与最初的目标值一起构成最终层的训练集,使用这些新特征来训练最终层的极端梯度提升模型;训练完成的三层堆叠泛化模型输出最终的高温合金电渣锭钛含量预报结果。
32、进一步地,运用树形结构parzen估计算法对各层机器学习算法进行调优,具体为:
33、初始化:有超参数空间x和目标函数,其中;对于给定的目标函数值,定义超参数的条件概率分布为。
34、条件概率分布:在树形结构parzen估计算法中,特别关注和两种条件概率分布,其中表示目标函数值低于阈值,表示目标函数值高于阈值。
35、parzen窗估计:使用parzen窗估计条件概率分布,对于窗函数,样本点对位置的密度贡献为。对于的组和的组,估计其条件概率分别如表达式(10)和(11)所示。
36、 (10)
37、 (11)
38、其中代表目标函数值低于阈值的组的样本数,代表目标函数值高于阈值的组的样本数,为的目标函数值。
39、选择下一个评估点:树形结构parzen估计算法通过最大化表达式(12)的比值选择下一个评估点。
40、 (12)
41、树形结构:树形结构parzen估计算法中的超参数空间x被递归地划分为多个子空间,每个子空间对应树形结构中的一个节点。每个节点都存储了属于该节点的样本点,并用于估计该节点内的条件概率分布。当选择下一个评估点时,从根节点开始,递归地向下遍历树,直到达到预设的迭代次数。每个节点上都使用parzen窗估计和比值最大化方法来选择下一个评估点。
42、输出最优超参数:迭代结束后,输出具有最佳目标函数值的超参数作为最优超参数,实现调优。
43、进一步地,所述步骤(4)中,用于树形结构parzen估计算法调优支持向量机模型的超参数包括模型的核函数、正则化参数、松弛变量和核函数参数;用树形结构parzen估计算法调优岭回归模型的超参数包括正则化强度参数、拟合截距项、最大迭代次数、是否标准化特征和正则化方法;用树形结构parzen估计算法调优回归树模型的超参数包括树的最大深度、最小样本分割数、最小样本叶节点数、最大特征数、分裂标准、剪枝参数和随机状态;用树形结构parzen估计算法调优随机森林模型的超参数包括树的数量、树的最大深度、最小样本分割数、最小叶子节点样本数、特征的最大数量、准则、样本采样比例、袋外得分和随机种子。
44、进一步地,所述步骤(4)中,用于树形结构parzen估计算法调优深度神经网络模型的超参数包括学习率、批量大小、隐藏层数量与大小、正则化参数、激活函数、优化器、学习率调度器、dropout比率和初始权重分布;用于树形结构parzen估计算法调优极端梯度提升模型的超参数包括学习率、估计器数量、树的最大深度、最小子节点权重、列抽样比例、行抽样比例、正则化参数、分裂所需的最小损失减少、基础分数、目标函数、评估器类型、树方法、特征采样方法、最大增量步长和随机种子。
45、根据本发明技术方案的第二方面,提供一种电渣重熔高温合金钛含量预报方法系统,所述系统包括:处理器和用于存储可执行指令的存储器;所述处理器被配置为执行所述可执行指令,以执行如以上任一方面所述的电渣重熔高温合金钛含量预报方法。
46、根据本发明技术方案的第三方面,提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如以上任一方面所述的电渣重熔高温合金钛含量预报方法。
47、本发明的有益效果如下:
48、本发明提出一种基于机器学习融合冶金机理的电渣重熔高温合金钛含量预报方法。
49、(1)收集已有的高温合金电渣重熔工业生产过程的冶炼数据;根据每一炉次高温合金电极成分和渣成分计算渣-钢化学反应的吉布斯自由能变化值。这一步骤至关重要,吉布斯自由能变化值能够反映化学反应的趋势和限度,从而为模型提供必须的物理化学参数,确保融合冶金机理的机器学习模型对钛含量预报的准确性。渣-钢化学反应的吉布斯自由能变化数值与冶炼工艺参数数据共同作为模型的输入变量,电渣锭钛含量为模型的输出变量。
50、(2)采用斯皮尔曼相关系数法结合互信息法对输入变量进行特征选择。这一步骤有效地剔除了对电渣锭钛含量预测无关紧要的特征,从而简化了模型结构,降低了计算复杂度,并避免了过拟合的风险,保证了模型的预测精确度。斯皮尔曼相关系数法能够捕捉到变量间的线性关系,而互信息法则能够揭示出更复杂的非线性依赖关系,两者的结合使用确保了特征选择的全面性和准确性。
51、(3)经过特征选择后的渣-钢化学反应吉布斯自由能变化数据与冶炼工艺参数数据进行标准化处理,并将数据集随机划分为训练集和测试集。标准化处理可以避免输入变量的不同量纲和数量级差异降低模型的收敛速度和预测精度,并使模型具有一定的鲁棒性。通过标准化处理,将渣-钢化学反应吉布斯自由能变化数据与冶炼工艺参数数据转换为无量纲的纯数值,使得不同量纲的数据在同一尺度上进行比较和运算。
52、(4)构建基于渣-钢化学反应和冶炼工艺参数数据的三层堆叠泛化机器学习模型,并运用树形结构parzen估计算法对各层机器学习算法进行调优。三层堆叠泛化机器学习模型充分考虑了数据的层次性和复杂性,通过逐层提取与融合特征,从而做出精确的决策。模型中的每一层都具有正则化效应,防止模型过拟合训练数据。同时在不同层次上引入随机性或噪声,进一步提高了模型的泛化能力。优化的高温合金钛含量预报模型可以精确预报不同种类高温合金、不同冶炼工艺参数的电渣锭的钛含量,且模型泛化能力强,预测性能稳定。三层堆叠泛化模型的预测精度远高于现有的用于电渣锭成分预报的基于离子和分子共存理论(imct)的热力学模型和基于双膜理论的动力学模型。三层堆叠泛化模型能够从大量电渣冶炼工业数据中自动学习特征,减少了人工干预的时间和成本,显著提高了自动化水平。三层堆叠泛化模型能够有效地管理大规模和高维工业数据、具备适应复杂的非线性关系并从数据中揭示隐藏的模式和关联规则的能力。三层堆叠泛化模型具有自我优化和调整的能力,通过不断接收新数据的反馈,能够使模型更加准确和鲁棒。在电渣锭钛含量的预测过程中,随着数据积累和模型的持续训练,三层堆叠泛化模型的预测精确度持续提升。
53、(5)吉布斯自由能变化值为模型提供了坚实的物理化学基础,斯皮尔曼相关系数法与互信息法的结合确保了特征选择的精准性和有效性,三层堆叠泛化机器学习模型与树形结构parzen估计算法的融合,实现了对高温合金电渣重熔过程中钛含量的高精度预测。这四者之间的紧密结合和相互协作,共同构成了本发明的核心优势。
本文地址:https://www.jishuxx.com/zhuanli/20241204/342773.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表