基于决策树的地理空间数据分级评价方法、设备及介质与流程
- 国知局
- 2024-12-06 12:52:39
本发明涉及数据处理及信息安全,具体地说是一种基于决策树的地理空间数据分级评价方法、设备及介质。
背景技术:
1、随着地理信息科学的快速发展,地理空间数据已成为各行业决策支持、科研分析的重要基础。然而,地理空间数据种类繁多、来源复杂,数据的安全性和共享性成为制约其有效应用的关键问题。当前数据分级管理思路普遍是基于大数据场景下的数据特征,认为数据具有不同维度的安全属性,进而构建数据安全风险等级、影响程度等指标进行数据安全评价。现实中行业内多是基于业务信息以及数据敏感级别的定义,构建基于数据敏感规则来指导数据的分类分级,或基于专家评分规则定义数据分级标准,但这些分级策略往往缺乏可靠衡量指标、分级评价过多依赖主观经验和判断,且无法适应评价场景的变化发展。传统的地理空间数据分级方法在还存在较多主观判断,往往缺乏对元数据信息、数据分级管理规则的深入挖掘和利用,导致数据分级不准确、管理效率低下,所以需要为地理空间数据构建专门的安全分级模型,并采取相应的分级保护管理措施。
2、现有技术存在的问题如下:
3、①地理空间数据元数据探查识别能力较弱,地理空间数据元数据是数据分级的基础,涉及对数据中蕴含的空间信息和数据信息的结构化描述,比如空间位置、属性数据、空间拓扑关系、时间序列信息等,这些信息需要多层次探查,但是目前针对地理空间数据元数据的识别和利用率较低;
4、②信息安全和测绘地理信息行业关于地理空间数据的分级管理有较多规定要求,这些规定从不同角度对地理空间数据的分级管理对象、分级方法、影响评价提供了策略和依据,但是目前对这些策略办法实施多依赖主观经验,耗费大量的人力和时间成本;
5、③随着测绘地理信息行业的快速发展,地理空间数据以从小数据单模态向大数据多模态转变。与此同时,地理空间数据的数据安全级别评价传统专家评价方法发挥了重要作用;然而,地理空间数据安全等级评价过程中的评价结果信息作为重要的专家经验却未用在数据安全评价过程中,而海量数据的增长对数据安全评价也提出来更高要求,需要充分利用已有专家评价经验辅助提升数据安全评价的工作效率。
6、故如何实现有效的地理空间数据管理及使用中数据有效分级,确保数据安全,提升数据使用效率,同时实现安全性评估溯源有据可查是目前亟待解决的技术问题。
技术实现思路
1、本发明的技术任务是提供一种基于决策树的地理空间数据分级评价方法、设备及介质,来解决如何实现有效的地理空间数据管理及使用中数据有效分级,确保数据安全,提升数据使用效率,同时实现安全性评估溯源有据可查的问题。
2、本发明的技术任务是按以下方式实现的,一种基于决策树的地理空间数据分级评价方法,该方法具体如下:
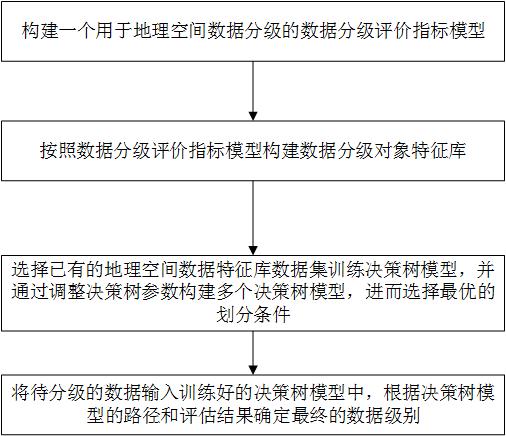
3、构建一个用于地理空间数据分级的数据分级评价指标模型:数据分级评价指标模型基于行业规范和专家知识构建,即作为地理空间数据分级评价知识库;其中,数据分级评价指标模型包括标识指标、评价指标及决策指标;
4、按照数据分级评价指标模型构建数据分级对象特征库:通过基于地理空间数据分级对象采样构建的地理空间数据特征库,对数据源进行确认并指定采集规则,进而进行元数据采样,获取分级对象的数据分级标识特征数据;
5、选择已有的地理空间数据特征库数据集训练决策树模型,并通过调整决策树参数构建多个决策树模型,进而选择最优的划分条件;其中,决策树参数包括最大深度和最小样本数;决策树算法包括id3、c4.5或cart;
6、将待分级的数据输入训练好的决策树模型中,根据决策树模型的路径和评估结果确定最终的数据级别。
7、作为优选,标识指标由若干空间元数据指标构成;标识指标包括若干地理空间数据的元数据内容或规范化数据集中数据属性指标;标识指标通过定量或定性描述定义,并按照类型划分为数据集及数据元两种类型;
8、其中,标识指标来自数据领域、数据群体、数据区域、数据精度、数据规模、数据深度、覆盖度及重要性维度;标识指标来源于数据集数据元信息,由地理空间数据集对象和数据生产单位按照行业规范制作和维护。
9、作为优选,评价指标由若干数据安全评价指标构成,评价指标包括数据安全评价指标;评价指标由专家根据行业规范、标准及行业经验制定,通过量化方式对数据对象进行安全因素进行评估;
10、评价指标设计影响对象,评价指标的计算由一个或若干标识指标根据计算规则获取,或引入专家经验辅助确定。
11、作为优选,决策指标是数据分级目标变量,决策指标的评价等级按照核心数据、重要数据及一般数据的自定义级别定义数据分级标准。
12、作为优选,构建地理空间数据分级对象特征库具体如下:
13、确认地理空间数据数据源:数据源选择存储地理空间数据的数据库和大数据平台;其中,数据库包括以oraclesde及postgis为代表地理空间数据库和以mongodb及minio为代表的文档数据库;大数据平台包括以hbase及spark为代表的大数据平台;
14、制定数据源采集规则:包括数据集元数据采集规则和数据集数据元采集规则;其中,数据集元数据采集规则是根据数据源类型构建相应数据源标识指标、评价指标与数据源中数据集字段的映射关系及转移规则,实现统一的地理空间数据源数据描述识别与转义,将数据集的元数据及数据源信息转换为数据分级评价指标模型中的标识指标标签值;数据集数据元规则是通过设置数据识别规则,对数据记录中存在的敏感信息进行识别,辅助甄别数据敏感性和数据记录标识,比如敏感字符、敏感数值等;数据识别规则通过构建敏感字符信息库进行动态维护,对敏感字符和数据分级级别进行创建、修改及删除维护;
15、元数据采样:根据数据源类型,选择合适的数据源连接方式,与数据源建立连接,对选取的数据集按照既定的数据源采样规则进行抽取,数据源采样规则信息包括元数据采样、数据元采样以及是否全量采样;其中,数据元采样选择一个或多个数据字段匹配定义采集识别规则;数据源连接方式包括采用odbc、mdbc及数据库驱动;所属数据源的连接信息包括ip地址、端口号、账户号和/或访问方式的匹配项目;
16、分级对象特征库创建:执行数据库数据集元数据采样规则获取分级对象的数据分级识别特征数据;其中,特征数据包括数据分级评价指标模型各项标识指标和评价指标。
17、更优地,构建决策树模型具体如下:
18、确定决策树的输入节点:决策树的输入节点对应于影响数据分级的关键要素,在评数据分级评价指标模型中仅有标识指标作为输入节点;标识指标作为决策树的根节点或初始分支节点;
19、构建决策树的分支结构:根据输入节点的不同取值,将决策树进一步分支;具体为:数据领域细分为工业数据、电信数据、金融数据;数据规模依据数据存储量及群体规模进行划分;每个分支代表一个特定的要素取值范围或类别;
20、设置决策树的中间节点:在决策树的中间层,加入基于数据影响分析的节点,数据分级评价指标模型中标识指标、评价指标均作为中间节点;中间节点用于评估数据一旦遭到泄露、篡改、损毁或者非法获取、非法使用、非法共享时,可能影响的对象和影响程度(如特别严重危害、严重危害、一般危害);其中,评价指标中涉及影响程度为最高级别可结束;
21、定义决策树的输出节点:输出节点对应于数据分级的最终级别,如核心数据、重要数据、一般数据等;数据分级的最终级别将根据数据在决策树中经过的分支路径和中间节点的评估结果来确定;
22、训练和调整决策树:使用已知分级结果的数据集训练决策树,确保决策树的准确性和可靠性;训练过程中,调整分支阈值及剪枝参数,优化决策树的结构和性能;
23、决策树划分优选策略:决策树节点划分评价方法有基于信息增益的划分策略(如id3算法)、基于增益率的划分策略(如c4.5算法)、基于基尼不纯度的划分策略(如cart算法)和其他启发式划分策略。
24、更优地,基于增益率的划分策略用于在决策树模型构建过程中选择最佳的分裂属性;使用已知分级结果的数据集为样本,具体如下:
25、构建决策树进行选择时,对决策树的各节点划分条件进行评价;
26、输入计算:由决策树的用于学习的数据集合中包含的各数据的特定的数值属性值构成的数值属性值向量、由各数据的标签值构成的标签值向量及表示各数据的至各节点的分组的组信息向量;其中,数值属性值向量是有数据分级评价指标模型数据集中的标识指标及评价指标组成,数值属性值用于计算各个节点划分条件的优劣;标签值向量是有数据分级评价指标模型数据集中的决策指标,即数据分级评价指标模型能够预测或分类的数据分级目标值;组信息向量表示数据中每个样本点在各个节点上所属的分组信息;
27、频度计算:使用数值属性值向量、标签值向量及组信息向量计算属于各组的数据的第1频度、各组中的每个标签值的数据的第2频度、属于根据表示数值属性值和阈值的比较的划分条件对组进行划分而得的划分组的数据的第3频度及划分组中的每个标签值的数据的第4频度;
28、评价计算:根据第1频度、第2频度、第3频度及第4频度使用增益率计算评价值,评价值用于评价划分条件;
29、依据获取的最优划分条件作为数据分级评价指标模型。
30、更优地,根据第1频度、第2频度、第3频度及第4频度使用增益率计算评价值具体如下:
31、计算信息熵(entropy):信息熵用于度量数据集的混乱程度;其中,对于一个数据集,数据集的信息熵的计算公式如下:
32、;
33、其中,用于计算数据集d的信息熵,通过各个类别所占比例的对数运算求和,再取负值得到; 表示数据集d的信息熵,用于度量数据集的混乱程度;表示样本集合中第i个类别所占比例;n表示类别的总数;
34、计算信息增益(gain):信息增益表示通过按照任一个属性进行划分后,数据集的信息熵减少的程度;其中,对于属性和数据集,信息增益的计算公式如下:
35、;
36、其中,表示属性对数据集的信息增益,即按照属性进行划分后,数据集的信息熵减少的程度;表示数据集的信息熵,用于度量数据集的混乱程度;表示属性所有可能取值的集合;表示属性对应值为的样本子集;和分别表示子集和整个数据集的样本数;表示子集的信息熵;
37、计算分裂信息(splitinfo):分裂信息用于衡量按照属性进行划分时产生的分支数量以及每个分支所包含的样本数量;计算公式如下:
38、;
39、其中,表示按照属性进行划分时产生的分裂信息,用于衡量分支数量及每个分支包含的样本数量;表示属性所有可能取值的集合;表示属性对应值为的样本子集的数量;表示整个数据集的样本数量;表示属性对应值为的样本子集占整个数据集的比例;表示上述比例的对数运算;
40、计算增益率(gainratio):增益率通过信息增益除以分裂信息得到,用于平衡信息增益和分裂信息的影响;计算公式如下:
41、;
42、其中,表示属性对数据集进行划分后的信息增益,衡量划分后数据集信息熵的减少程度;表示按照属性进行划分时产生的分裂信息,用于衡量划分产生的分支数量及每个分支包含的样本数量;表示用于划分的属性;表示整个数据集;
43、计算评数据分级评价指标模型数据集中的标识指标及评价指标的增益率,比较各划分条件的增益率,选择增益率最大的划分条件作为最优划分条件,提升数据分级纯度又不会导致模型过于负复杂,起到简化模型的作用。
44、一种电子设备,包括:存储器和至少一个处理器;
45、其中,所述存储器上存储有计算机程序;
46、所述至少一个处理器执行所述存储器存储的计算机程序,使得所述至少一个处理器执行如上述的基于决策树的地理空间数据分级评价方法。
47、一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序可被处理器执行以实现如上述的基于决策树的地理空间数据分级评价方法。
48、本发明的基于决策树的地理空间数据分级评价方法、设备及介质具有以下优点:
49、(一)本发明用于对矢量、栅格、三维模型等地理空间数据进行有效的数据安全分级评价,能够有效地对地理空间数据进行科学分级,为数据安全管理和使用提供重要参考,适用于各类需要处理地理空间数据的组织和场景,具有广泛的应用价值;
50、(二)本发明通过构建数据分级评价指标模型,利用标识指标、评价指标和决策指标全面评估数据的安全性和重要性,实现对地理空间数据的科学分级,解决了当前地理空间数据管理和使用中数据分级缺乏评价模型、安全性评估溯源依据不清晰的问题,通过地理空间数据元数据数据分级评价指标模型和基于决策树的评价方法,实现地理空间数据的数据安全自动化分级评价;
51、(三)本发明旨在帮助组织和企业更好地管理和使用地理空间数据,确保数据安全,提升数据使用效率,同时为数据共享、交换和交易提供可靠的分级标准;
52、(四)本发明提升了数据安全性:通过构建数据分级评价指标模型,能够全面评估地理空间数据的安全性和敏感性,从而有助于组织更加精准地制定数据安全策略,防止敏感数据泄露,显著提升了数据的安全性;
53、(五)本发明提高了数据管理效率:通过对地理空间数据进行科学分级,组织可以更有效地管理其数据资源;不同级别的数据可以采取不同的存储、备份和恢复策略,优化资源分配,降低管理成本,提高管理效率;
54、(六)本发明实现了决策支持增强:能够为组织的决策提供有力支持,明确的数据分级有助于组织快速识别关键信息,为战略规划、风险管理等提供准确的数据依据;
55、(七)本发明促进了数据共享与交易:在保护数据安全的前提下,明确的数据分级标准有助于推动数据的共享、交换和交易,不同组织之间可以根据数据级别进行更加公平、透明的数据交换,促进数据资源的合理利用;
56、(八)本发明具有灵活性与可扩展性:采用的决策树算法具有较强的灵活性和可扩展性,能够适应不同规模和组织结构的数据分级需求;同时,通过版本管理功能,可以方便地根据实际需求定制和调整数据分级评价指标模型;
57、(九)本发明通过提供一种科学、高效、灵活的地理空间数据分级评价方法,为组织在数据安全、管理、决策支持以及数据共享与交易等方面带来了显著的有益效果。
本文地址:https://www.jishuxx.com/zhuanli/20241204/342907.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。