一种基于安全梯度分布的合成过采样方法及系统
- 国知局
- 2024-12-06 12:53:52
本发明属于人工智能/数据挖掘技术的不平衡分类领域,尤其涉及一种基于安全梯度分布的合成过采样方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、在金融风险控制方面,二分类的有监督学习任务通常面临着类别不平衡的问题,即金融风险控制方面的测试数据集中一个类别的样本数量往往远远多于另一个类别的样本数量,其中,样本数量多的类别被称为多数类(负类),另一个类别被称为少数类(正类)。以金融风险控制中信贷风控领域违约预测和欺诈交易检测为例,信贷违约预测数据集的类别不平衡特点表现在非违约样本远远多于违约样本,欺诈消费检测数据集的类别不平衡特点表现在正常消费样本数量远远多于欺诈消费样本数量。可见,金融风险控制中的这些任务场景的数据集类别通常是严重不平衡的,而异常样本的精准识别又对场景任务有重要的意义。
3、具体的,有监督机器学习的特点是某个类别的样本数量越多,模型越能学习到样本的模式,即模型对每个类别的识别能力取决于每个类别的样本对模型优化的贡献大小。但在类别不平衡条件下,多数类样本在数量上的绝对优势使其对模型的贡献比较大,导致模型对多数类数据有一个很好的拟合结果;少数类样本则相反,虽然模型整体的识别精度会很高,但少数类样本的识别性能非常低。这种结果与场景任务的目标相互矛盾,而且未能正确识别的少数类样本可能会带来严重的后果。由此,少数类样本数据的过采样技术成为解决类别不平衡问题的首个研究方向,它通过合成一定数量的少数类伪样本来使多数类和少数类的样本数量大致相等,从而均衡他们对模型的贡献。
4、目前的实际应用和学术研究上均有关于解决类别不平衡问题的合成过采样方法研究成果,比如smote及其改进方法:nansmote、enansmote、nldao、wrnd等;基于聚类的合成过采样方法:smote-cof、awtdo等;基于噪声过滤的合成过采样方法:gmf-smote等。可见,现有的工作和研究虽然都针对不平衡数据集的合成过采样方法提出了有效的改进措施,但以上改进方式均是基于特征空间和基于聚类插值的方式进行的改进,这种改进仍然存在对样本的空间分布依赖的问题。另外,高维样本的空间距离是很难度量的,很多情况下高维空间的距离度量是无效的;基于自适应插值的方法过分关注某个样本的合成权重;基于过滤插值的方法将丢失掉本来数量就很少的珍贵的少数类样本,使合成的样本丢失多样性。
5、因此,发明人发现现有的合成过采样方法仍然存在一些技术问题,例如:
6、(1)现有方法在选择根样本、辅助样本和确定采样权重时均需要依赖高维空间距离度量或者样本密度,由于高维距离度量困难,所以这种方法对高维样本十分不适用;而金融风控数据均为高维样本(几十维以上),因此现有方法对金融风控类数据采样所合成的样本质量不佳;
7、(2)现有方法中所合成的伪样本的分布不利于模型对不同类别样本的识别均衡性,使模型易对正类样本过拟合,继而损失负类样本的识别精度,具体表现为f1-score、mcc等指标不高。
技术实现思路
1、为克服上述现有技术的不足,本发明提供了一种基于安全梯度分布的合成过采样方法及系统,能够避免噪声样本的误差积累且不依赖空间特征,继而保证数据集的类别平衡,提高了分类模型的性能。
2、为实现上述目的,本发明的一个或多个实施例提供了如下技术方案:
3、本发明第一方面提供了一种基于安全梯度分布的合成过采样方法。
4、一种基于安全梯度分布的合成过采样方法,包括:
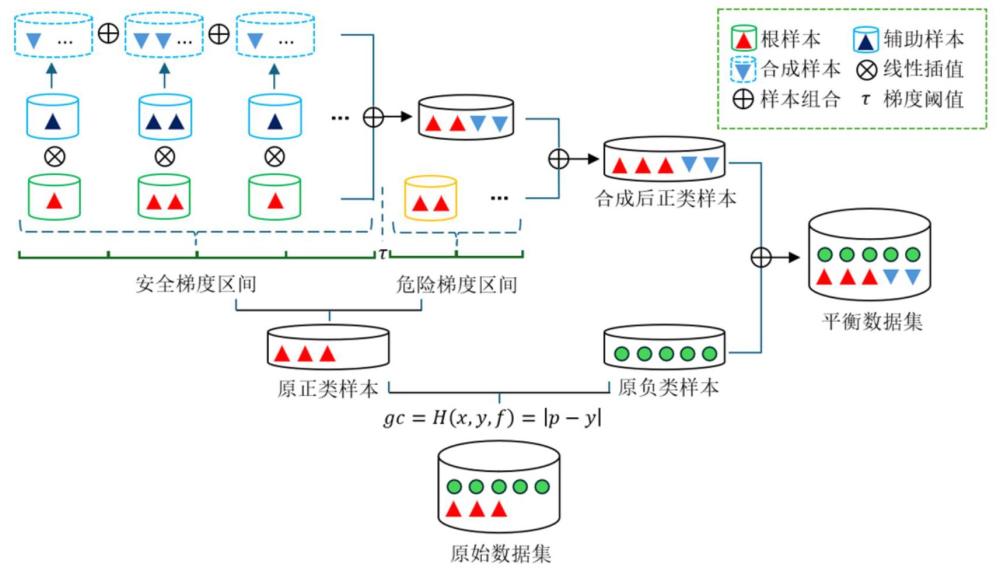
5、获取初始样本数据集,利用样本的交叉熵梯度确定样本的梯度贡献,将0~1范围内的梯度贡献分成多个区间并设置安全梯度阈值,将梯度贡献小于所设安全梯度阈值的区间作为安全梯度区间;
6、按照梯度贡献将所有少数类样本分配到不同的梯度区间并进行安全梯度分布计算;以安全梯度区间内的样本作为根样本,以所述根样本的梯度右近邻作为辅助样本,基于安全梯度分布近似策略确定样本合成数量;
7、采用线性插值方法为每个安全梯度区间合成伪样本,实现样本合成过采样。
8、进一步地,所述梯度贡献由二分类交叉熵损失函数对样本求导得到。
9、进一步地,将梯度贡献大于所述安全梯度阈值的区间作为危险梯度区间;同时,将离所述安全梯度阈值最近的安全梯度区间作为临界安全梯度区间,离安全梯度阈值最近的危险梯度区间作为临界危险梯度区间。
10、进一步地,所述进行安全梯度分布计算,具体的:基于样本的不同梯度区间的分配结果,统计每个安全梯度区间内的正类样本的数量,即计算正类样本的安全梯度分布。
11、进一步地,样本的梯度右近邻为:梯度贡献大于该样本但与该样本的梯度贡献差最小的样本。
12、进一步地,合成伪样本前后,每个安全梯度区间内的样本数量占全部安全梯度区间样本数量的比例保持一致。
13、进一步地,采用线性插值方法为每个安全梯度区间合成伪样本的合成方式为:
14、;
15、其中,表示合成后的伪样本,表示根样本,表示0~1之间的随机数,表示辅助样本。
16、本发明第二方面提供了一种基于安全梯度分布的合成过采样系统。
17、一种基于安全梯度分布的合成过采样系统,包括:
18、梯度区间划分模块,被配置为:通过样本的交叉熵梯度确定样本的梯度贡献,将0~1范围内的梯度贡献分成多个区间并设置安全梯度阈值,将梯度贡献小于所设安全梯度阈值的区间作为安全梯度区间;
19、梯度区间分配模块,被配置为:按照梯度贡献将所有少数类样本分配到不同的梯度区间并进行安全梯度分布计算;以安全梯度区间内的样本作为根样本,以所述根样本的梯度右近邻作为辅助样本,基于安全梯度分布近似策略确定样本合成数量;
20、样本合成模块,被配置为:采用线性插值方法为每个安全梯度区间合成伪样本,实现样本合成过采样。
21、本发明第三方面提供了计算机可读存储介质,其上存储有程序,该程序被处理器执行时实现如本发明第一方面所述的一种基于安全梯度分布的合成过采样方法中的步骤。
22、本发明第四方面提供了电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的程序,所述处理器执行所述程序时实现如本发明第一方面所述的一种基于安全梯度分布的合成过采样方法中的步骤。
23、以上一个或多个技术方案存在以下有益效果:
24、本发明创造性的提出了新的用于在合成过采样方法中对少数类样本进行分类的指标-梯度贡献,并提出了不同的梯度区间概念。因此,本发明不需要计算高维空间距离且不依赖空间特征,可以避免高维空间距离度量失效的问题,继而保证数据集的类别平衡,适用于金融风控数据的高维样本。
25、本发明以安全梯度区间内的样本作为根样本,在一定程度上可以有效避免梯度贡献较大的噪声样本造成的误差累积,且不剔除少数类样本。同时,基于安全梯度分布近似策略计算每个梯度区间合成的数量,因此,本发明能够在提高少数类样本精度的同时,不牺牲多数类样本的精度,具体体现为f1-score、g-mean、mcc、ks等指标比现有方法高。这对信贷违约领域的意义是既能准确识别违约客户,又不会错误识别非违约用户,十分符合现代风控宽信用的要求。
26、本发明结合分类模型的最大分类间隔原则,因此优化后的数据集能使分类模型的决策边界以一种软的方式向多数类移动,从而进一步提高少数类样本的识别精度。
27、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
本文地址:https://www.jishuxx.com/zhuanli/20241204/342965.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表