金融科技与绿色金融耦合性分析方法及系统
- 国知局
- 2024-12-06 13:05:13
本发明涉及绿色金融分析,具体为金融科技与绿色金融耦合性分析方法及系统。
背景技术:
1、绿色金融是指通过金融活动支持环保和可持续发展的经济模式。它包括为环保项目、可再生能源、节能减排以及低碳技术提供融资支持,旨在促进经济的绿色转型和环境保护。绿色金融的目标是推动资源高效利用、减缓气候变化对经济的影响,并实现可持续经济增长。
2、然而,目前的绿色金融分析方法大多局限于定性评估,缺乏系统的量化手段。现有技术往往依赖专家意见和经验判断,对政策影响和企业绩效的评估结果具有主观性和较高的不确定性。此外,现有的分析工具不具备实时动态调整的能力,难以应对政策环境的快速变化,无法为企业提供及时、准确的决策支持。
3、如中国专利公开号cn118134299a所记载,包括基于层次分析法建立低碳政策强度量化指标,对定性的政府低碳政策进行定量分析;基于系统学建立低碳政策和工业负荷的系统动态模型;通过低碳政策强度和工业负荷年变化率建立政策强度和工业负荷的耦合指数,进行耦合关系评估;考虑能源子系统、环境子系统和政治子系统进行政策强度与工业负荷间动态关系建模;将政策强度与工业负荷动态微分方程进行离散化,并采用改进欧拉法进行求解。其虽然能够实现碳排放目标对工业负荷影响的细致分析,但其政策的标准评分仍然是由专家根据经验和标准进行评判,分值具有较大的人为主观因素,不能准确地反映政策变化的实际影响,且不能对企业未来的影响进行分析,无法为企业关于绿色发展方向上的决策提供技术支持。
4、在所述背景技术部分公开的上述信息仅用于加强对本公开的背景的理解,因此它可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、本发明的目的在于提供金融科技与绿色金融耦合性分析方法及系统,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:
3、金融科技与绿色金融耦合性分析方法,具体步骤包括:
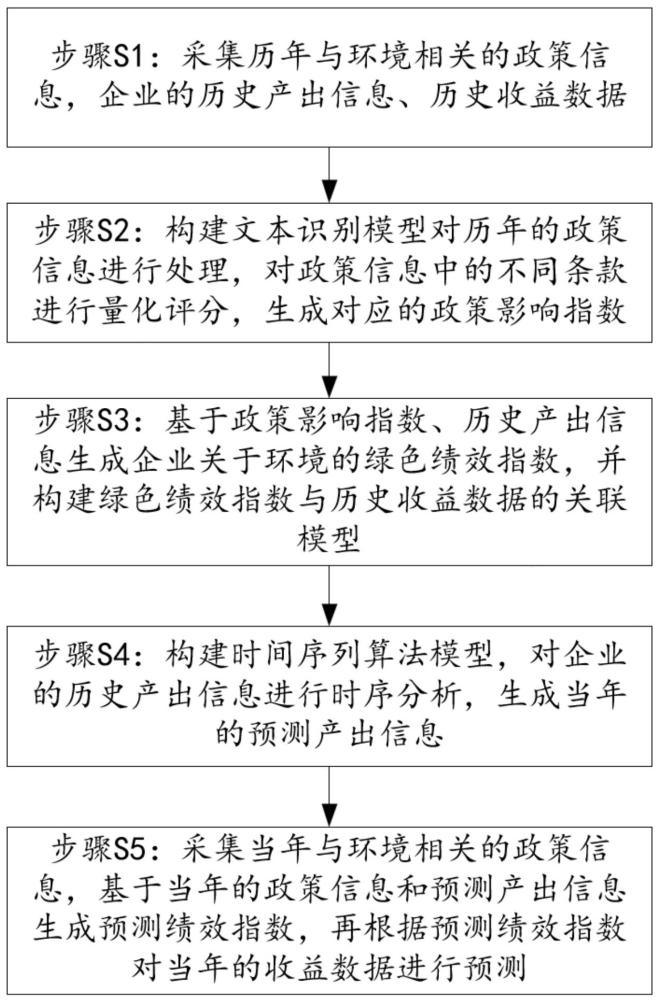
4、s1:采集历年与环境相关的政策信息,企业的历史产出信息、历史收益数据;
5、s2:构建文本识别模型对历年的政策信息进行处理,对政策信息中的不同条款进行量化评分,生成对应的政策影响指数;
6、s3:基于政策影响指数、历史产出信息生成企业关于环境的绿色绩效指数,并构建绿色绩效指数与历史收益数据的关联模型;
7、s4:构建时间序列算法模型,对企业的历史产出信息进行时序分析,生成当年的预测产出信息;
8、s5:采集当年与环境相关的政策信息,基于当年的政策信息和预测产出信息生成预测绩效指数,再根据预测绩效指数对当年的收益数据进行预测。
9、优选的,所述政策信息包括法规文档、补贴文档、税收文档;历史产出信息包括历史生产量、历史销售额,预测产出信息包括预测生产量、预测销售额。
10、优选的,所述文本识别模型采用预设的自然语言处理模型,对政策信息中的不同条款进行量化评分的逻辑为:
11、对政策信息中的不同文档进行文档清洗,去除页眉、页脚、页码、附录,仅保留文档正文,并将文档正文统一转换为utf-8编码格式;
12、将文档正文分割为词组,根据预设的停用词库来去除文档正文中的停用词,并将不同的词组转换为词干形式;
13、计算每个词组在文档正文中的出现频率,并基于每个词组的出现频率生成对应的重要度指数;
14、基于文档正文中每个词组的重要度指数,生成政策关联指数和相应的关联权重,并根据政策关联指数、关联权重生成政策信息的政策影响指数。
15、优选的,每个词组在文档正文中出现频率的计算方式为:
16、;
17、式中表示第个词组在第个文档正文中的出现频率,表示第个词组在第个文档正文中的出现次数,表示第个文档正文中的词组总数;
18、每个词组重要度指数的计算方式为:
19、;
20、式中表示第个词组在第个文档正文中的重要度指数,表示包含第个词组的文档数,表示文档总数;
21、每个文档正文的政策关联指数的计算方式为:
22、;
23、式中表示第个文档正文的政策关联指数;
24、每个文档正文的关联权重的计算方式为:
25、;
26、政策信息的政策影响指数的计算方式为:
27、;
28、式中表示政策影响指数。
29、优选的,所述绿色绩效指数的生成逻辑为:
30、对历史产出信息进行归一化处理,计算方式分别为:
31、;
32、;
33、式中、分别表示第年历史生产量和历史销售额,、分别表示第年历史生产量和历史销售额的归一化值,、分别表示历史生产量的最大值和最小值,、分别表示历史销售额的最大值和最小值;
34、基于多元线性回归方法构建历史生产量、历史销售额、政策影响指数与绿色绩效指数之间的回归方程,回归方程表示为:
35、;
36、式中表示第年的绿色绩效指数,表示第年的政策影响指数,为历年年份的索引,、、表示回归方程中预设的参数权重,,且。
37、优选的,构建绿色绩效指数与历史收益数据的关联模型的逻辑为:
38、基于支持向量回归方法,构建绿色绩效指数与历史收益数据之间的关联模型,关联模型表示为:
39、;
40、式中表示第年的历史收益数据,表示关于的核函数,表示模型误差;
41、其中核函数采用径向基函数,表示为:
42、;
43、式中表示预设的超参数,,表示l2范数,表示预设的参考步长,且为正整数;
44、再使用均方误差来评估关联模型的表现,计算方式为:
45、;
46、式中表示均方误差,表示历年的年数,、分别表示实际采集到的第年的历史收益数据,和关联模型输出的第年的历史收益数据;
47、将绿色绩效指数与历史收益数据按照4:1的比例划分为训练集和验证集,分别利用训练集、验证集对关联模型进行训练优化,当均方误差小于预设的误差阈值时,认为关联模型训练完成。
48、优选的,对当年的收益数据进行预测的逻辑为:
49、所述时间序列算法采用自回归积分滑动平均模型,利用该模型对历史生产量和历史销售额进行时序分析,生成当年的预测生产量和预测销售额;
50、采集当年的政策信息,将当年的政策信息代入文本识别模型进行处理,生成当年的政策影响指数;
51、将当年的预测生产量、预测销售额、政策影响指数代入回归方程,生成预测绩效指数,再将预测绩效指数代入关联模型,生成预测收益数据。
52、优选的,将预测收益数据与历年来的历史收益数据进行比较:
53、满足时,认为当年的预测收益数据较往年大幅下降;
54、满足时,认为当年的预测收益数据较往年差异不大;
55、满足时,认为当年的预测收益数据较往年大幅增长;
56、式中表示预设的波动系数,,表示预测收益数据,表示历年的平均收益数据,计算方式为:
57、。
58、金融科技与绿色金融耦合性分析系统,所述分析系统用于执行上述的分析方法,包括:
59、第一数据采集模块,所述第一数据采集模块用于采集历年的政策信息和当年的政策信息;
60、第二数据采集模块,所述第二数据采集模块用于采集企业的历史产出信息、历史收益数据;
61、文本识别模块,所述文本识别模块用于构建文本识别模型对历年的政策信息进行处理,生成对应的政策影响指数;
62、数据处理模块,所述数据处理模块用于根据政策影响指数、历史产出信息生成企业关于环境的绿色绩效指数,并构建绿色绩效指数与历史收益数据的关联模型;
63、时序分析模块,所述时序分析模块用于构建时间序列算法模型,对企业的历史产出信息进行时序分析,生成当年的预测产出信息;
64、综合处理模块,所述综合处理模块用于将预测收益数据与历史收益数据进行比较,判断当年预测收益数据的波动情况。
65、与现有技术相比,本发明的有益效果是:
66、本发明通过对政策信息和企业绩效进行量化分析,提供了一种动态、全面的耦合性分析方法,通过综合考虑政策影响、企业的生产和销售数据等多个因素对于企业收益的影响,能够有效地衡量企业在环境保护和可持续发展方面的绩效指标。相比现有方法,提高了政策评估的客观性和精确性,降低了人为的主观因素,能够及时反映政策变化的实际影响。同时,结合时间序列和回归模型,增强了收益预测的准确性和灵活性,为企业绿色发展决策提供了强有力的技术支持,确保企业能够及时应对外部环境变化,以帮助企业更好地进行资源配置和优化,提高运营效率和经济效益。
本文地址:https://www.jishuxx.com/zhuanli/20241204/343194.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。