一种基于高维空间异常辨识的风电场数据质量评估方法与流程
- 国知局
- 2025-01-10 13:33:37
本发明属于风电场数据监测,具体涉及一种基于高维空间异常辨识的风电场数据质量评估方法。
背景技术:
1、随着能源结构的转型升级,我国风电装机容量快速增长,大型风电场普遍安装了scada系统监测风机状态,但恶劣环境会导致采集数据质量下降,因此准确识别和处理风电场监测数据中的异常数据至关重要。在传统研究方法中,异常点与伪异常点都被归为广义的异常数据,经过算法处理后两类数据点都将被剔除。这会使得研究人员无法区分是何种原因导致的监测数据异常,不能够有针对性地解决风电场遇到的问题,风电场的运行效率和经济效益无法进一步提高。因此,有必要提出一种基于高维空间聚类的风电场异常监测数据及其成因识别方法,在避免伪异常点干扰的情况下,准确识别出异常数据,以确保风机安全、高效运行。
技术实现思路
1、本发明的目的是为了解决现有异常点识别方法无法区分异常点类型,导致风电场的运行效率和经济效益低的问题,提出了一种基于高维空间异常辨识的风电场数据质量评估方法。
2、本发明的技术方案为:一种基于高维空间异常辨识的风电场数据质量评估方法,包括以下步骤:
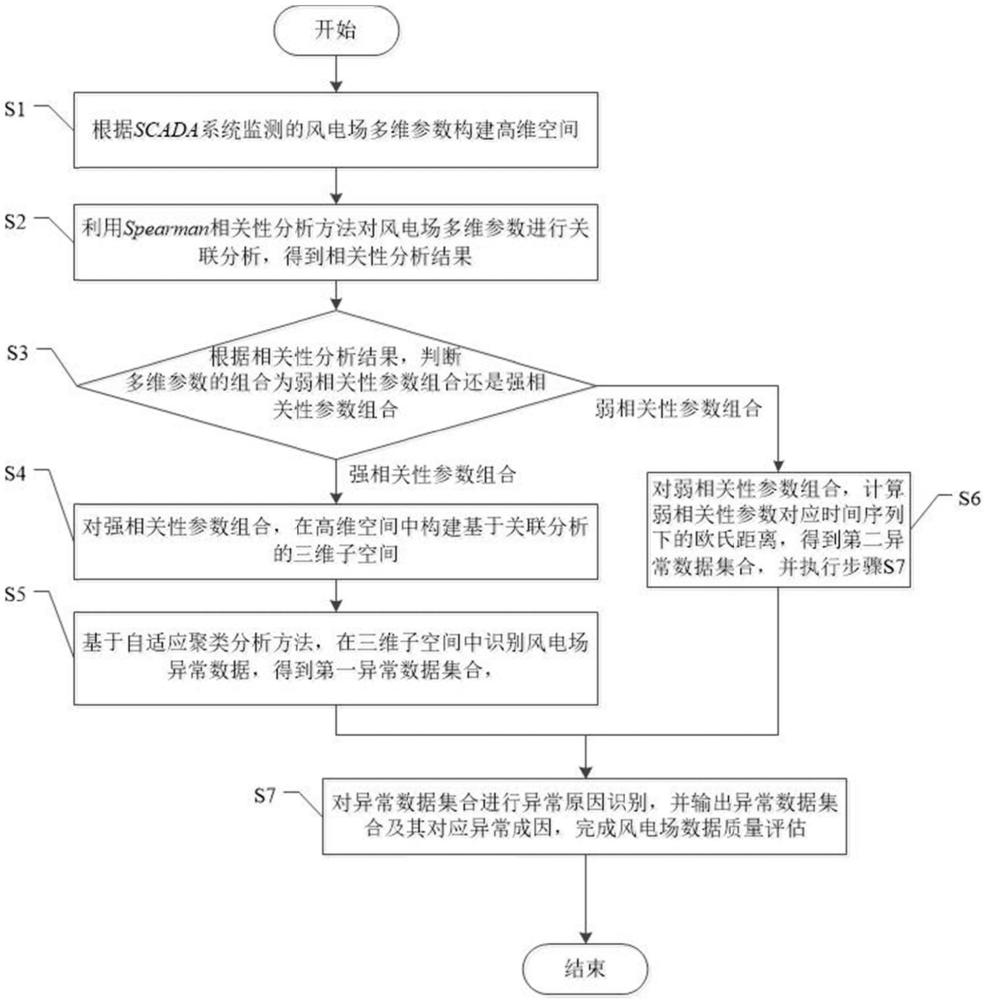
3、s1.根据scada系统监测的风电场多维参数构建高维空间;
4、s2.利用spearman相关性分析方法对风电场多维参数进行关联分析,得到相关性分析结果;
5、s3.根据相关性分析结果,判断风电场多维参数的组合为弱相关性参数组合还是强相关性参数组合,若为强相关性参数组合,执行步骤s4;若为弱相关性参数组合,执行步骤s6;
6、s4.对强相关性参数组合,在高维空间中构建基于关联分析的三维子空间;
7、s5.基于自适应聚类分析方法,在三维子空间中识别风电场异常数据,得到第一异常数据集合,并执行步骤s7;
8、s6.对弱相关性参数组合,计算弱相关性参数对应时间序列下的欧氏距离,得到第二异常数据集合,并执行步骤s7;
9、s7.对异常数据集合进行异常原因识别,并输出异常数据集合及其对应异常成因,完成风电场数据质量评估。
10、本发明的有益效果是:
11、1、本发明基于多维参数间的关联关系,在高维空间中构建子空间进行多次聚类处理,高效利用scada系统采集的监测参数数据,提高了异常数据识别的准确性,增强了风电场情况把握的全面性。
12、2、本发明在识别异常数据的过程中,能够准确识别出因通讯故障、测量设备故障导致的异常点,同时避免了伪异常点的影响。不同于传统方法将两类异常点一起剔除,本发明方法能有效区分异常数据点产生原因,为运维人员提供风电场运行状态的有效参考。
13、作为优选,步骤s1中所述高维空间的表述公式为:
14、
15、其中,xi表示i时刻下风机状态的高维空间坐标点,vi表示i时刻下的风速,ti表示i时刻下的绕组温度,ii表示i时刻下的绕组电流,pi表示i时刻下的功率,ni表示i时刻下的发电机转速,oi表示i时刻下的齿轮箱油温,n表示scada系统采集数据的时刻数,s表示整个采集时段中所有时刻构建的高维空间。
16、上述优选方案的有益效果是:
17、scada系统监测的风电场多维参数共同反映了一个风电场的整体状态,基于scada系统监测的风电场多维参数构建高维空间,可以更好地把握风电场情况,及时发现其中存在的异常问题。
18、作为优选,所述步骤s2具体包括以下分步骤:
19、s21.将风电场多维参数的数据按照大小排序,并为每个数值分配相应的秩次;
20、s22.对各风电场多维参数组合中对应的数据点,计算两个参数的秩次差;
21、s23.根据秩次差计算得到spearman相关系数rs;
22、s24.通过假设检验对spearman相关系数rs进行分析解释,得到相关性分析结果。
23、作为优选,步骤s23中所述spearman相关系数的计算公式为:
24、
25、其中,x和y表示两个待分析的数据变量,xl表示数据变量x中的第l个值,yl表示数据变量y中的第l个值,r(xl)表示xl在x中的大小排名,r(yl)表示yl在y中的大小排名,表示x名次均值,表示y名次均值,m表示数据对个数,dl表示第l个数据对的秩次差。
26、上述优选方案的有益效果是:
27、通过spearman相关性分析方法对风电场多维参数进行关联分析,能够准确衡量风电场不同维度参数之间的单调关系,并且不易受异常值的影响,有助于三维子空间的构建。
28、作为优选,步骤s3中所述强相关性参数组合为spearman相关系数rs≥0.9的参数组合;所述弱相关性参数组合为spearman相关系数rs<0.9的参数组合。
29、上述优选方案的有益效果是:
30、基于spearman相关系数划分将参数组合分为强相关性参数组合和弱相关性参数组合,能够准确识别异常数据的成因。
31、作为优选,步骤s4中所述三维子空间的表述公式为:
32、
33、其中,yi表示i时刻下风机状态的子空间坐标点,vi表示i时刻下的风速,ei表示i时刻下的电气参数,ci表示i时刻下的物理参数,n表示scada系统采集数据的时刻数,s表示整个采集时段中所有时刻构建的子空间。
34、作为优选,所述步骤s5具体包括以下分步骤:
35、s51.在三维子空间中,根据强相关性参数组合的总样本数量及数据范围设置p个半径r和q个最小样本数min_sample取值,将两组参数进行全组合操作,得到完整的聚类参数组合;
36、s52.将聚类参数组合依次输入到dbscan算法中进行聚类,并在计算异常数据识别准确率,根据最高的准确率数值找到全局最优参数组合;
37、s53.根据全局最优参数组合,得到自适应dbscan聚类算法;
38、s54.通过自适应dbscan聚类算法,识别三维子空间内的数据点,得到第一异常数据集合。
39、作为优选,步骤s52中所述dbscan算法包括以下步骤:
40、a1.随机选择一个未被访问的数据点作为起始点,计算其邻域内的所有数据点,若邻域内的数据点数量大于等于最小样本点数min_sample,则该点被标记为核心点,并将其邻域内的数据点添加到同一簇m中,若邻域内的数据点数量小于最小样本点数min_sample,但其邻域内存在核心点,则将该点标记为边界点,若邻域内不存在核心点,则将该点标记为噪声点;
41、a2.对待加入簇m的数据点进行密度可达性查询,将满足条件的数据点加入簇m中,直到无法再找到新的核心点,并执行步骤a3;
42、a3.以下一个未被访问的数据点作为新的核心点,若某个数据点既不是核心点也不是边界点,则将其标记为噪声点,并执行步骤a4;
43、a4.重复步骤a1至步骤a3,直至所有数据点都被访问过,且每个数据点都被分配到某一个簇中或被标记为噪声点为止。
44、上述优选方案的有益效果是:
45、上述优选方案在识别异常数据的过程中,采用自适应算法设置半径、最小样本数等dbscan聚类的关键参数,避免了主观设置的随机参数对异常数据识别效果的影响,克服了人工干预的缺点。
46、作为优选,所述步骤s6中得到第二异常数据集合的具体方法为:对弱相关性参数组合,逐点计算两个参数对应时间序列下的欧氏距离,绘制得到两个参数间欧氏距离随时间变化的曲线;筛选出曲线中数据突变为0或曲线中存在恒定不变的一段对应的数据,得到第二异常数据集合。
47、上述优选方案的有益效果是:
48、对弱相关性参数组合,通过计算两个参数之间的欧氏距离,并绘制欧氏距离随时间变化的曲线,能够直观有效的识别出异常数据。
49、作为优选,所述步骤s7中,第一异常数据集合的异常成因为:测量装置故障;第二异常数据集合的异常成因为:通讯设备故障。
本文地址:https://www.jishuxx.com/zhuanli/20250110/353916.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。