一种基于综合损失的演员评论家算法的机器人控制方法
- 国知局
- 2024-07-05 17:45:03
本发明涉及机器人强化学习,尤其是涉及一种基于综合损失的演员评论家算法的机器人控制方法。
背景技术:
1、演员评论家(actor-critic)是一种基于值函数和策略函数的强化学习算法,可用于解决连续动作空间问题。目前机器人智能体也常常会用到演员-评论家算法训练,通过构建演员和评论家两个网络,演员网络(actor)负责学习策略函数,根据当前状态选择动作;评论家网络(critic)负责评估策略的好坏,给出相应的奖励信号。通过不断优化策略函数,使得机器人学习最优的行动策略。但是我们发现采用现有的演员评论家算法进行机器人智能体控制时,会出现如下问题:在具有高维度连续性状态动作空间的机器人上执行策略过程有时候会因为该算法值函数误差问题而失败。
2、现有的解决近似偏差问题有双q学习,例如,fujimoto等人提出了一种名为修剪双q学习的结构,通过找到两个q网络的最小值进行价值估计来减少过高估计偏差,但却引入了低估偏差。此外,在连续控制任务中,pan等人将贝尔曼方程中的动作值估计函数替换为boltzmann softmax运算符,并将其与修剪双q学习结合起来,以解决过高估计和低估偏差问题。此外,pan等人证明了softmax运算符可以平滑优化景观,进而开发了softmax深度双确定性策略梯度(sd3)方法。这两种方法都试图通过在贝尔曼方程中使用固定形式的价值估计来消除近似偏差,但是估计误差还是消除不干净,只能在一定程度上缓解,仍然存在学习收敛速度缓慢,不能动态的检测值函数的估计误差情况并动态的做出反应的问题,使得机器人采用这些方法训练后的性能在实际应用的时候仍然受损较大。
技术实现思路
1、本发明要解决的技术问题,在于提供一种基于综合损失的演员评论家算法的机器人控制方法,采用改进后的强化学习训练方法对机器人进行训练与控制,可有效消除在训练过程中的过估计误差和欠估计误差以获得更好的值函数估计,提高训练效果,同时通过误差控制方法限制策略的熵来驱动策略进行更多的探索,减少策略误差,提高机器人控制策略的准确度与效率。
2、本发明是这样实现的:一种基于综合损失的演员评论家算法的机器人控制方法,所述方法包括:
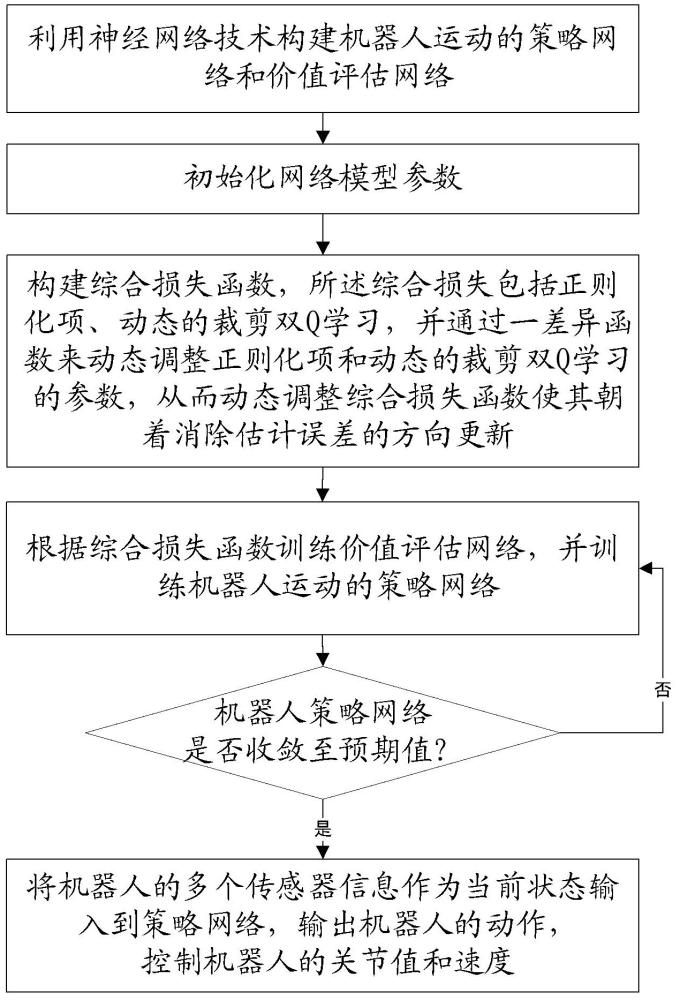
3、步骤s1、利用神经网络技术构建机器人运动的策略网络和价值评估网络;
4、步骤s2、初始化网络模型参数;
5、步骤s3、构建综合损失函数,所述综合损失包括正则化项、动态的裁剪双q学习,并通过一差异函数来动态调整正则化项和动态的裁剪双q学习的参数,从而动态调整综合损失函数使其朝着消除估计误差的方向更新;
6、步骤s4、根据综合损失函数训练价值评估网络,并训练机器人运动的策略网络;
7、步骤s5、判断机器人策略网络是否收敛至预期值,若是,则将机器人的多个传感器信息作为当前状态输入到策略网络,输出机器人的动作,控制机器人的关节值和速度;否则,返回步骤s4。
8、进一步的,所述步骤s1中的机器人运动的策略网络的输入为机器人的传感器信息,所述机器人的传感器信息作为状态s输入,其输出为机器人的动作a,该动作a直接控制着机器人的自由关节使其完成指定的动作;
9、所述价值评估网络以机器人传感器输入的状态s和机器人的动作a作为输入,给出价值评分q。
10、进一步的,所述步骤s3中的差异函数是由实际回报与假设回报组成,所述假设回报基于价值函数估计得到的,真实回报基于动作价值函数的真实价值计算得到的,所述差异函数的计算公式如下:
11、
12、其中,r的计算公式如下:
13、
14、上述r为实际回报,为折扣系数,t为总时刻数,表示价值评估网络参数,表示初始时刻价值评估网络输出值,表示价值评估网络输出的平均值,表示第t时刻的真实价值,表示初始时刻的真实价值。
15、进一步的,所述步骤s3中“通过一差异函数来动态调整正则化项和动态的裁剪双q学习的参数,从而动态调整综合损失函数使其朝着消除估计误差的方向更新”的具体为:当差异函数表达为过估计时,正则化项参数和动态裁剪双q学习的参数就朝着消除过估计的方向更新,反之,差异函数表达为欠估计时,它们就朝着消除欠估计的方向更新:
16、对于正则化项参数,设计一用于控制所述正则化项参数值大小的差异损失函数:
17、
18、其中是由正则化项参数计算得到的正则化项参数变体,如果差异函数小于零,即表示过高估计,则增加以进一步减小其损失函数,使正则化项变得更加重要,否则,减小;
19、其中,与之间的关系如下:
20、
21、其中为系数,根据实际需要采用指数形式或线性形式;
22、对于动态裁剪双q学习的参数,设计一用于控制所述动态裁剪双q学习的参数值大小的差异损失函数:
23、
24、其中是参数计算得到的参数变体,如果差异函数大于零,则减小以减轻低估偏差,否则,增大;
25、其中,与之间的关系如下:
26、
27、其中为系数。
28、进一步的,所述综合损失函数具体为:
29、
30、其中,为综合损失函数,表示正则化项对应的损失函数,表示标准损失,表示从经验回放缓存d中采样状态s和动作a计算得到的期望值,表示正则化项参数,表示参数为的价值评估网络的输出值,表示价值评估网络的目标函数,所述价值评估网络的目标函数的计算公式如下:
31、
32、其中,表示收益值,为折扣系数,为动态裁剪双q学习的参数,表示在下一状态和下一动作下的参数为的第i个值函数估计器的输出值。
33、进一步的,在所述步骤s4中的机器人运动的策略网络在训练过程中引入误差控制,以减少值函数的估计偏差,所述误差控制是通过限制每两个连续策略之间的kullback-leibler散度来提高策略的稳定性,下文中的就是演员网络的记号,它以机器人的传感器数据作为状态输入,并给出动作,即为策略,所述演员网络的误差控制函数如下:
34、
35、其中,表示从经验回放缓存d中采样状态和动作计算的期望值,表示价值评估网络输出值,和表示权重系数,表示熵函数,表示交叉熵,表示参数为的随机性的策略函数,表示是给定状态,不管策略分布的输出是什么,表示前一时刻的参数下的随机性的策略函数。
36、本发明具有如下优点:提出了一个差异函数来计算动作值近似与实际回报之间的差异,以揭示近似偏差的类型和大小,并设计了一个基于所述差异函数值动态调整系数的综合损失函数用于动作值估计,以减少过高估计和低估计偏差,基于该差异函数和综合损失,设计一种新的演员-评论家算法来控制连续控制任务的机器人,同时,本发明还使用误差控制方法来减少值函数的估计偏差,进一步提高机器人策略的精确性与稳定性。
技术特征:1.一种基于综合损失的演员评论家算法的机器人控制方法,其特征在于:所述方法包括:
2.根据权利要求1所述的一种基于综合损失的演员评论家算法的机器人控制方法,其特征在于:所述步骤s1中的机器人运动的策略网络的输入为机器人的传感器信息,所述机器人的传感器信息作为状态s输入,其输出为机器人的动作a,该动作a直接控制着机器人的自由关节使其完成指定的动作;
3.根据权利要求1所述的一种基于综合损失的演员评论家算法的机器人控制方法,其特征在于:所述步骤s3中“通过一差异函数来动态调整正则化项和动态的裁剪双q学习的参数,从而动态调整综合损失函数使其朝着消除估计误差的方向更新”的具体为:当差异函数表达为过估计时,正则化项参数和动态裁剪双q学习的参数就朝着消除过估计的方向更新,反之,差异函数表达为欠估计时,它们就朝着消除欠估计的方向更新:
4.根据权利要求1所述的一种基于综合损失的演员评论家算法的机器人控制方法,其特征在于:所述综合损失函数具体为:
5.根据权利要求1所述的一种基于综合损失的演员评论家算法的机器人控制方法,其特征在于:
技术总结本发明提供一种基于综合损失的演员评论家算法的机器人控制方法,包括:利用神经网络技术构建机器人运动的策略网络和价值评估网络;初始化网络模型参数;构建综合损失函数,所述综合损失包括正则化项、动态的裁剪双Q学习,并通过一差异函数检测估计误差的类型与大小来动态调整正则化项和动态的裁剪双Q学习的参数,使其朝着消除估计误差的方向更新;根据综合损失函数训练价值评估网络,并训练机器人运动的策略网络;判断机器人策略网络是否收敛至预期值,若是,则将机器人的多个传感器信息作为当前状态输入到策略网络,输出机器人的动作控制机器人的关节值和速度;否则,继续训练直至收敛至预期值。技术研发人员:晁飞,过博文,纪荣嵘受保护的技术使用者:厦门大学技术研发日:技术公布日:2024/5/29本文地址:https://www.jishuxx.com/zhuanli/20240617/49011.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
一种多工位夹具的制作方法
下一篇
返回列表