语音监测方法、装置、电子设备及可读存储介质与流程
- 国知局
- 2024-06-21 10:38:30
本申请实施例涉及语音识别,尤其涉及一种语音监测方法、装置、电子设备及可读存储介质。
背景技术:
1、随着物联网、语音识别等技术的发展,医疗服务逐渐走向真正意义的智能化。通过打造健康档案区域医疗信息平台,利用先进的物联网技术,实现患者与医疗设备之间的交互,实现交互过程中的关键为语音识别,通过对用户语音的识别不仅能够识别出用户的身份,而且能够监测出用户的健康状况,例如,用户a感冒了,通过识别用户a的语音能够判断出异常。
2、目前,语音监测方法通常包括语音数据采集、特征提取和模式识别,然而,语音信息的声音来源不稳定,或者携带大量的环境噪声时,直接提取语音数据中的特征信息进行健康状况监测,其监测结果容易出现偏差,可靠性较低。
技术实现思路
1、本申请实施例提供了一种语音监测方法、装置、电子设备及可读存储介质,以至少解决现有技术中,直接提取语音数据中的特征信息进行健康状况监测,其监测结果容易出现偏差,可靠性较低的问题。
2、为了解决上述技术问题,本申请是这样实现的:
3、第一方面,本申请实施例提供了一种语音监测方法,包括:
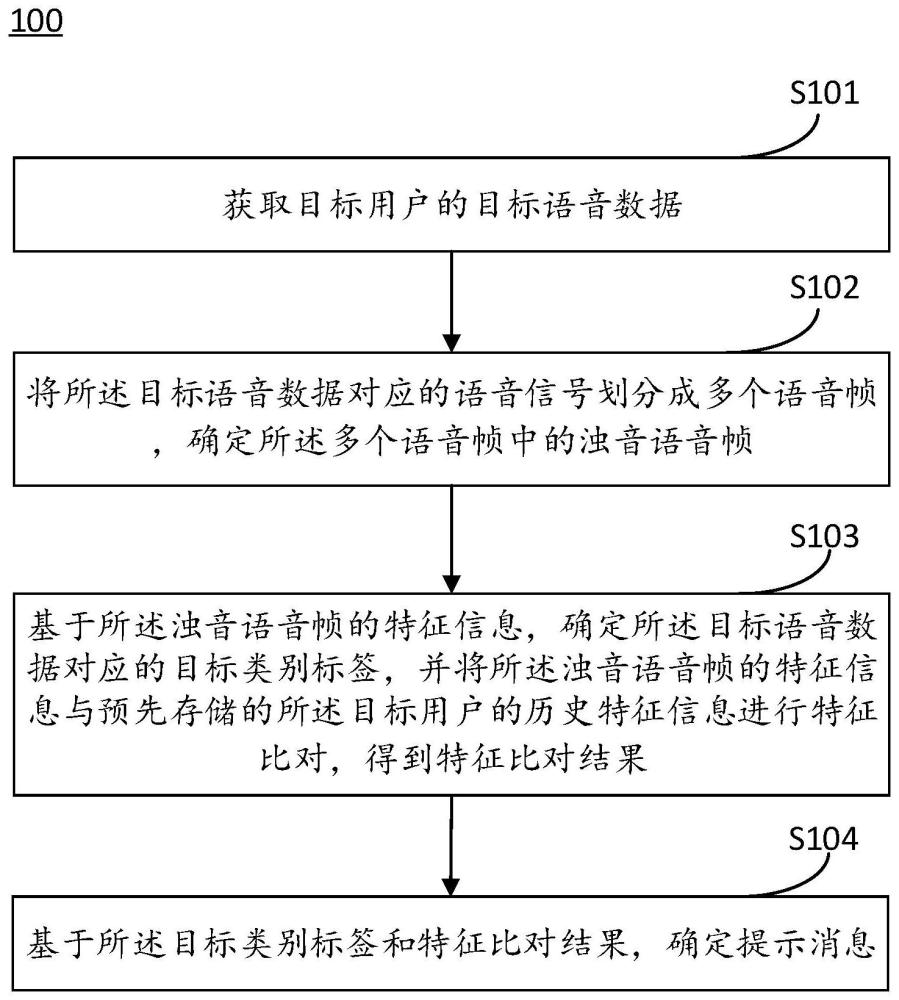
4、获取目标用户的目标语音数据;
5、将所述目标语音数据对应的语音信号划分成多个语音帧,确定所述多个语音帧中的浊音语音帧;
6、基于所述浊音语音帧的特征信息,确定所述目标语音数据对应的目标类别标签,并将所述浊音语音帧的特征信息与预先存储的所述目标用户的历史特征信息进行特征比对,得到特征比对结果;所述类别标签用于指示目标语音数据是否表现为目标疾病;
7、基于所述目标类别标签和特征比对结果,确定提示消息。
8、在一种可能的实施方式中,在所述获取目标用户的目标语音数据之后,将所述目标语音数据对应的语音信号划分成多个语音帧,确定所述多个语音帧中的浊音语音帧之前,还包括:
9、在所述目标语音数据满足预设的语音音质条件的情况下,保存所述目标语音数据和所述目标语音数据对应的采集时间;所述语音音质条件为所述目标语音数据的信噪比大于预设的信噪比阈值。
10、在一种可能的实施方式中,通过以下方式确定所述目标语音数据的信噪比:
11、获取所述目标语音数据中的目标信号,所述目标信号包括带噪语音信号和噪声信号;
12、将所述目标信号划分成多个信号帧,确定每个信号帧对应的带噪信号功率谱和噪声信号功率谱;
13、针对每一个信号帧,根据所述信号帧各频率点对应的后验信噪比估算先验信噪比,根据所述先验信噪比和噪声信号功率谱,确定所述信号帧各频率点对应的语音信号功率;根据各频率点的语音信号功率和噪声功率确定所述信号帧对应的帧信号信噪比;所述先验信噪比为语音信号功率与噪声信号功率的比值;所述后验信噪比为带噪语音信号功率和噪声信号功率的比值;
14、将所述目标信号的多个信号帧的帧信号信噪比的加权平均值,确定为所述目标语音数据的信噪比。
15、在一种可能的实施方式中,获取目标用户的目标语音数据,包括:
16、基于与所述目标用户之间的语音交互内容,获取所述目标用户的目标语音数据;或者,
17、响应于目标用户对预设业务事项的触发操作,采集所述目标用户的目标语音数据。
18、在一种可能的实施方式中,所述确定所述多个语音帧中的浊音语音帧,包括:
19、针对每一个语音帧,确定所述语音帧的自相关函数;
20、根据所述自相关函数确定所述语音帧对应的浊音分值;所述浊音分值用于指示对应的语音帧中包含浊音基频成分的概率;
21、在所述浊音分值大于预设的分值阈值的情况下,确定所述语音帧为浊音语音帧。
22、其中,所述特征信息至少包括以下之一:短时能量特征、谱熵特征、短时平均过零率特征、梅尔倒谱系数特征、线性预测系数特征。
23、在一种可能的实施方式中,所述基于所述浊音语音帧的特征信息,确定所述目标语音数据对应的目标类别标签,包括:
24、将所述浊音语音帧的特征信息输入至预先训练的分类模型中进行特征融合处理,输出得到所述目标语音数据对应的类别标签;其中,所述分类模型由深度置信网络构建而成,所述深度置信网络包括预设层数的依次连接的受限玻尔兹曼机。
25、第二方面,本申请实施例提供了一种语音监测装置,包括:
26、数据获取模块,用于获取目标用户的目标语音数据;
27、语音处理模块,用于将所述目标语音数据对应的语音信号划分成多个语音帧,确定所述多个语音帧中的浊音语音帧;
28、基于所述浊音语音帧的特征信息,确定所述目标语音数据对应的目标类别标签,并将所述浊音语音帧的特征信息与预先存储的所述目标用户的历史特征信息进行特征比对,得到特征比对结果;所述类别标签用于指示目标语音数据是否表现为目标疾病;
29、基于所述目标类别标签和特征比对结果,确定提示消息。
30、第三方面,本申请实施例提供了一种电子设备,所述电子设备包括处理器和存储器,所述存储器存储可在所述处理器上运行的程序或指令,所述程序或指令被所述处理器执行时实现上述的语音监测方法的步骤。
31、第四方面,本申请实施例提供了一种计算机可读存储介质,所述计算机可读存储介质上存储程序或指令,所述程序或指令被处理器执行时实现上述的语音监测方法的步骤。
32、本申请实施例提供的语音监测方法,获取目标用户的目标语音数据;将目标语音数据对应的语音信号划分成多个语音帧,确定多个语音帧中的浊音语音帧;基于浊音语音帧的特征信息,确定目标语音数据对应的目标类别标签,并将浊音语音帧的特征信息与预先存储的目标用户的历史特征信息进行特征比对,得到特征比对结果;类别标签用于指示目标语音数据是否表现为目标疾病;基于目标类别标签和特征比对结果,确定提示消息。
33、由于病理语音最明显的表现是浊音/元音的异常,呼吸系统疾病、脑卒中、声带麻痹、阿尔兹海默症、帕金森病等疾病患者的语音都有浊音/元音异常现象,并且浊音具有相对稳定的频率,因此,基于浊音语音帧的特征信息进行分析,可以降低环境噪声对监测结果的影响,提高监测结果的可靠性,并且结合当前获取的特征信息与目标用户的历史特征信息的特征比对结果确定提示消息,可以避免由于语音信息的声音来源不稳定导致的语音监测结果出现偏差,甚至无法得到监测结果的问题,从而有利于提高目标用户语音监测的准确率。
34、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本申请。
技术特征:1.一种语音监测方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,在所述获取目标用户的目标语音数据之后,将所述目标语音数据对应的语音信号划分成多个语音帧,确定所述多个语音帧中的浊音语音帧之前,还包括:
3.根据权利要求2所述的方法,其特征在于,通过以下方式确定所述目标语音数据的信噪比:
4.根据权利要求1所述的方法,其特征在于,获取目标用户的目标语音数据,包括:
5.根据权利要求1所述的方法,其特征在于,所述确定所述多个语音帧中的浊音语音帧,包括:
6.根据权利要求1所述的方法,其特征在于,所述特征信息至少包括以下之一:短时能量特征、谱熵特征、短时平均过零率特征、梅尔倒谱系数特征、线性预测系数特征。
7.根据权利要求1所述的方法,其特征在于,所述基于所述浊音语音帧的特征信息,确定所述目标语音数据对应的目标类别标签,包括:
8.一种语音监测装置,其特征在于,包括:
9.一种电子设备,其特征在于,所述电子设备包括处理器和存储器,所述存储器存储可在所述处理器上运行的程序或指令,所述程序或指令被所述处理器执行时实现如权利要求1至7任一项所述的方法的步骤。
10.一种可读存储介质,其特征在于,所述可读存储介质上存储程序或指令,所述程序或指令被处理器执行时实现如权利要求1至7任一项所述的方法的步骤。
技术总结本申请公开一种语音监测方法、装置、电子设备及可读存储介质,属于语音识别技术领域。该方法包括:获取目标用户的目标语音数据;将目标语音数据对应的语音信号划分成多个语音帧,确定多个语音帧中的浊音语音帧;基于浊音语音帧的特征信息,确定目标语音数据对应的目标类别标签,并将浊音语音帧的特征信息与预先存储的目标用户的历史特征信息进行特征比对,得到特征比对结果;基于目标类别标签和特征比对结果,确定提示消息。通过该方式,可以避免由于语音信息的声音来源不稳定,或者携带大量的环境噪声导致的语音监测结果出现偏差的问题,提高目标用户语音监测的准确率。技术研发人员:韩振虎,张玮,赵莉受保护的技术使用者:人保信息科技有限公司技术研发日:技术公布日:2024/1/15本文地址:https://www.jishuxx.com/zhuanli/20240618/20873.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。