模型训练及语音生成方法、装置、设备及存储介质与流程
- 国知局
- 2024-06-21 10:41:10
本公开涉及人工智能,尤其涉及一种语音生成方法、装置、设备及存储介质。
背景技术:
1、随着人工智能技术的不断发展,虚拟数字人应运而生。虚拟数字人,可针对不同场景,使所展示的虚拟影像配合着音频输出内容,呈现出与音频输出内容相呼应的且较为真实的人物姿态。
2、目前,为了加强虚拟数字人的应用推广,逐步将个人的独特风格融入到虚拟数字人技术中,即在保留原始语音信息内容的条件下,将虚拟数字人对应的音频输出内容赋予个人特性,从而针对不同用户需求构建符合相应人物特点的虚拟数字人。
3、但在实现过程中,往往需要庞大的数据样本才能完成生成模型的训练,且训练结果也未能尽如人意。因此,亟需一种语音生成方案,以解决上述技术问题。
技术实现思路
1、有鉴于此,本公开实施例提供了一种语音生成方法、装置、设备及存储介质,能够解决通过大量数据样本才能耗时耗力完成生成模型训练的技术问题。
2、第一方面,本公开实施例提供了一种模型训练方法,采用如下技术方案:
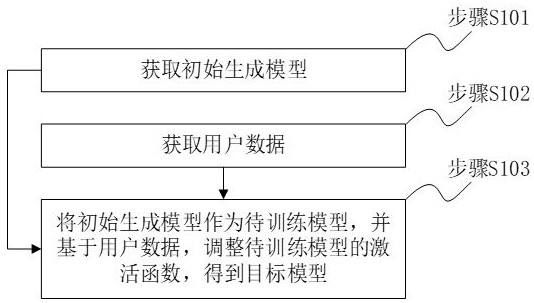
3、获取初始生成模型,所述初始生成模型为经过预训练的条件扩散模型;获取用户数据,所述用户数据包括用于反映目标人物特性的文本语音对数据;将所述初始生成模型作为待训练模型,并基于所述用户数据,调整所述待训练模型的激活函数,得到目标模型,所述目标模型用于语音生成。
4、第二方面,本公开实施例提供了一种语音生成方法,采用如下技术方案:
5、获取待转换文本;通过第一方面中的所述目标模型,得到与所述待转换文本对应的频谱图;将所述频谱图转换为语音信号。
6、第三方面,本公开实施例提供了一种模型训练装置,采用如下技术方案:
7、第一获取单元,用于获取初始生成模型,所述初始生成模型为经过预训练的条件扩散模型;所述第一获取单元,还用于获取用户数据,所述用户数据包括用于反映目标人物特性的文本语音对数据;调整单元,用于将所述初始生成模型作为待训练模型,并基于所述用户数据,调整所述待训练模型的激活函数,得到目标模型,所述目标模型用于语音生成。
8、第四方面,本公开实施例提供了一种语音生成装置,采用如下技术方案:
9、第二获取单元,用于获取待转换文本;输出单元,用于通过第一方面中的所述目标模型,得到与所述待转换文本对应的频谱图;转换单元,用于将所述频谱图转换为语音信号。
10、第五方面,本公开实施例还提供了一种电子设备,采用如下技术方案:
11、所述电子设备包括:
12、至少一个处理器;以及,
13、与所述至少一个处理器通信连接的存储器;其中,
14、所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行以上第一方面或第二方面的方法。
15、第六方面,本公开实施例还提供了一种计算机可读存储介质,该计算机可读存储介质存储计算机指令,该计算机指令用于使计算机执行以上第一方面或第二方面的方法。
16、本公开实施例提供的技术方案,可以有效省略海量数据的获取及利用海量数据进行模型训练的过程。在得到用于生成符合用户预期的语音的目标模型的情况下,节省数据收集及模型训练所耗费的人力物力。相比较于传统的seq2seq模型而言,本公开提供的技术方案,能有效提升训练精度,更有针对性的完成模型个性化部分的训练。此外,相比较于基于更深度的transformer等结构而言,仅利用有限的数据样本,便可以得到符合用户预期的语音。
17、上述说明仅是本公开技术方案的概述,为了能更清楚了解本公开的技术手段,而可依照说明书的内容予以实施,并且为让本公开的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
技术特征:1.一种模型训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述待训练模型包括上采样模块,所述上采样模块包括l个上采样卷积层;
3.根据权利要求1或2所述的方法,其特征在于,所述获取用户数据包括如下至少一项:
4.根据权利要求1或2所述的方法,其特征在于,在所述获取初始生成模型之后,所述方法还包括:
5.根据权利要求1或2所述的方法,其特征在于,所述训练数据包括如下至少一项:
6.一种语音生成方法,其特征在于,所述方法包括:
7.一种模型训练装置,其特征在于,所述装置包括:
8.一种语音生成装置,其特征在于,所述装置包括:
9.一种电子设备,其特征在于,所述电子设备包括:
10.一种计算机可读存储介质,其特征在于,该计算机可读存储介质存储计算机指令,该计算机指令用于使计算机执行权利要求1至5中任一项所述的模型训练方法,或权利要求6所述的语音生成方法。
技术总结本公开实施例公开了一种模型训练及语音生成方法、装置、设备及存储介质。该方法包括:获取初始生成模型,初始生成模型为经过预训练的条件扩散模型;获取用户数据,用户数据包括用于反映目标人物特性的文本语音对数据;将初始生成模型作为待训练模型,并基于用户数据,调整待训练模型的激活函数,得到目标模型,目标模型用于语音生成。技术研发人员:游世学,郭锐,徐峰,乔亚飞受保护的技术使用者:北京中科汇联科技股份有限公司技术研发日:技术公布日:2024/1/25本文地址:https://www.jishuxx.com/zhuanli/20240618/21202.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。