一种基于微调大语言模型在嘈杂环境下的语音识别方法与流程
- 国知局
- 2024-06-21 10:41:08
本发明涉及语音识别,具体为一种基于微调大语言模型在嘈杂环境下的语音识别方法。
背景技术:
1、随着统一通信应用在全网的深入推广,用户规模不断增长,作为服务全网30万用户的通信服务热线的话务压力将急剧增加,同时随着通信业务不断发展,通信服务业务范围也将越来越广,受限于现有人工客服人力、工作时间、知识水平等因素限制,当前的统一通信客服平台已难以满足话务咨询的增长需求。而人工坐席和传统自助语音应答系统由于采用按键交互方式,用户与系统之间的交互效率受到很大限制,客户等待时间过长导致客户体验不佳,严重影响客户体验。当用户无法快捷获取到需要的服务时候,便会转向人工服务,使人工话务压力大大增加,运营成本上升;作为电网安全稳定运行的关键环节,电力调度员、通信调度、自动化调度运行人员负责操控指挥电力系统运行,调度台每日都记录了调度员海量的调度录音数据,目前这些数据分散在各级系统,主要用于异常事件发生后通过回放录音来帮助分析故障处理过程。并且由于音频文件占用空间大,且音频格式不便于进行数据归纳分析,文件存储超过一定时限将会删去录音数据,没有办法充分挖掘这些大量生产运行数据的价值,来帮助对调度指挥行为和成效进行深入分析和科学评价。
2、在实际生产生活中,有很多音频充斥着嘈杂的人声或背景声,使得常规机器识别特定语音内容错误率偏高,如超市、火车站或其他开放式营业场所。这种嘈杂的环境给语音识别工作带来了一些困难,不得不通过人力进行二次修正,效率较低且成本偏高;同时很多音频语义分析技术适用的场景往往聚焦于无噪音或低噪声环境下的干净音频分析,为了捕捉音频内容上下文之间的关联关系,学术界和工业界引申出如循环神经网络(rnn)、长短期记忆网络(lstm)等深度学习模型,针对音频数据的transformer架构层出不穷。然而,它们大多都是面向安静环境下分析的。一些针对嘈杂环境下的音频处理技术,例如dc-u-net、sn-net等模型能够以网络的方式在时域和频域两个方面对音频进行降噪处理,但该类技术也没有解决声音来源多变、环境音嘈杂给模型处理带来的噪声。由于在音频降噪、音频处理上的技术常规,很难解决对带噪声的音频文件处理,最终使得输出的文本结果质量差,误差高。
技术实现思路
1、针对现有技术的不足,本发明提供了一种基于微调大语言模型在嘈杂环境下的语音识别方法,解决了传统的语音自动检测方法无法解决嘈杂环境下的语义信息的缺失和相似发音的识别,最终仍依赖于人工主观判断,缺乏准确性并且效率低的问题。
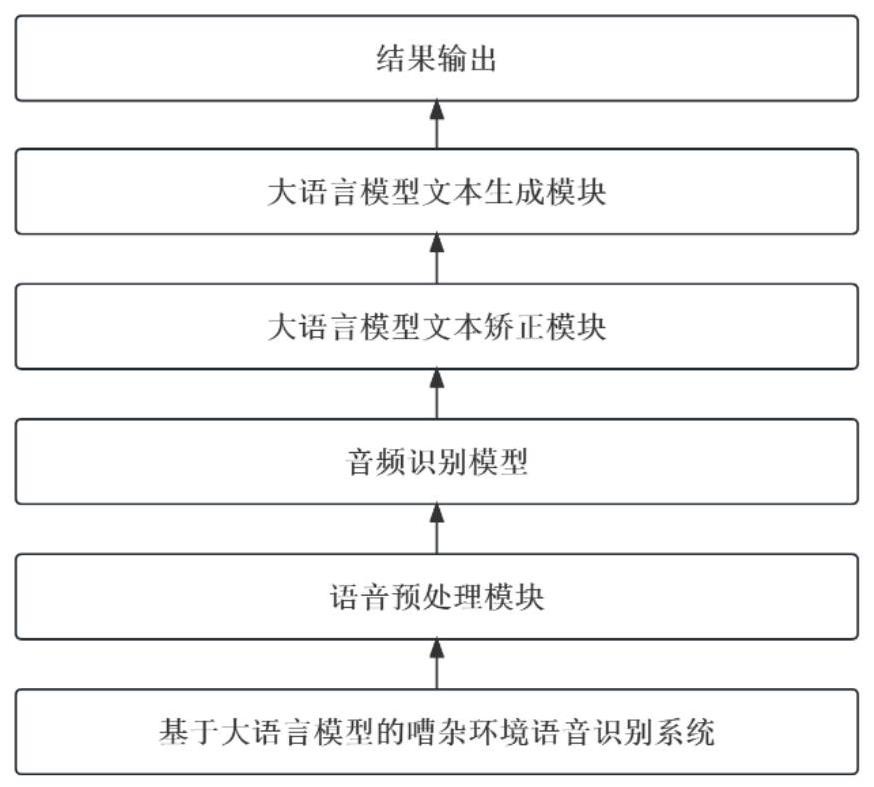
2、为实现以上目的,本发明通过以下技术方案予以实现:一种基于微调大语言模型在嘈杂环境下的语音识别方法,包括以下步骤;
3、步骤一、将音频文件传输至音频预处理模块进行初步处理;
4、步骤二、经过音频进行预处理后将音频传输入至音频识别模块生成文本;
5、步骤三、将生成的文本输入大语言模型文本矫正模块对本文信息再次分析,检测和修正本文不自然之处,信息补全,并输出矫正后的文本;
6、步骤四、将矫正文本输入至大语言模型生成模块,将关键信息凝练出来,总结成录音内容的大纲和对话详情,且通过微调模块自动生成文本报告,在特定领域或特定地域下可通过用户授权系统收集到的文本进行参数微调;
7、步骤五、通过反馈模块将结果输出给使用者。
8、优选的,所述步骤一中,音频数据预处理模块对音频进行格式化处理,将音频统一转化为wav格式,并利用ai技术将语音进行降噪并去除环境背景音。
9、优选的,所述步骤二中还包括以下步骤,音频输入语音识别模块内采用paraformer语音识别模型生成初步的带有残缺、复杂的文本。
10、优选的,所述步骤二中,paraformer语音识别模型集成有语音检测和音频语义识别功能,并生成分段文本信息及对应音频文件内的时间点,初步生成的文本信息被输入到大语言模型识别模块,由后者补全对话信息,分析不同人说话角色,生成文本报告。
11、优选的,所述步骤三中,以chatglm2 6b为基础模型微调后生成set模型,并通过奖励模型的输出得到该回答的奖励,使用基于强化学习的近端策略优化算法对上一步得到的初始模型进行进一步的微调。
12、优选的,所述步骤三中通过set模型读取ars模型的输出,并输出经过矫正后的文本作为大语言模型生成模块的输入。
13、优选的,所述ai技术为dfsmn语音降噪模型对音频中除人声以外的环境噪声进行处理。
14、优选的,所述步骤四中,以chatglm2 12b作为基础模型且使用特定领域的数据集来进行微调,微调方式和大语言模型矫正模块相同。
15、优选的,所述步骤四中,在处理特定领域场景下产生的专有名词时,使用向量数据库来存储领域知识并以规则处理转化成领域知识,存入向量数据库中。
16、优选的,所述步骤四中,对于数据保护和用户隐私,所有收集用于向量数据库的文本数据都将进行严格的加密和匿名处理,只有在用户明确授权的情况下,才会用于处理和存储,并且这些数据只用于提升模型的回答。
17、本发明提供了一种基于微调大语言模型在嘈杂环境下的语音识别方法。具备以下有益效果:
18、本发明可以在嘈杂环境下可以通过分析音频中各声源的发声者,总结并凝结音频中的事件,准确提取音频的语义信息,并通过大语言生成模块能够随时调整模型的输出结果,利用上下文信息帮助系统更高效判断后续语音的语义;使用向量数据库的大语言模型能够准确识别专业领域的术语、专有名词,以及在对话的过程中出现的方言,在特定领域语音识别更精准,为音频处理行业技术提升提供了新思路,为服务行业服务质量提升提供了新工具,也有助于提升社会大众在嘈杂环境下交流沟通的便利度;同时在获取用户授权后,能够自动采集用户相关数据,针对每个用户自动生成专有的大模型提示词,实现不同场景下更高效的语义处理,从而对于音频的处理更加细致准确,能有效降低部分应用场景下的人力成本,实现了更高效的语音语义解析记录,提高工作效率,实现降本增效。
技术特征:1.一种基于微调大语言模型在嘈杂环境下的语音识别方法,其特征在于,包括以下步骤;
2.根据权利要求1所述的一种基于微调大语言模型在嘈杂环境下的语音识别方法,其特征在于,所述步骤一中,音频数据预处理模块对音频进行格式化处理,将音频统一转化为wav格式,并利用ai技术将语音进行降噪并去除环境背景音。
3.根据权利要求1所述的一种基于微调大语言模型在嘈杂环境下的语音识别方法,其特征在于,所述步骤二中还包括以下步骤,音频输入语音识别模块内采用paraformer语音识别模型生成初步的带有残缺、复杂的文本。
4.根据权利要求1所述的一种基于微调大语言模型在嘈杂环境下的语音识别方法,其特征在于,所述步骤二中,paraformer语音识别模型集成有语音检测和音频语义识别功能,并生成分段文本信息及对应音频文件内的时间点,初步生成的文本信息被输入到大语言模型识别模块,由后者补全对话信息,分析不同人说话角色,生成文本报告。
5.根据权利要求1所述的一种基于微调大语言模型在嘈杂环境下的语音识别方法,其特征在于,所述步骤三中,以chatglm2 6b为基础模型微调后生成set模型,并通过奖励模型的输出得到该回答的奖励,使用基于强化学习的近端策略优化算法对上一步得到的初始模型进行进一步的微调。
6.根据权利要求1所述的一种基于微调大语言模型在嘈杂环境下的语音识别方法,其特征在于,所述步骤三中通过set模型读取ars模型的输出,并输出经过矫正后的文本作为大语言模型生成模块的输入。
7.根据权利要求1所述的一种基于微调大语言模型在嘈杂环境下的语音识别方法,其特征在于,所述ai技术为dfsmn语音降噪模型对音频中除人声以外的环境噪声进行处理。
8.根据权利要求1所述的一种基于微调大语言模型在嘈杂环境下的语音识别方法,其特征在于,所述步骤四中,以chatglm2 12b作为基础模型且使用特定领域的数据集来进行微调,微调方式和大语言模型矫正模块相同。
9.根据权利要求1所述的一种基于微调大语言模型在嘈杂环境下的语音识别方法,其特征在于,所述步骤四中,在处理特定领域场景下产生的专有名词时,使用向量数据库来存储领域知识并以规则处理转化成领域知识,存入向量数据库中。
10.根据权利要求1所述的一种基于微调大语言模型在嘈杂环境下的语音识别方法,其特征在于,所述步骤四中,对于数据保护和用户隐私,所有收集用于向量数据库的文本数据都将进行严格的加密和匿名处理,只有在用户明确授权的情况下,才会用于处理和存储,并且这些数据只用于提升模型的回答。
技术总结本申请涉及语音识别技术领域,公开了一种基于微调大语言模型在嘈杂环境下的语音识别方法,包括以下步骤;步骤一、将音频文件传输至音频预处理模块进行初步处理;步骤二、经过音频进行预处理后将音频传输入至音频识别模块生成文本;步骤三、将生成的文本输入大语言模型文本矫正模块对本文信息再次分析,检测和修正本文不自然之处,信息补全,并输出矫正后的文本。通过自动化的方式,结合先进的音频处理技术和深度学习大语言模型,实现了高准确率的自动检测,能有效降低部分应用场景下的人力成本,实现了更高效的语音语义解析记录,提高工作效率,满足了不同场景和用户群体的多样化需求。技术研发人员:侯朝川,王振,王通受保护的技术使用者:郑州超级云计算有限公司技术研发日:技术公布日:2024/1/25本文地址:https://www.jishuxx.com/zhuanli/20240618/21197.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。