融合大语言模型的伪造语音检测方法、系统、设备及介质
- 国知局
- 2024-06-21 11:29:49
本发明涉及语音检测,特别是涉及一种融合大语言模型的伪造语音检测方法、系统、设备及介质。
背景技术:
1、伪造语音检测领域是针对语音合成或者转换系统伪造的语音进行真假检测,以判断是否为合成语音。目前针对融合大语言模型的伪造语音检测主要通过对合成的语音或转换系统伪造的语音进行真假检测,以此判断是否为伪造语音。
2、一类检测方法主要通过放大声学特征的差别进行融合大语言模型的伪造语音检测,上述声学特征为梅尔倒谱系数(mel-scalefrequency cepstral coefficients,mfcc),constant-q倒谱系数(constant-q cepstral coefficients,cqcc),线性频率倒谱系数(linear frequency cepstral coefficients,lfcc),耳蜗滤波器倒谱系数瞬时频率(cochlear filter cepstral coefficients-instantaneous frequency,cfcc-if)等;另一类检测方法主要通过训练神经网络结构自动检测伪造语音,例如,各种轻量型的卷积网络结构、图卷积网络结构、长短时记忆等。
3、由于上述方法只关注伪造语音在声学特征上与真实语音的差别,其鲁棒性与泛化性较差。基于此,本发明提出一种融合声学特征差异与检测模型的伪造语音检测方法以解决上述问题。
技术实现思路
1、本发明提供一种融合大语言模型的伪造语音检测方法、系统、设备及介质,以解决现有融合大语言模型的伪造语音检测系统鲁棒性和泛化性差的问题。
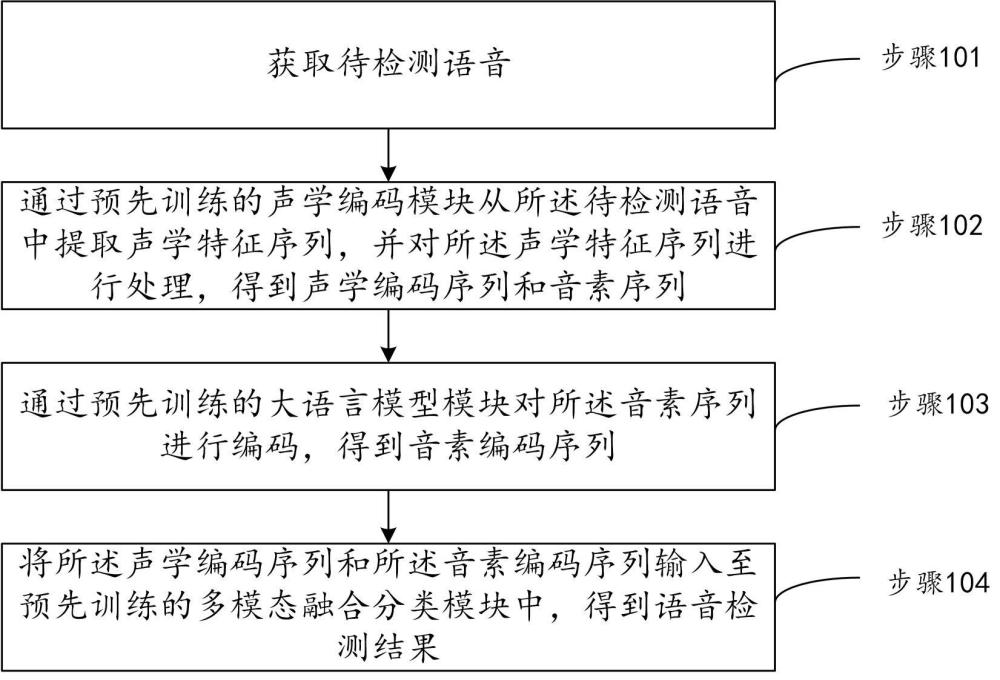
2、在本发明实施例第一方面提出一种融合大语言模型的伪造语音检测方法,所述方法包括:
3、获取待检测语音;
4、通过预先训练的声学编码模块从所述待检测语音中提取声学特征序列,并对所述声学特征序列进行处理,得到声学编码序列和音素序列;
5、通过预先训练的大语言模型模块对所述音素序列进行编码,得到音素编码序列;
6、将所述声学编码序列和所述音素编码序列输入至预先训练的多模态融合分类模块中,得到语音检测结果。
7、在本发明可选地一实施例中,所述声学编码模块的训练过程包括:
8、获取包含样本音频的训练数据集,以及每个样本音频对应的真实音素序列和所述真实音素序列的真实标签,所述真实音素序列为所述样本音频对应的真实文本信息,所述真实标签用于表征所述音素序列对应的样本音频为真;
9、基于所述训练数据集,通过声学特征提取和编码,得到样本声学编码序列;
10、识别所述样本声学编码序列的样本音素序列;
11、计算所述样本音素序列和所述真实音素序列之间的损失,得到损失值;
12、基于所述损失值优化所述声学编码模块中的参数,完成所述声学编码模块的训练。
13、在本发明可选地一实施例中,所述声学编码模块的训练过程具体包括:
14、获取所述样本音频的连续语音波形点,并将所述连续语音波形点分割为多个固定长度的短时样本音频;
15、提取多个所述短时样本音频的声学特征,得到样本声学特征序列;
16、对所述样本声学特征序列进行卷积降采样处理和初步编码,得到多个样本声学编码;
17、将多个所述样本声学编码输入至多头注意力声学编码器中,得到高维表示的所述样本声学编码序列;
18、对高维表示的所述样本声学编码序列进行识别,得到所述样本音素序列;
19、计算所述样本音素序列和所述真实音素序列之间的损失,得到所述损失值;
20、基于所述损失值优化所述声学编码模块的参数,完成所述声学编码模块的训练。
21、在本发明可选地一实施例中,所述对所述样本声学特征序列进行卷积降采样处理和初步编码,得到多个样本声学编码,包括:
22、采用多个2维卷积核对所述样本声学特征序列进行卷积操作,并通过设置卷积操作的步长来控制降采样处理的比例,得到卷积降采样后的所述样本声学特征序列;
23、通过激活函数对卷积降采样后的所述样本声学特征序列进行非线性变换,并叠加多层卷积操作,得到多个样本声学编码。
24、在本发明可选地一实施例中,所述多头注意力声学编码器包括多个堆叠的结构相同的模块,每个所述模块的结构包含多头自注意力层和全连接映射层,对每个子层进行层归一化操作,两个子层中间进行残差连接,每个所述模块之间进行残差连接;
25、所述将多个所述样本声学编码输入至多头注意力声学编码器中,得到高维表示的样本声学编码序列,包括:
26、对所述样本声学特征序列增加位置编码信息,并建模所述样本声学特征序列的时间先后顺序信息,得到具有时间先后顺序的样本声学特征序列;
27、将具有时间先后顺序的所述样本声学特征序列输入至所述多头注意力声学编码器中,依次经过所述多头自注意力层和所述全连接映射层,得到高维表示的所述样本声学编码序列。
28、在本发明可选地一实施例中,所述大语言模型为基于transformer结构的自回归语言模型,包括嵌入层、多层堆叠的transformer块,每个所述transformer块的结构相同,每个所述transformer块包含多头自注意力层和全连接映射层,对每个子层进行层归一化操作,两个所述子层中间进行残差连接,每个所述transformer块之间进行残差连接;所述大语言模型模块的训练过程包括:
29、获取样本音素序列和样本音素序列的样本标签,所述样本音素序列为所述预先训练的声学编码模块针对训练数据集生成的,所述样本标签用于表征所述样本音素序列对应的样本音频为真;
30、输入的所述样本音素序列经过所述嵌入层得到音素词嵌入向量表示序列;
31、对所述音素词嵌入向量表示序列增加位置编码信息,以及建模所述音素词嵌入向量表示序列的时间先后顺序信息,得到具有时间信息的音素词嵌入向量表示序列;
32、将所述具有时间信息的音素词嵌入向量表示序列输入至所述多层堆叠的transformer块,输出高维特征表示的样本音素编码序列;
33、采用所述大语言模型模块预测所述样本音素编码序列的标签,直至所述大语言模型模块预测的所述样本音素编码序列的标签与所述样本标签相同时,结束训练。
34、在本发明可选地一实施例中,所述多模态融合分类模块的训练过程如下:
35、初始化查询向量,以使所述查询向量的维度与样本声学编码序列和样本音素编码序列的维度相同,所述样本声学编码为所述预先训练的声学编码模块针对训练数据集生成的,所述样本音素编码序列为所述预先训练的大语言模型模块针对样本音素序列生成的;
36、采用所述查询向量分别对所述样本声学编码序列和所述样本音素编码序列中的每一个向量进行余弦相似度计算,通过归一化处理和加权处理后,得到融合特征;
37、对所述融合特征进行分类,得到所述样本音素序列对应的样本音频的预测结果;
38、当所述预测结果与样本标签相同时,结束训练,所述样本标签用于表征所述样本音素序列对应的样本音频为真。
39、基于同一发明构思,本发明实施例在第二方面提出一种融合大语言模型的伪造语音检测系统,所述系统包括:
40、获取模块,用于获取待检测语音;
41、处理模块,用于通过预先训练的声学编码模块从所述待检测语音中提取声学特征序列,并对所述声学特征序列进行处理,得到声学编码序列和音素序列;
42、编码模块,用于通过预先训练的大语言模型模块对所述音素序列进行编码,得到音素编码序列;
43、语言检测结果获取模块,用于将所述声学编码序列和所述音素编码序列输入至预先训练的多模态融合分类模块中,得到语音检测结果。
44、在本发明可选地一实施例中,所述系统还包括第一训练模块,所述第一训练模块包括:
45、第一获取子模块,用于获取包含样本音频的训练数据集,以及每个样本音频对应的真实音素序列和所述真实音素序列的真实标签,所述真实音素序列为所述样本音频对应的真实文本信息,所述真实标签用于表征所述音素序列对应的样本音频为真;
46、第一编码子模块,用于基于所述训练数据集,通过声学特征提取和编码,得到样本声学编码序列;
47、第一识别子模块,用于识别所述样本声学编码序列的样本音素序列;
48、第一损失计算子模块,用于计算所述样本音素序列和所述真实音素序列之间的损失,得到损失值;
49、第一优化子模块,用于基于所述损失值优化所述声学编码模块中的参数,完成所述声学编码模块的训练。
50、在本发明可选地一实施例中,所述第一训练模块具体包括:
51、第二获取子模块,用于获取所述样本音频的连续语音波形点,并将所述连续语音波形点分割为多个固定长度的短时样本音频;
52、提取子模块,用于提取多个所述短时样本音频的声学特征,得到样本声学特征序列;
53、第二编码子模块,用于对所述样本声学特征序列进行卷积降采样处理和初步编码,得到多个样本声学编码;
54、第三编码子模块,用于将多个所述样本声学编码输入至多头注意力声学编码器中,得到高维表示的所述样本声学编码序列;
55、第二识别子模块,用于对高维表示的所述样本声学编码序列进行识别,得到所述样本音素序列;
56、第二损失计算子模块,用于计算所述样本音素序列和所述真实音素序列之间的损失,得到所述损失值;
57、第二优化子模块,用于基于所述损失值优化所述声学编码模块的参数,完成所述声学编码模块的训练。
58、在本发明可选地一实施例中,所述第二编码子模块包括:
59、卷积单元,用于采用多个2维卷积核对所述样本声学特征序列进行卷积操作,并通过设置卷积操作的步长来控制降采样处理的比例,得到卷积降采样后的所述样本声学特征序列;
60、变换单元,用于通过激活函数对卷积降采样后的所述样本声学特征序列进行非线性变换,并叠加多层卷积操作,得到多个样本声学编码。
61、其中,所述多头注意力声学编码器包括多个堆叠的结构相同的模块,每个所述模块的结构包含多头自注意力层和全连接映射层,对每个子层进行层归一化操作,两个子层中间进行残差连接,每个所述模块之间进行残差连接,所述第三编码子模块包括:
62、第一编码单元,用于对所述样本声学特征序列增加位置编码信息,并建模所述样本声学特征序列的时间先后顺序信息,得到具有时间先后顺序的样本声学特征序列;
63、第二编码单元,用于将具有时间先后顺序的所述样本声学特征序列输入至所述多头注意力声学编码器中,依次经过所述多头自注意力层和所述全连接映射层,得到高维表示的所述样本声学编码序列。
64、在本发明可选地一实施例中,所述大语言模型为基于transformer结构的自回归语言模型,包括嵌入层、多层堆叠的transformer块,每个所述transformer块的结构相同,每个所述transformer块包含多头自注意力层和全连接映射层,对每个子层进行层归一化操作,两个所述子层中间进行残差连接,每个所述transformer块之间进行残差连接;所述系统还包括第二训练模块,所述第二训练模块包括:
65、第三获取子模块,用于获取样本音素序列和样本音素序列的样本标签,所述样本音素序列为所述预先训练的声学编码模块针对训练数据集生成的,所述样本标签用于表征所述样本音素序列对应的样本音频为真;
66、嵌入子模块,用于输入的所述样本音素序列经过所述嵌入层得到音素词嵌入向量表示序列;
67、第四编码子模块,用于对所述音素词嵌入向量表示序列增加位置编码信息,以及建模所述音素词嵌入向量表示序列的时间先后顺序信息,得到具有时间信息的音素词嵌入向量表示序列;
68、第五编码子模块,用于将所述具有时间信息的音素词嵌入向量表示序列输入至所述多层堆叠的transformer块,输出高维特征表示的样本音素编码序列;
69、预测子模块,用于采用所述大语言模型模块预测所述样本音素编码序列的标签,直至所述大语言模型模块预测的所述样本音素编码序列的标签与所述样本标签相同时,结束训练。
70、在本发明可选地一实施例中,所述系统还包括第三训练模块,所述第三训练模块包括:
71、初始化子模块,用于初始化查询向量,以使所述查询向量的维度与样本声学编码序列和样本音素编码序列的维度相同,所述样本声学编码为所述预先训练的声学编码模块针对训练数据集生成的,所述样本音素编码序列为所述预先训练的大语言模型模块针对样本音素序列生成的;
72、融合特征获取子模块,用于采用所述查询向量分别对所述样本声学编码序列和所述样本音素编码序列中的每一个向量进行余弦相似度计算,通过归一化处理和加权处理后,得到融合特征;
73、预测结果获取子模块,用于对所述融合特征进行分类,得到所述样本音素序列对应的样本音频的预测结果;
74、结束训练模块,用于当所述预测结果与样本标签相同时,结束训练,所述样本标签用于表征所述样本音素序列对应的样本音频为真。
75、在本发明实施例第三方面提出一种电子设备,包括存储器、处理器及存储在所述存储器上的计算机程序,所述处理器执行所述计算机程序以实现上述第一方面中任一项所述的融合大语言模型的伪造语音检测方法。
76、在本发明实施例第四方面提出一种计算机可读存储介质,其上存储有计算机程序/指令,该计算机程序/指令被处理器执行时实现上述第一方面中任一项所述的融合大语言模型的伪造语音检测方法。
77、本发明包括以下优点:本发明实施例提供一种融合大语言模型的伪造语音检测方法、系统、设备及介质,通过获取待检测语音;通过预先训练的声学编码模块从所述待检测语音中提取声学特征序列,并对所述声学特征序列进行处理,得到声学编码序列和音素序列;通过预先训练的大语言模型模块对所述音素序列进行编码,得到音素编码序列;将所述声学编码序列和所述音素编码序列输入至预先训练的多模态融合分类模块中,得到语音检测结果。上述方法不仅局限于声学特征信息的判断,还结合声学特征差异对应的音素序列进行判断,音素序列为存在于各种未知类型的伪造语音的音素文本信息,同时大语言模型具有强大的泛化性与模式识别能力,可以有效识别音素序列的模式,通过将声学信息和音素信息进行融合,以使检测方法同时具有强鲁棒性和对于伪造语音类型的强泛化性。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21848.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。