设备上的多用户认证的方法、系统和介质与流程
- 国知局
- 2024-06-21 11:29:54
本说明书一般地涉及自然语言处理。
背景技术:
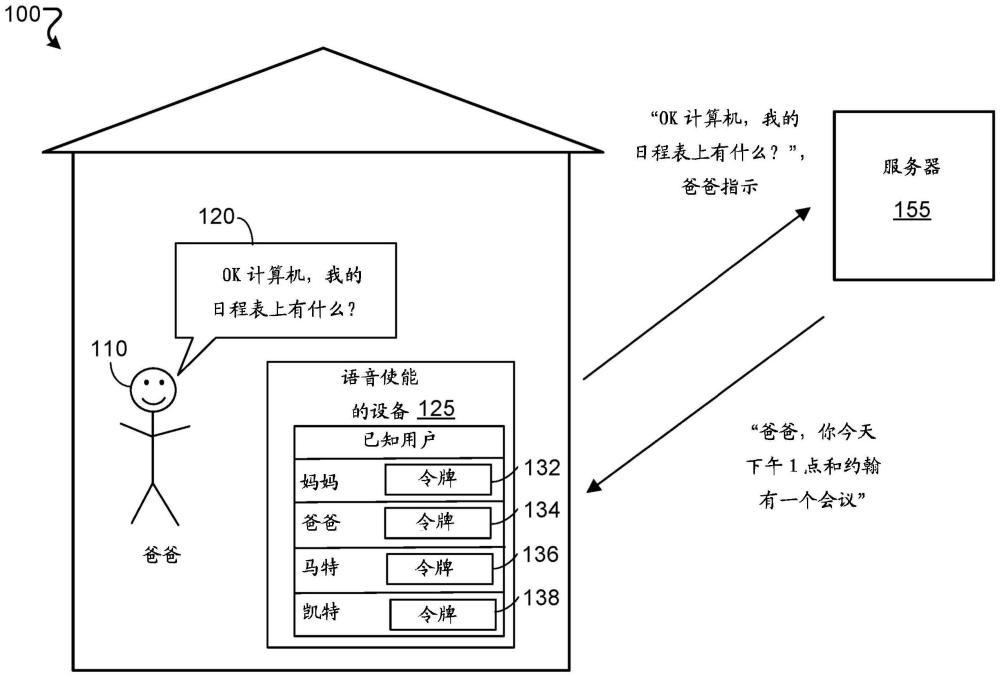
1、语音使能的设备可以提供针对来自用户的讲出的言语的可听的回答。这样的设备通常是用于所谓的数字助理软件或“数字助理”或“虚拟助理”的前端。这样的设备本身通常提供有限量的语音辨识功能性,并且与服务器或其它设备通信用于附加的资源。此外,这样的设备通常从服务器或其它设备(例如,响应于声音进入的查询或言语)接收转换为用户可听的合成语音的数据。例如,用户可以说“今天会下雨吗?”并且语音使能的设备可以可听地响应,“整天都会是晴天。”用户可以提供有关用户的个人信息的言语。例如,用户可以询问系统“我的日程表上有什么”,并且设备可以用在与设备相关联的日程表上的约会来响应。然而,常见的语音使能的设备不足以在各种用户之间区分,尤其当与对特定用户的个人信息的安全访问有关时,同时仍然准许由例如访客用户对语音使能的设备的一般使用。
技术实现思路
1、语音使能的设备可以由多个不同的用户使用。例如,放置在厨房案台上的语音使能的设备可以由约翰和简·多伊在家中使用。语音使能的设备的用户可以询问与用户的个人信息相关的问题。例如,约翰和简·多伊可以单独地询问语音使能的设备对于他们各自的日期安排什么。除约翰和简·多伊之外的用户(即“访客”)也可以询问语音使能的设备与用户的个人信息无关的问题。例如,访客用户可以询问语音使能的设备当前时间是什么。
2、为了处理来自多个不同用户的言语,语音使能的设备可以尝试将言语的发言者识别为特定用户,并且如果成功,则向服务器提供具有与所识别的特定用户对应的指示的查询,并且如果不成功,则向服务器提供不具有与所识别的特定用户对应的指示的查询。例如,语音使能的设备可以基于将言语辨识为与来自“约翰·多伊”的预先建立的语音模式匹配来将言语辨识为由“约翰·多伊”讲出,并且作为响应,向服务器提供包括言语的音频表示和言语由“约翰·多伊”讲出的指示两者的查询。
3、该组合准许虚拟助理软件访问约翰·多伊的个人信息以提供针对查询的响应。也可以发生查询重写以有助于该访问(例如,将初始查询“当天的日程上有什么”写为“[所识别的用户]的[日期]的日程上有什么”。同时,系统被配置为通过向服务器仅提供言语(该言语和一个或多个可能的发言者的识别(identification,“id”),但不具有已识别发言者的确认)、或者提供言语和某个其它指示(诸如设备id),准许由当事人(parties)而非以其它方式辨识的人员(例如,访客用户)来处理查询。
4、服务器可以使用特定用户的指示、或不具有这样的指示,来生成针对查询的响应。例如,服务器可以基于接收到由约翰·多伊讲出言语的指示来确定其具有用于响应于查询而提供适当的个人信息的权限。在针对今天的日程上有什么的示例请求中,这意味着服务器可以向用于发声的语音使能的设备提供约翰·多伊的约会的列表或摘要。在服务器确定查询不指示特定用户的识别但是查询正在寻求个人信息时,服务器可以指示不能够提供回答,因为用户对于语音使能的设备不是已知的。在又另一示例中,服务器可以确定即使与言语对应的查询(例如,“现在是什么时间”)不指示特定用户,查询与个人信息无关并且可以向语音使能的设备提供回复(例如,“现在是上午11点”)。
5、在用户提供查询时,语音使能的设备可以适应用户的声音的辨识。例如,为了辨识用户,语音使能的设备可以使用用户在注册过程期间讲话的样本和用户提供查询的近期样本的组合。语音使能的设备可以在设备确定相应用户讲出查询之后从查询生成相应用户的新的样本,并且然后使用该新的样本并且停止使用较旧的样本用于以后的辨识。附加地或替代地,可以在由特定用户使用的多个不同的语音使能的设备之间共享样本,使得当特定用户正在提供查询时,设备中的每一个类似地辨识。
6、在一些方面,本说明书中描述的主题可以体现在方法中,该方法可以包括以下动作:存储与设备的已知用户对应的认证令牌,接收来自发言者的言语,将言语分类为由已知用户中的特定已知用户讲出、并且使用特定已知用户的认证令牌来提供包括言语的表示和作为发言者的特定已知用户的指示的查询。
7、在一些方面,使用特定已知用户的认证令牌来提供包括言语的表示和作为发言者的特定已知用户的指示的查询包括提供包括认证令牌和指示言语被分类为由特定已知用户讲出的标记的查询。在某些方面,使用特定已知用户的认证令牌来提供包括言语的表示和作为发言者的特定已知用户的指示的查询包括提供包括特定已知用户的认证令牌的查询,其中在查询中包括特定已知用户的认证令牌指示言语被分类为由特定已知用户讲出。在一些实施方式中,存储与设备的已知用户对应的认证令牌包括存储设备的已知用户中的每一个的认证令牌,其中认证令牌中的每一个与已知用户中的相应一个对应。在一些方面,存储与设备的已知用户对应的认证令牌是作为用户注册为语音使能的设备的已知用户的响应。
8、在某些方面,将言语分类为由已知用户的特定已知用户讲出包括确定言语与对应于特定已知用户的语音匹配。在一些实施方式中,确定言语与对应于特定已知用户的语音匹配包括:确定言语包括预定短语,并且响应于确定言语包括预定短语,确定预定短语的言语与由特定已知用户的预定短语的先前言语匹配。在一些方面,将言语分类为由已知用户中的特定已知用户讲出包括确定对应于发言者的视觉信息与对应于特定已知用户的视觉信息匹配。
9、在某些方面,确定对应于发言者的视觉信息与对应于特定已知用户的视觉信息匹配包括:接收描述发言者的指纹、视网膜扫描、面部、或姿势中的一个或多个的发言者信息,并且确定发言者信息与对应于特定已知用户的视觉信息匹配。在一些方面,提供包括言语的表示和作为发言者的特定已知用户的指示的查询包括向服务器提供查询。在一些实施方式中,操作包括从服务器接收针对查询的响应并且向发言者提供响应。
10、在一些方面,本说明书中描述的主题可以体现在方法中,方法可以包括以下动作:存储与设备的已知用户对应的认证令牌,从发言者接收言语,将言语分类为不由已知用户中的任一者讲出、并且提供包括言语的表示并且不指示言语被分类为由已知用户中的特定已知用户讲出的查询。在某些方面,提供包括言语的表示并且不指示言语被分类为由已知用户中的特定已知用户讲出的查询包括提供包括认证令牌并且没有指示言语被分类为由已知用户中的特定已知用户讲出的标记的查询。在一些实施方式中,提供包括言语的表示并且不指示言语被分类为由已知用户中的特定已知用户讲出的查询包括提供不包括已知用户中的任一者的认证令牌的查询。
11、在一些方面,本说明书中描述的主题可以体现在方法中,方法可以包括以下动作:确定查询是否指示特定已知用户作为发言者,响应于确定查询是否指示特定已知用户作为发言者而确定查询不是来自已知用户,响应于确定查询不是来自已知用户而确定查询是否是非个人的,并且响应于确定查询是非个人的,尝试提供针对查询的响应。在某些方面,确定查询是否指示特定已知用户作为发言者包括:确定查询是否包括指示言语被分类为由特定已知用户讲出的标记。在一些实施方式中,确定查询是否指示特定已知用户作为发言者包括确定查询是否包括特定已知用户的授权令牌。在一些方面,响应于确定查询不是来自已知用户而确定查询是否是非个人的包括:响应于确定查询不是来自已知用户,确定针对查询的回答是否取决于个人信息。
12、在一些方面,本说明书中描述的主题可以体现在方法中,方法可以包括以下动作:至少基于特定用户讲出热词的样本的第一集合确定言语包括特定用户讲出热词,响应于至少基于特定用户讲出热词的样本的第一集合确定言语包括特定用户讲出热词来将言语的至少一部分存储为新的样本,获得特定用户讲出言语的样本的第二集合(其中样本的第二集合包括新的样本并且少于样本的第一集合中的所有样本)、并且至少基于用户讲出热词的样本的第二集合来确定第二言语包括特定用户讲出热词。
13、在某些方面,获得特定用户讲出言语的样本的第二集合(其中样本的第二集合包括新的样本并且少于样本的第一集合中的所有样本)包括选择预定数量的近期存储的样本作为样本的第二集合。在一些方面,获得特定用户讲出言语的样本的第二集合(其中样本的第二集合包括新样本并且少于样本的第一集合中的所有样本)包括选择预定数量的最近存储的样本和参考样本的集合两者以一起组合为样本的第二集合。在一些实施方式中,参考样本包括来自特定用户的注册过程的样本,并且最近存储的样本包括来自由特定用户讲出的查询的样本。
14、在某些方面,动作包括响应于获得样本的第二集合来删除在样本的第一集合中但不在样本的第二集合中的样本。在一些方面,至少基于特定用户讲出热词的样本的第一集合来确定言语包括特定用户讲出热词包括:使用样本的第一集合生成热词检测模型,向热词检测模型输入言语,并且确定热词检测模型已经将言语分类为包括特定用户讲出热词。在一些实施方式中,至少基于用户讲出热词的样本的第二集合来确定第二言语包括特定用户讲出热词包括使用样本的第二集合生成第二热词检测模型,将第二言语输入到第二热词检测模型,并且确定第二热词检测模型已经将第二言语分类为包括特定用户讲出热词。
15、在某些方面,动作包括从服务器接收第二新样本并且至少基于样本的第三集合确定第三言语包括特定用户讲出热词,样本的第三集合包括来自服务器的第二新样本并且少于样本的第二集合中的所有样本。在一些方面,动作包括:从服务器接收样本的第三集合中的样本的指示,确定样本的第三集合中不是本地存储的样本,向服务器提供针对样本的第三集合中不是本地存储的样本的请求,并且响应于该请求从服务器接收不是本地存储的样本。
16、在一些实施方式中,动作包括:向声音使能的设备提供样本的第一集合以使声音使能的设备能够检测出特定用户是否说出热词,其中至少基于特定用户讲出热词的样本的第一集合来确定言语包括特定用户讲出热词包括接收声音使能的设备检测出特定用户说出热词的指示。在某些方面,动作包括:使用样本的第一集合生成热词检测模型,并且向声音使能的设备提供热词检测模型以使声音使能的设备能够检测特定用户是否说出热词,其中至少基于讲出热词的特定用户的样本的第一集合来确定言语包括特定用户讲出热词包括接收声音使能的设备检测出特定用户说出热词的指示。
17、在一些实施方式中,动作包括:从声音使能的设备接收针对用于检测特定用户是否说出热词的样本的当前集合的请求,确定样本的当前集合中不是由声音使能的设备本地存储的样本,并且向声音使能的设备提供样本的当前集合中不是由声音使能的设备本地存储的样本和样本的当前集合中的样本的指示。
18、这一点和其它方面的其它实施方式包括对应的系统、装置、和计算机程序,其被配置为执行在计算机存储设备上编码的方法的动作。一个或多个计算机的系统能够凭借在系统上安装在操作中导致系统执行动作的软件、固件、硬件、或它们的组合来如此配置。一个或多个计算机程序能够凭借具有当由数据处理装置施行时引起装置执行动作的指令来如此配置。
19、可以实施本说明书中描述的主题的特定实施例,以便实现以下优点中的一个或多个。例如,通过使语音使能的设备向服务器提供包括言语的发言者的认证令牌的查询,系统可以使语音使能的设备能够由多个不同的用户共享并且提供针对言语的发言者的个性化的响应。在另一示例中,通过具有包括在语音使能的设备上存储的用于用户的多个或所有授权令牌并且指示哪个授权令牌对应于发言者、或是否没有授权令牌对应于发言者的查询,系统可以使服务能够在共享的语音使能的设备的用户之间共享。例如,如果处理查询的服务器接收到具有包括被准许使用音乐流服务的特定用户的认证令牌的令牌池的查询,则即使查询不指示特定用户讲出言语,服务器仍然可以响应于给出了存在特定用户的认证令牌的查询而准许使用音乐流服务。因此,系统可以保护针对特定用户的个人信息的访问,同时仍然准许由例如访客用户对语音使能的设备的一般使用。系统可以因此解决与数据安全性相关联的问题。系统可以附加地或替代地解决与在由多个不同用户使用的设备上如何提供个性化的用户交互相关联的问题。
20、在另一示例中,通过使系统基于用户讲出言语的新的样本来获得样本的不同集合,系统可以确保即使当由语音使能的设备接收到的音频中声音、口音、环境、或其它因素改变时当特定已知用户讲出言语时检测中的准确性。在又另一示例中,通过使系统在多个不同的语音使能的设备之间发送样本,系统可以使用户能够通过不必讲出来为语音使能的设备中的每一个提供参考样本而节省时间,并且也可以确保语音使能的设备中的每一个类似地检测已知用户讲出热词。因此,可以保存用户在第一注册之后通过讲话而提供参考样本所需要的处理。例如,系统可以确保如果特定言语被辨识为在已知用户的一个语音使能的设备上讲出,则该已知用户的所有语音使能的设备将类似地将该特定言语辨识为由该已知用户讲出。因此,可以增加针对已知用户的一致性和可预测性。
21、具体地,根据本技术的一方面,提供一种由一个或多个处理器实现的方法,包括:接收来自发言者的言语;确定发言者是由多个已知用户共享的用户设备的已知用户或不是用户设备的已知用户;确定该言语对应于个人请求还是非个人请求;和响应于确定发言者不是用户设备的已知用户,并且响应于确定言语对应于非个人请求:响应于该言语,使得对该言语的响应被提供以呈现给用户设备处的发言者,或者使得用户设备响应于该言语而执行动作。
22、根据本技术的一方面,提供一种由一个或多个处理器实现的方法,该方法包括:接收来自发言者的言语,该言语是在由语音使能的设备的一个或多个麦克风生成的音频数据中捕获的;基于处理捕获言语的音频数据,确定言语对应于个人请求还是非个人请求;响应于确定言语对应于个人请求:基于处理捕获言语的音频数据,确定发言者是语音使能的设备的已知用户或不是语音使能的设备的已知用户;和响应于确定发言者不是语音使能的设备的已知用户:使得注册过程被启动,当注册过程完成时,响应于从发言者接收到附加言语,使得发言者被识别为语音使能的设备的已知用户。
23、根据本技术的一方面,提供一种由一个或多个处理器实现的方法,该方法包括:接收来自发言者的言语;将言语的发言者分类为不是该设备的已知用户;向服务器提供查询,该查询包括对应于设备的已知用户的认证令牌、言语的表示以及发言者被分类为不是设备的已知用户的指示;和从所述服务器接收对所述查询的响应,所述响应是基于对应于所述设备的已知用户的认证令牌、所述言语的表示以及所述发言者被分类为不是所述设备的已知用户的指示而生成的。
24、根据本技术的一方面,提供一种计算机实现的方法,包括:由第一语音使能的设备接收捕获用户言语的一音频记录集合;由第一语音使能的设备基于该音频记录集合生成第一用户语音识别模型,供第一语音使能的设备在识别第一语音使能的设备随后接收的附加音频记录中的用户语音时使用;确定所述第一用户语音识别模型与特定用户账户相关联;接收第二语音使能的设备与特定用户账户相关联的指示;和响应于接收到第二语音使能的设备与特定用户账户相关联的指示:向第二语音使能的设备提供该音频记录集合;和由第二语音使能的设备基于该音频记录集合生成第二用户语音识别模型,用于识别第二语音使能的设备随后接收的附加音频记录中的用户语音。
25、根据本技术的一方面,提供一种计算机实现的方法,包括:至少基于从说出热词的特定用户的第一样本集合生成的第一热词检测模型,确定由第一语音使能的设备捕获的言语包括说出热词的特定用户;响应于至少基于从说出热词的特定用户的第一样本集合生成的第一热词检测模型确定言语包括说出热词的特定用户,选择言语的至少一部分作为新样本,以包括在说出热词的特定用户的第二样本集合中;和将说出热词的特定用户的第二样本集合提供给由特定用户使用的第二语音使能的设备,以从第二样本集合训练第二热词检测模型。
26、根据本技术的一方面,提供一种计算机实现的方法,包括:由一个或多个计算机至少基于从说出热词的特定用户的第一样本集合生成的第一热词检测模型来确定言语包括说出热词的特定用户;响应于至少基于从说出热词的特定用户的第一样本集合生成的第一热词检测模型确定言语包括说出热词的特定用户,将言语的至少一部分存储为新样本;获得说出该言语的特定用户的第二样本集合,其中第二样本集合包括新样本和少于第一样本集合中所有样本的样本;由所述一个或多个计算机至少基于从说出所述热词的用户的第二样本集合生成的第二热词检测模型,确定第二言语包括说出所述热词的特定用户;和响应于由一个或多个计算机确定第二言语包括说出热词的特定用户,将第二言语识别为已经由特定用户说出。
27、根据本技术的一方面,提供一种系统,包括:一个或多个处理器;和存储指令的存储器,当所述指令被执行时,所述一个或多个处理器可操作来执行所述任一项方法。
28、根据本技术的一方面,提供一种存储指令的非暂时性计算机可读存储介质,所述指令在被执行时使一个或多个处理器执行所述任一项方法的操作。
29、在附图和以下描述中阐述了本说明书中描述的主题的一个或多个实施方式的细节。从描述、附图、和权利要求,主题的其它特征、方面、和潜在优点将变得显而易见。
本文地址:https://www.jishuxx.com/zhuanli/20240618/21852.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。