一种基于深度卷积生成对抗网络的环境声音分类方法与流程
- 国知局
- 2024-06-21 11:33:52
本发明涉及人工智能,具体来说是一种基于深度卷积生成对抗网络的环境声音分类方法。
背景技术:
1、环境声音分类(esc)一直是音频信号处理的一个动态研究领域。环境声音是指日常生活中遇到的语音和音乐以外的任何自然发生的或机器生成的可听声音事件。近几年来,深度学习在解决语音识别、说话人识别与音乐识别等声学相关领域的问题上都展现出了极大的优势。esc任务虽与语音识别技术存在一定的差距,但二者是息息相关的。因此,深度学习方法应用到esc任务上也是非常适宜的,并且能够更好地解决esc技术中面临的一些问题,但当前esc任务的标记数据相对稀缺是限制这些算法性能的重要原因。虽然近年来已经发布了一些新的数据集,但它们仍然比可供研究的数据集要小得多,制约了esc技术的发展。
2、综上所述,esc技术隐藏着巨大的发展潜力,如何提高分类的准确率和效率,是该领域内亟待解决的问题,对于改善人们的生活质量具有极其深远的研究意义。
技术实现思路
1、本发明的目的是为了解决现有技术中esc识别率低、鲁棒性差的缺陷,提供一种基于深度卷积生成对抗网络的环境声音分类方法来解决上述问题。
2、为了实现上述目的,本发明的技术方案如下:
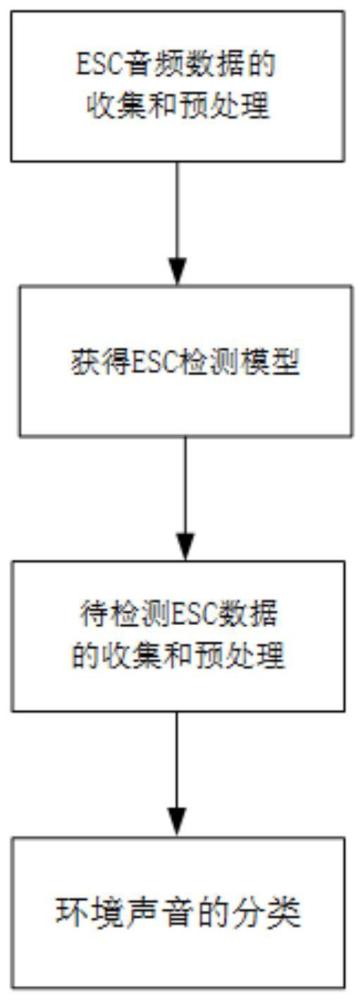
3、一种基于深度卷积生成对抗网络的环境声音分类方法,包括以下步骤:
4、11)esc音频数据的收集和预处理:将音频数据转化为语谱图作为训练图像,将所有训练图像的大小归一化为256×256像素,得到若干个训练样本;
5、12)esc分类检测模型的构建和训练:对条件变量下的图像判别网络、图像生成网络进行构造与对抗训练,根据训练后的图像判别器网络提取语谱图像对抗特征,并根据语谱图像对抗特征向量训练esc分类检测模型;
6、13)待检测esc音频数据的收集和预处理:获取待检测esc音频数据,转化为待测语谱图像并归一化为256×256像素,得到待检测图像样本;
7、14)环境声音分类结果的获得:将待检测图像样本输入训练完成后的esc分类检测模型,进行环境声音的检测,识别出不同类型的环境声音。
8、所述esc分类检测模型的构建和训练包括以下步骤:
9、21)构造带条件变量的图像判别网络模型d(x|c),c表示条件变量,设定为图像类别分布,损失函数为:
10、
11、x代表包含图像类别的原始训练样本,z代表高斯噪声向量,g(z|c)代表生成器生成的样本,e表示期望,d(x|c)表示对真实数据样本x,c是真实概率的估计,d(g(z|c))表示d对g生成的假数据样本为真概率的估计,d的目标是正确确定数据的来源,因此希望d(g(z|c))接近0,而g的目标是使其接近1;
12、图像判别网络模型以深度卷积神经网络模型为基础,设置网络层数为8层,其中前7层为卷积层、第8层为dense连接层,每个卷积层输出的特征通过激活函数leaky relu,引入非线性,同时经过phase shuffle技术对特征的通道维度进行随机的循环移位,以增加网络的鲁棒性和生成更加多样的输出,输出层的节点数为1,通过softmax分类器输出图像所属的类别概率;
13、22)构造带条件变量的图像生成网络模型g(z|c),z:pz(z)表示高斯噪声分布;c表示条件变量,设定为图像类别分布,损失函数为:
14、
15、图像生成网络模型以深度卷积神经网络模型为基础,设置网络层数为8层,其中第一层为dense层,中间为采样步幅为4,6层反卷积层,最后一层是采样步幅为3反卷积层,并通过tanh激活函数确保生成的样本在合适的范围之内,其公式为:
16、
17、23)条件变量下图像判别网络和图像生成网络的对抗训练,其具体步骤如下:
18、231)将图像判别网络模型d(x|c)和图像生成网络模型g(z|c)进行对抗训练,其训练模型如下:
19、
20、其中:x代表包含图像类别的原始训练样本,z代表高斯噪声向量,g(z|c)代表生成器生成的样本,e表示期望,d(x|c)表示对真实数据样本x,c是真实概率的估计,d(g(z|c))表示d对g生成的假数据样本为真概率的估计,pdata(x)是原始训练样本分布;x∈rdx、c∈rdc、dx、dc是训练样本的维数;
21、pz(z)表示高斯噪声分布n(μ,σ^2),其中μ、σ^2为分布的参数,分别为高斯分布的期望和方差;
22、c表示条件变量,服从分布n(α,δ^2),其中α、δ^2为分布的参数,设定为图像类别;
23、232)调整d(x|c)的参数;设有m个随机抽取的图像样本与噪声样本分布,xi为第i个图像样本,li为第i个图像样本对应的第i个噪声分布;
24、在训练的过程中,d(xi|ci)被显示为一个真实的语谱图像,通过调整其参数,让其输出值更低;
25、通过计算判别网络输出误差来调整参数,
26、使得误差达到阈值εd;
27、d(xi|ci)被显示为一个从g(zi|ci)产出的语谱图像,通过调整其参数,来让其输出d(g(z|c))更大;
28、通过计算生成网络输出误差来调整d(x|c)的参数,其公式如下:
29、使得误差达到阈值εg;
30、24)语谱图像的负样本的收集和预处理,收集若干幅非语谱图像作为训练图像,将所有训练负样本图像的大小归一化为256×256像素,得到若干个负样本;
31、25)语谱图像正负样本对抗特征提取,
32、将语谱图像训练样本及其负样本作为输入,输入到学习后的带条件变量的图像判别网络模型d(x|c),并将图像判别网络模型d(x,l)的深度卷积神经网络的第4层作为语谱图像正负训练样本的对抗特征输出;
33、26)收集语谱图像正负样本图像的对抗特征,组成对抗特征向量;
34、27)将对抗特征向量经过svm分类器训练,得到语谱图像检测模型,即esc分类检测模型。
35、所述环境声音分类结果的获得包括以下步骤:
36、31)针对待检测的语谱图像,大小为256×256像素;
37、以256×256像素大小为图像模板,逐行和逐列对待检测的语谱图像进行扫描,输入到学习后的带条件变量的图像判别网络模型d(x),得到该图像样本的对抗特征;
38、32)将该图像样本的对抗特征输入到esc检测模型,如果预测值小于0.5则判断为该图像为环境声音语谱图,并输出相应类别,否则不是。
39、有益效果
40、本发明的一种基于深度卷积生成对抗网络的环境声音分类方法,与现有技术相比将esc音频数据转化为语谱图像,通过图像判别网络模型与图像生成网络模型之间的对抗训练,增强了数据,提高了图像判别网络模型的识别能力,提高了esc识别率。通过图像生成网络模型的设定,不仅增加了大量esc数据集的训练样本,解决了环境声音种类复杂、采集样本困难的问题,还通过其自身训练,带动图像判别网络模型的再训练,从而提高图像判别网络模型的识别能力,实现esc的准确识别。
本文地址:https://www.jishuxx.com/zhuanli/20240618/22271.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表