模型训练方法、音频成分缺失识别方法、装置及电子设备与流程
- 国知局
- 2024-06-21 11:57:14
本技术涉及人工智能,具体而言,本技术涉及一种模型训练方法、音频成分缺失识别方法装置、电子设备、计算机可读存储介质及计算机程序产品。
背景技术:
1、随着互联网技术和5g基础设施建设的蓬勃跃进,视频作为一种媒介形式已经从众多信息载体中脱颖而出,并逐渐成为公众获取信息、交流互动的主流方式。
2、每日海量视频内容的上传,无疑为平台带来了丰富多元的信息传播,但也伴随着一系列关乎视频质量的重要挑战,其中,音频成分缺失问题尤为突出,无论是视频制作、传输过程中的技术失误,还是播放环节中因各种原因导致的某些音频成分缺失,都会严重影响用户的视听体验。
3、相关技术主要是基于音频信息信号的基础特性进行分析判断,依赖于对左右声道原始属性的直接对比,这类方法的核心手段是通过对双声道声音频信息谱特征的详尽分析,或是通过测量各自音量强度差异来确定声道间的不一致性,但实际应用时准确度较低。
技术实现思路
1、本技术实施例提供了一种模型训练方法、音频成分缺失识别方法、装置、电子设备、计算机可读存储介质及计算机程序产品,可以解决现有技术的上述问题。所述技术方案如下:
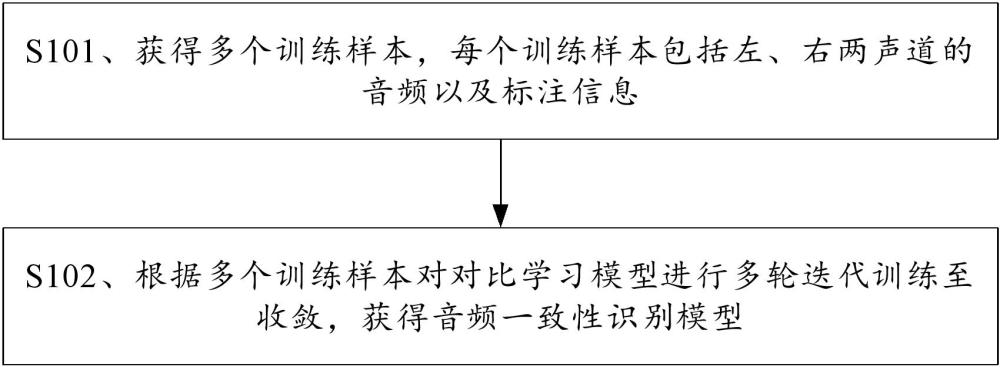
2、根据本技术实施例的第一个方面,提供了一种模型训练方法,该方法包括:
3、获得多个训练样本,每个训练样本包括左、右两声道的音频以及标注信息,一个训练样本的每个声道的音频的类型为原音频或者缺失音频,所述缺失音频是指缺失相应原音频中的一种音频成分的音频,所述标注信息用于指示相应训练样本中两声道的音频的类型是否一致;
4、根据所述多个训练样本,对对比学习模型进行多轮迭代训练至收敛,获得音频一致性识别模型。
5、根据本技术实施例的第二个方面,提供了一种音频成分缺失识别方法,包括:
6、将左、右声道的待检测音频输入至音频一致性识别模型,获得所述音频一致性识别模型输出的识别结果,所述识别结果用于指示所述左、右声道的待检测音频的类型是否一致;
7、若所述识别结果指示所述左、右声道的待检测音频的类型不一致,则确定左、右声道的待检测音频存在音频成分缺失;
8、其中,所述音频一致性识别模型是通过第一方面提供的模型训练方法训练而成的。
9、根据本技术实施例的第三个方面,提供了一种模型训练装置,该装置包括:
10、样本获得模块,用于获得多个训练样本,每个训练样本包括左、右两声道的音频以及标注信息,一个训练样本的每个声道的音频的类型为原音频或者缺失音频,所述缺失音频是指缺失相应原音频中的一种音频成分的音频,所述标注信息用于指示相应训练样本中两声道的音频的类型是否一致;
11、迭代训练模块,用于根据所述多个训练样本,对对比学习模型进行多轮迭代训练至收敛,获得音频一致性识别模型。
12、作为一种可选的实施方式,对比学习模型包括结构不相同的两个分支模型,每个分支模型用于对训练样本进行特征提取得到两声道的音频特征;
13、迭代训练模块包括:
14、相似度获得单元,用于将所述多个训练样本输入本轮迭代的对比学习模型,得到各个训练样本的第一相似度;每个训练样本的第一相似度包括一个分支模型得到的所述训练样本的任一声道的音频特征与另一个分支模型得到的所述训练样本的另一声道的音频特征间的第一子相似度;
15、损失值获得单元,用于获得本轮迭代训练的损失函数值,所述损失函数值包括各个训练样本的第一损失值,每个训练样本的第一损失值根据所述第一相似度和标注信息获得;
16、调整单元根据所述损失函数值调整所述对比学习模型的模型参数。
17、作为一种可选的实施方式,两个分支模型中的一个分支模型还用于在每轮迭代训练时,缓存本轮迭代得到的至少一个负样本的两声道的音频特征,作为至少一个参考音频特征对,所述负样本是指标注信息指示相应训练样本中两声道对应音频的类型不一致的训练样本;
18、相似度获得单元,还用于得到各个负样本的第二相似度,每个负样本的第二相似度包括每个分支模型得到的所述负样本每一声道的音频特征与预设数量的参考音频特征对中同一声道的音频特征间的第二子相似度;
19、损失函数值还包括各个负样本的第二损失值,每个负样本的第二损失值根据所述负样本的第二相似度获得。
20、作为一种可选的实施方式,相似度获得单元,还用于得到各个训练样本的第三相似度,每个训练样本的第三相似度表示一个分支模型得到的相应训练样本的两个声道的音频特征间的相似度;
21、损失函数值还包括各个训练样本的第三损失值,每个训练样本的第三损失值根据所述训练样本的第三相似度和标注信息获得。
22、作为一种可选的实施方式,每个训练样本的第一损失值通过以下方式获得:
23、若所述训练样本的标注信息指示相应训练样本中两声道的音频的类型一致,则将两个第一子相似度中的任意一个第一子相似度作为所述第一损失值;
24、若所述训练样本的标注信息指示相应训练样本中两声道的音频的类型不一致,则将两个第一子相似度中的任意一个第一子相似度的负值作为所述第一损失值。
25、作为一种可选的实施方式,每个负样本的第二损失值通过以下方式确定:
26、对于每个参考音频特征对,根据所述负样本与所述参考音频特征对相关的所有第二子相似度之和,获得所述负样本与所述参考音频特征对间的第四相似度;
27、确定所述负样本相对于各个参考音频特征对的第四相似度的均值,将所述均值的负值作为所述负样本的第二相似度。
28、作为一种可选的实施方式,每个训练样本的第三损失值通过以下方式获得:
29、若所述训练样本的标注信息指示相应训练样本中两声道的音频的类型一致,则将所述训练样本的第三相似度作为所述第三损失值;
30、若所述训练样本的标注信息指示相应训练样本中两声道的音频的类型不一致,则将所述训练样本的第三相似度的负值作为所述第三损失值。
31、作为一种可选的实施方式,每两个分支模型均包括用于提取初始音频特征的特征提取模块以及用于将初始音频特征映射至高维特征空间的特征变换模块;
32、其中,两个分支模型中特征变换模块的数量存在差异。
33、作为一种可选的实施方式,特征提取模块为vggish模块;
34、所述特征变换模块为投影仪projector模块。
35、作为一种可选的实施方式,样本获得模块包括:
36、初始音频对获得单元,用于获得至少一个初始音频对,所述初始音频对的左、右两声道的音频均为原音频;
37、音频成分确定单元,用于对于每个初始音频对,从所述初始音频对中每个声道的音频中确定各个音频成分;
38、屏蔽单元,用于对于每个初始音频对中每个声道的原音频,分别将所述原音频中的每种音频成分进行屏蔽,获得原音频对应的各个缺失音频;
39、组合单元,用于对于每个初始音频对,将所述初始音频对的两个声道的原音频和各个缺失音频进行组合,并根据组合的两个声道的音频的类型是否一致,设置对应的标注信息,以获得所述初始音频对对应的各个训练样本。
40、根据本技术实施例的第四个方面,提供了一种音频成分缺失识别装置,包括:
41、推理模块,用于将左、右声道的待检测音频输入至音频一致性识别模型,获得所述音频一致性识别模型输出的识别结果,所述识别结果用于指示所述左、右声道的待检测音频的类型是否一致;
42、识别模块,用于若所述识别结果指示所述左、右声道的待检测音频的类型不一致,则确定左、右声道的待检测音频存在音频成分缺失;
43、其中,所述音频一致性识别模型是通过第一方面提供的模型训练方法训练而成的。
44、根据本技术实施例的第五个方面,提供了一种电子设备,该电子设备包括存储器、处理器及存储在存储器上的计算机程序,处理器执行所述计算机程序以实现上述方法的步骤。
45、根据本技术实施例的第六个方面,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述方法的步骤。
46、根据本技术实施例的第七个方面,提供了一种计算机程序产品,包括计算机程序,计算机程序被处理器执行时实现上述方法的步骤。
47、本技术实施例提供的技术方案带来的有益效果是:
48、通过获得的多个训练样本,多个训练样本集中既包括了类型一致的音频对,也包括了类型不一致的音频对,同时既包括了包含原音频的音频对,也包括了包含缺失音频的音频对,样本的数量大幅提升,以此训练对比学习模型,对比学习模型所采用的对比学习主要为相似度的计算,在本技术实施例中也即左、右声道的音频的相似度,本技术既不需要对双声道的音频的特征进行详尽分析,对模型本身的运算能力没有很高的要求,同时也完全不同于简单地对音量强度进行判断的方式,对比学习模型能够尽量识别出音频是否进行过处理以及左右声道的音频类型是否一致,强化模型对原音频和处理后音频之间相关性的学习和理解,为后续根据模型输出的音频类型是否一致的识别结果,准确地获得音频成分是否缺失的判断结果奠定基础。
本文地址:https://www.jishuxx.com/zhuanli/20240618/24694.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表