嘈杂环境下听障人士汉语发音计算机辅助学习方法及装置
- 国知局
- 2024-06-21 14:11:47
本发明涉及学习设备,尤其是一种嘈杂环境下听障人士汉语发音计算机辅助学习方法及装置。
背景技术:
1、语音学习作为语言教育中一个至关重要的领域,持续吸引着广泛的关注。特别是聋哑人士在学习语言的过程中,他们面临着一系列独特的挑战,尤其是在掌握准确的语音发音方面。尽管现代听力辅助技术已经在一定程度上帮助聋哑人士在学习汉语发音方面改善了听觉体验,但在发音的精确度上仍然面临着挑战。目前,专门针对聋哑人士的语音学习工具还相对不足。
2、传统的语音学习方法很大程度上依赖于听觉反馈,但这种方法对于聋哑人士而言,并不总是奏效。随着计算机技术和人工智能的突飞猛进,计算机辅助的语言学习已经变成了一个备受瞩目的领域。尽管如此,市面上现有的语音学习工具大多集中于提升发音的准确性,而对于模拟真实语境和提供个性化指导的需求,这些工具尚未能够完全满足。
3、当前的语音学习工具主要集中于语音识别和发音训练两个方面。尽管传统的语音识别技术取得了一定的进步,但对于聋哑人这一特殊群体来说,仍然存在诸多挑战,如识别多样化的口音、纠正发音错误等。此外,发音训练往往局限于单一的发音元素,缺少对真实交流场景的模拟,这限制了工具为用户提供全面和实用的语音学习体验。在自然语言处理领域,尽管已经开展了拼音纠错和语法校正的相关研究,但这些技术在语音学习工具中的应用还不够广泛。现有的方法通常缺乏有效的抗噪音功能,难以从背景噪音中准确区分出用户的语音,这导致用户不得不在无噪音的环境中进行学习。这种限制对于聋哑人来说尤为突出,因为它极大地缩小了他们进行发音练习的时间窗口和地点选择。
4、传统工具难以提供一个符合聋哑人实际需求的学习环境。聋哑人在社会交往中经常感受到语言沟通的障碍,因此需要一种抗噪声的,更加综合和智能的语音学习方法。现有方法存在的不足如下:
5、1.缺乏场景模拟和实际应用性:大多数现有的语音学习工具集中于发音准确性的提高,但缺乏对真实场景的模拟。这使得学习者在实际语言运用中可能感到失落,无法将学到的知识灵活应用于日常生活对话中。
6、2.缺少个性化指导:现有技术在个性化指导方面存在不足。每位学习者的语音发音问题都是独特的,但现有工具通常未能提供精准的个性化反馈和指导,从而限制了学习效果的最大化。
7、3.忽视自然语言处理技术的应用:一些工具虽然提供了语音识别和发音练习,却忽视了自然语言处理技术在拼音纠错和发音要点搜索中的潜在应用。这导致了在语法和语境方面的理解不足。
8、4.对聋哑人群体的适应性不足:传统的语音学习工具主要设计用于能够听到声音的学习者,对于聋哑人这一特殊群体的适应性不足,无法有效解决他们的学习需求。
9、5.不具备抗噪音能力:传统语音学习工具要求用户在安静环境进行学习,难以区分用户语音和背景语音噪声,在噪声环境下表现差,限制了聋哑人的学习场景。
10、因此,亟需一种嘈杂环境下听障人士汉语发音计算机辅助学习方法,为聋哑人学习发音提供帮助。
技术实现思路
1、为了克服上述现有技术中缺乏适合聋哑人的汉语发音学习方法的缺陷,本发明提出了一种嘈杂环境下听障人士汉语发音计算机辅助学习方法及装置,通过模拟日常生活对话场景,结合先进的语音识别和自然语言处理技术,协助聋哑人随时随地学习和提高汉语拼音发音的准确性。
2、本发明提出的一种嘈杂环境下听障人士汉语发音计算机辅助学习方法:
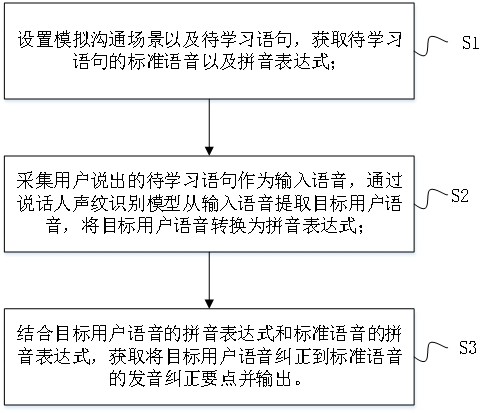
3、设置模拟沟通场景以及待学习语句,获取待学习语句的标准语音以及拼音表达式;
4、采集用户说出的待学习语句作为输入语音,通过说话人声纹识别模型从输入语音提取目标用户语音,将目标用户语音转换为拼音表达式;
5、结合目标用户语音的拼音表达式和标准语音的拼音表达式,获取将目标用户语音纠正到标准语音的发音纠正要点并输出;
6、说话人声纹识别模型包括顺序连接的声纹特征提取模块、注意力特征提取模块和分类器,声纹特征提取模块用于从输入语音中提取符合目标用户声纹特征的语音作为说话人语音;注意力特征提取模块用于提取说话人语音的注意力特征,分类器基于注意力特征对说话人语音进行分类;
7、说话人声纹识别模型的训练过程为:采用无监督学习方式对声纹特征提取模块进行预训练,然后组合预训练后的声纹特征提取模块、注意力特征提取模块和分类器作为基础模型,最后采用有监督学习方式对基础模型进行训练,固定收敛后的基础模型作为说话人声纹识别模型,其输入为语音数据,输出为目标用户语音。
8、优选的,声纹特征提取模块包括顺序连接的输入层,频率特征嵌入网络和上下文特征融合网络;输入层用于提取语音数据的时域信息并窗口化处理,频率特征嵌入网络从各窗口化的时域信息中提取语音的频率特征并生成指定长度的特征向量,上下文特征融合网络用于将频率特征嵌入网络输出的所有特征向量融合为上下文特征向量。
9、优选的,频率特征嵌入网络和上下文特征融合网络均采用多层卷积神经网络。
10、优选的,注意力特征提取模块包括顺序连接的卷积层、resnet特征提取网络、注意力层和全连接层。
11、优选的,分类器采用softmax分类器。
12、优选的,对采用无监督学习方式对声纹特征提取模块进行预训练时:在无噪音环境下采集的目标用户的语音作为正样本,对正样本进行窗口化处理后作为正样本训练数据;负样本的生成方式为:对正样本进行多频段调频以生成多个相同内容不同声纹的用户语音作为备选样本;将备选样本调频后再叠加随机噪声,形成负样本,再对负样本进行窗口化处理后作为负样本训练数据。
13、优选的,采用有监督学习方式对基础模型进行训练时,学习样本为标注说话人标签的样本数据;样本数据为:正样本、增强后的正样本、负样本或者增强后的负样本;正负样本的增强方式包括加混响、音频调速和/或频谱增强;说话人标签包括:目标用户以及非目标用户。
14、优选的,基于预先构建的汉语语音样本数据集,获取标准语音和目标用户语音的拼音表达式;汉语语音样本数据集用于存储标注有拼音表达式的语音样本,语音样本包括标准发音样本和发音障碍者的样本,拼音表达式涵盖声母、韵母和声调。
15、优选的,语音样本的拼音表达式通过预训练的语音转拼音模型生成,语音转拼音模型的输入为语音,输出为输入的语音的拼音表达式;语音转拼音模型包括特征提取模块、多层lstm深度学习架构、注意力机制模块和输出层;特征提取模块、多层lstm深度学习架构和输出层顺序连接,注意力机制模块设置在语音转拼音模型的输入端与输出层之间;特征提取模块用于提取输入语音的声学声调特征,多层lstm深度学习架构捕捉语音特征中声学声调特征的时序关系特征,注意力机制模块基于输入语音生成表征音节和声调变化的注意力特征,输出层基于时序关系特征和注意力特征生成输入语音的拼音表达式。
16、优选的,通过检索预先设置的发音纠错数据集获取将目标用户语音纠正到标准语音的发音纠正要点;发音纠错数据集存储有标注发音纠正要点以及参照语音向量的拼音组合,拼音组合包括待纠正语音的拼音表达式和纠正后标准语音的拼音表达式,参照语音向量为对应的拼音组合中两个拼音表达式合并后对应的标准语音的语音向量;
17、检索发音纠错数据集时,首先获取目标用户语音的拼音表达式与标准语音的拼音表达式构成的目标拼音组合,再将目标拼音组合中的两个拼音表达式合并后向量化,作为待检索语音向量,然后根据待检索语音向量与参照语音向量的相似度进行检索。
18、优选的,当待检索语音向量与参照语音向量的相似度达到设定的第二阈值,判断两者一致;当发音纠错数据集中不存在与待检索语音向量一致的参照语音向量时,根据以下步骤生成将目标用户语音纠正到标准语音的发音纠正要点;
19、在发音纠错数据集中筛选n个与待检索语音向量最相似的参照语音向量所指向的发音纠正要点作为待排序发音纠正要点;结合目标用户语音和标准语音,使用预训练的重排序模型对n个待排序发音纠正要点进行重排序;
20、将重排序后的发音纠正要点与目标用户语音、标准语音输入预训练的大语言模型,大语言模型输出最终发音纠正要点,用于将目标用户语音纠正到标准语音。
21、优选的,大语言模型输出最终发音纠正要点后,将目标拼音组合与最终发音纠正要点相关联增量存储到发音纠错数据集中,将待检索语音向量标注为目标拼音组合的参照语音向量。
22、本发明提出的一种采用所述的嘈杂环境下听障人士汉语发音计算机辅助学习方法的装置,包括:
23、场景诱导模块,存储有多种模拟沟通情境,用户在场景诱导模块选取模拟沟通情境;
24、语音输入模块,用于收集音频数据;
25、说话人声纹识别模块,用于从语音输入模块收集的音频数据中提取目标用户语音;
26、语音纠错模块分别连接场景诱导模块和说话人声纹识别模块,语音纠错模块用于生成目标用户语音的拼音表达式;语音纠错模块根据选取的模拟沟通情景对目标用户语音的拼音表达式进行拼音检查与纠正;
27、标准发音生成模块,根据纠正后的拼音表达式生成标准语音;
28、发音要点搜索模块,用于获取目标用户语音与标准语音的发音要点;
29、语音相似度判别模块,用于计算目标用户语音与标准语音的语音相似度;
30、纠音指导生成模块,结合语音相似度以及目标用户语音与标准语音的发音要点生成发音纠正要点并输出,发音纠正要点用于指导用户将目标用户语音的音调纠正为标准发音语音的音调。
31、本发明的优点在于:
32、1、本发明提出的嘈杂环境下听障人士汉语发音计算机辅助学习方法通过模拟沟通场景为听障人士提供真实生活对话场景的模拟,使得学习者在学习过程中能够更好地适应实际语境,增加学习的实用性和可操作性。本发明通过说话人声纹识别模型,能实现噪音背景环境下的目标用户语音信息精准提取,避免传统方法对发音学习环境安静的要求,极大方便了听障人士随时随地进行发音学习和训练。
33、2、本发明通过引入发音相似度计算,为学习者提供一个客观、量化的评估工具,将标准语音与学习者的原始语音进行对比,为用户提供具体的相似度得分,帮助用户更直观地了解自己的发音水平,从而有针对性地改进。
34、3、本发明提供了基于大模型和纠错数据集的纠错方法,可结合发音要点针对性的对用户语音进行发音细致矫正,深入分析用户的发音细节,特别是声母、韵母、声调等要素,提供更为准确和全面的纠正和指导,确保用户能够形成标准的语音发音。
35、4、本发明是针对听障人士群体的特殊需求,考虑到听障人士通过听力辅助设备获得语音信息的情况,设计的语音学习辅助工具,以确保对这一特殊群体的适应性和可用性。
36、5、本发明提出的嘈杂环境下听障人士汉语发音计算机辅助学习装置,为听障人士创造一个更方便、更智能、更具实际应用性的语音学习工具,有利于激发听障人士的学习热情,使用户能够更自信、更流利地参与社交和职业活动。本发明符合社会推动包容性和无障碍交流的愿景,促使听障人士更好地融入社会主流。
本文地址:https://www.jishuxx.com/zhuanli/20240618/36569.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表