一种基于深度强化学习的可解释的入侵响应决策方法
- 国知局
- 2024-07-30 09:23:16
本发明属于工业控制系统安全防御,涉及网络攻防博弈模型构建技术及网络入侵响应决策技术,特别涉及一种工业控制系统中基于深度强化学习的可解释的入侵响应决策方法。
背景技术:
1、现代工业控制系统(ics)通过将信息和通信技术与工业过程控制组件相结合,实现了工业控制过程的自动化运行与稳定运转。目前,已在电力、水力、石油和天然气、化工、废水处理和运输等工业方向有着广泛的应用,从而形成了世界性的关键基础设施。然而,随着ics与互联网的连接越来越紧密,ics遭受网络攻击的事件以惊人的速度增加,网络安全成为现代工业控制系统的主要问题之一。由于现代工业控制系统广泛应用于电力、化工、石油以及天然气等关键基础设施,一旦攻击者成功利用安全漏洞对工业控制系统中的物理设备发动攻击,就会造成严重的经济损失,甚至是人员伤亡。因此,提高ics的网络安全变得越来越重要。入侵反应是工业控制系统中的一个重要任务。为了防御网络攻击并减少其对工业控制系统所造成的不良影响,建立起对网络攻击的动态入侵反应决策系统至关重要。
2、早期的入侵响应系统的主流技术是设计警报信息与响应动作之间的静态映射。不幸的是,随着网络规模与复杂性的增加,维护这些静态映射变得越来越困难。相比之下,基于多目标优化、博弈论、强化学习的动态响应方法取得了更好的效果。然而,基于多目标优化方法过于依赖专家建模的服务依赖关系图与攻防树。基于博弈论的方法往往假设玩家是理性的,不考虑现实世界中的不确定性。尽管基于深度强化学习的入侵响应模型在训练与测试时表现出了良好的性能,但是往往不考虑物理过程对于系统的影响,并且可解释性较差,无法保证工业控制系统的平稳运行,不能直接部署在工业控制系统中。深度强化学习(drl)结合了深度学习的特征提取能力和强化学习的决策能力,可以直接根据输入的多维数据做出最优决策输出,是一种端对端的决策控制系统,广泛应用于动态决策、实时预测、游戏博弈等领域。其通过与环境不断地进行实时交互,将环境信息作为输入来获取失败或成功的经验来更新决策网络的参数,从而学习到最优策略。在工业控制系统仿真模型的基础上进行扩展,对工业控制系统网络攻防博弈场景进行了建模,将工业控制过程引入到博弈模型中,明确了状态空间、动作空间以及攻击者模型。之后,深度强化学习模型通过与博弈模型交互而对策略进行优化,有效地提升了入侵响应策略的效果。最后,使用模仿学习从优化后的策略中提取出可解释的决策树,作为最终的入侵响应策略。
技术实现思路
1、本发明所要解决的技术问题是提供一种基于深度强化学习的可解释的入侵响应决策方法,用于解决传统工业控制系统中无法有效对网络入侵行为进行响应的问题。
2、本发明解决上述技术问题的技术方案如下:一种基于深度强化学习的可解释的入侵响应决策方法,包括:
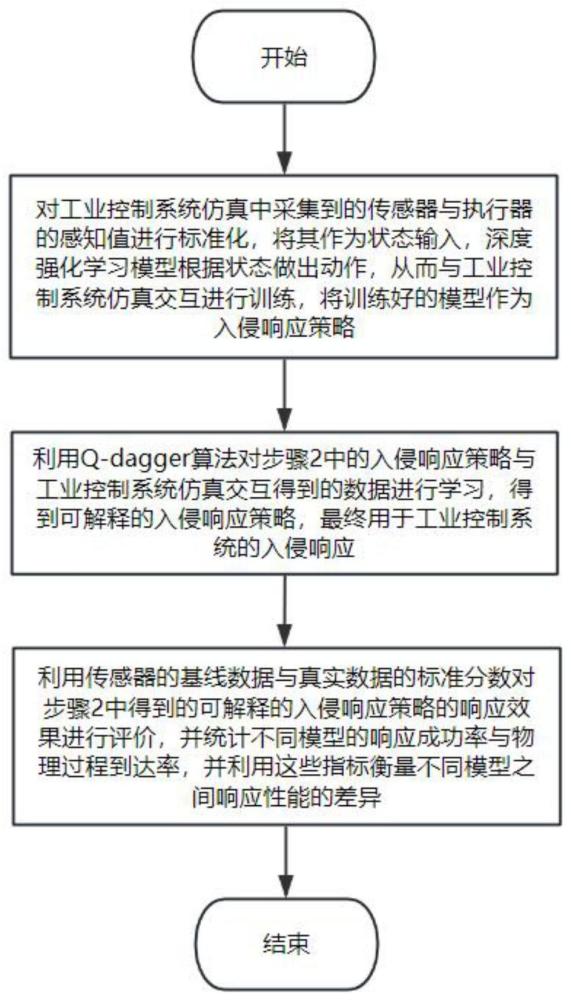
3、步骤1:对工业控制系统仿真中采集到的传感器与执行器的感知值进行标准化,将其作为状态输入,深度强化学习模型根据状态做出动作,从而与工业控制系统仿真交互进行训练,将训练好的模型作为入侵响应策略。
4、步骤2:利用q-dagger算法对步骤2中的入侵响应策略与工业控制系统仿真交互得到的数据进行学习,得到可解释的入侵响应策略,最终用于工业控制系统的入侵响应。
5、步骤3:利用传感器的基线数据与真实数据的标准分数对步骤2中得到的可解释的入侵响应策略的响应效果进行评价,并统计不同模型的响应成功率与物理过程到达率,并利用这些指标衡量不同模型之间响应性能的差异。
6、进一步,所述步骤1中对工业控制系统仿真中采集到的传感器与执行器的感知值进行标准化,将其作为状态输入,深度强化学习模型根据状态做出动作,从而与工业控制系统仿真交互进行训练,将训练好的模型作为入侵响应策略的过程具体包括:
7、步骤11,从工业控制系统仿真中获取传感器与执行器的感知值。
8、步骤12,对感知值进行标准化,将标准化后的感知值与网络节点警报结合作为状态。
9、步骤13,深度强化学习模型根据状态做出动作,从而与工业控制系统仿真交互进行训练。
10、进一步,所述步骤2中利用q-dagger算法对步骤2中的入侵响应策略与工业控制系统仿真交互得到的数据进行学习,得到可解释的入侵响应策略,最终用于工业控制系统的入侵响应的过程具体包括:
11、步骤21,利用深度强化学习模型生成的入侵响应策略与工业控制系统仿真交互获得初始轨迹数据集;
12、步骤22,对获得的轨迹数据集进行采样;
13、步骤23,使用采样后的数据集训练决策树;
14、步骤24,利用训练后的决策树与工业控制系统仿真交互以生成新的轨迹数据;
15、步骤25,利用深度强化学习模型生成的入侵响应策略对轨迹数据打上标签,并将新数据与旧数据集聚合;
16、步骤26,当训练轮数大于一定阈值后将最终生成的决策树作为可解释的入侵响应策略。
17、进一步,所述步骤3中利用传感器的基线数据与真实数据的标准分数对步骤2中得到的可解释的入侵响应策略的响应效果进行评价,并统计不同模型的响应成功率与物理过程到达率,并利用这些指标衡量不同模型之间响应性能的差异的过程具体包括:
18、步骤31,计算传感器的基线数据与真实数据的标准分数;
19、步骤32,统计不同模型的响应成功率;
20、步骤33,统计不同模型的物理过程到达率;
21、基于上述方法,本发明的技术方案还包括了一种工业控制系统中基于深度强化学习的可解释的入侵响应决策系统,包括:
22、基于深度强化学习的策略优化模块,其用于对工业控制系统仿真中采集到的传感器与执行器的感知值进行标准化,将其作为状态输入,深度强化学习模型根据状态做出动作,从而与工业控制系统仿真交互进行训练。
23、基于q-dagger算法的可解释策略生成模块,其用于将训练好的入侵响应策略作为教师,从中学习到可解释的入侵响应策略。
24、模型评估模块,用于以利用传感器的基线数据与真实数据的标准分数对可解释的入侵响应策略的响应效果进行评价,并统计不同模型的响应成功率与物理过程到达率,并利用这些指标衡量不同模型之间响应性能的差异。
25、进一步,所述基于深度强化学习的入侵响应策略优化模块包括:
26、数据处理模块,其用于将工业控制系统仿真中的数据进行标准化。
27、策略优化模块,其用于以处理过的数据对深度强化学习模型进行训练,生成入侵响应策略。
28、进一步,所述基于q-dagger算法的可解释策略生成模块包括:
29、数据采样模块,其用于对轨迹数据集中的数据进行带权采样。
30、可解释策略生成模块,其用于依据采样后的轨迹数据集训练决策树,生成可解释的入侵响应策略。
31、进一步,模型评估模块包括:
32、响应效果评估模块,用于计算传感器的基线数据与真实数据的标准分数。
33、响应性能评估模块,用于计算不同模型的响应成功率与物理过程到达率。
34、本发明的有益效果是:
35、一、本发明了利用深度强化学习模型完成入侵响应策略优化问题,仅依靠工业控制系统仿真学习攻击与防御动作之间的关联关系,避免了人工定义防御规则所需的大量的专家知识,实践证明,模型在响应效果和响应性能上的表现优于传统方法。
36、二、本发明利用q-dagger算法生成了可解释的入侵响应策略,缩小了入侵响应系统结果与实际入侵响应操作之间的语义差距,增强了管理员对决策结果的信心,并减少了入侵响应系统故障排除所需的工作量。实践证明,所生成的入侵响应策略具有很强的可解释性,并且在响应效果与响应性能上的表现优于传统方法。
37、三、本发明设计的物理过程到达率、成功率以及响应效果指标能够对入侵响应策略进行量化评价,增加网络管理这对入侵响应策略所做出决策的信任程度。
本文地址:https://www.jishuxx.com/zhuanli/20240730/149315.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表