一种基于视频流的运动人体目标检测方法
- 国知局
- 2024-07-31 22:43:11
本发明涉及视频处理和目标检测,涉及视频处理、深度学习、目标检测和运动分析等方面的技术。具体是一种基于视频流的运动人体目标检测方法。
背景技术:
0、技术背景
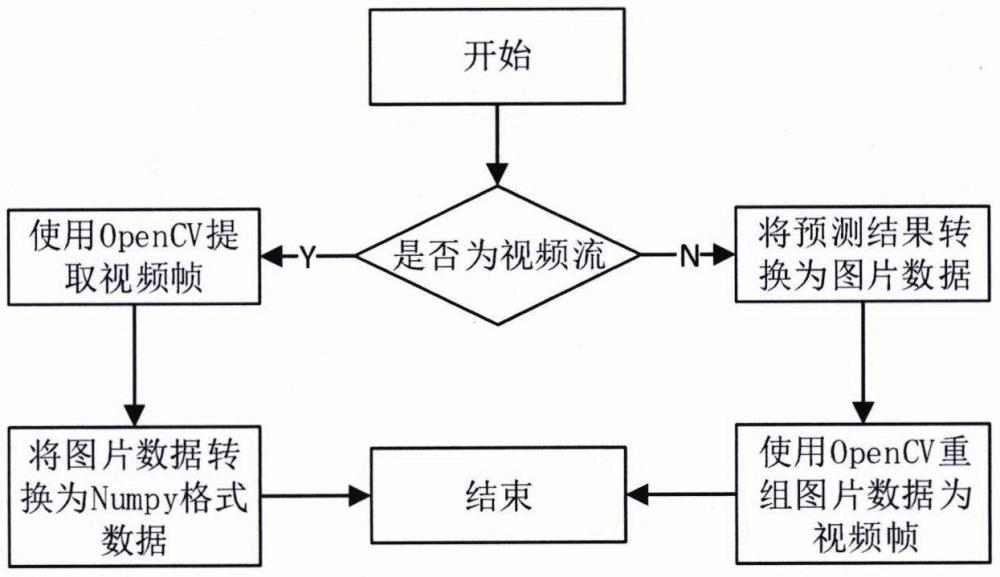
1、机器视觉在社会发展中扮演着重要角色,其中目标跟踪是关键内容之一。目标跟踪在生活、工业和军事等领域有广泛应用。然而,在视频目标跟踪中,目标遮挡经常发生,对准确度产生重大影响。因此,提高目标遮挡情况下跟踪算法的鲁棒性至关重要。传统算法通常基于目标外观特征(如颜色、纹理)进行跟踪,但遮挡情况下传统方法往往失败,导致跟踪器失去目标难以恢复。此外,快速移动的目标也带来挑战,因为快速运动会导致模糊、形变和缩放变化,改变目标外观特征。近年来,研究人员提出了基于深度学习的目标跟踪方法,利用深度神经网络学习目标特征表示,提高跟踪的鲁棒性和准确性。此外,通过引入时空信息、运动模型和上下文信息等先进技术,改善目标跟踪性能。然而,在某些复杂场景中目标遮挡或快速移动的挑战仍然存在。为此,本发明提出了一种基于离线视频流的运动行人目标检测方法及系统,全面描述视频中运动的行人目标外观,挖掘运动信息,克服传统运动检测的难题,提高行人检测准确率。
2、目前存在的目标检测方法在面对目标被遮挡或快速移动的情况下存在鲁棒性问题。在相关的背景技术中,我们发现了一些与本发明相关的现有技术,包括以下内容。
3、现有技术一:关键帧提取(参考季书成的专利)[1]
4、这项技术方案通过加速鲁棒特征(surf)的边权重计算方法,使用欧式距离和rbf核函数生成视频映射图的边权重,并进行图的建模。同时,该方法利用提取的初始关键帧与数据集关键帧进行实时比较,并调节视频映射图的边权重,实现智能提取。此外,知识蒸馏方法在该技术中被引用,通过构建网络、计算视频所有帧的表示形式,并利用简单的新网络计算帧表现形式。通过最小化新网络计算表现与网络计算表现之间的平方误差损失,该方法在保持关键信息提取准确性的同时显著减少了处理时间。
5、然而,现有技术一的缺点在于该方法计算精细耗时较长,更适用于提取帧间差异度高、亮度色彩变化较大的帧图像。对于处理视频内场景变化较小的超长视频而言,传统算法的适用性相对有限。
6、现有技术二:towards high performance video object detection[2]
7、这项论文提出了一种高性能视频目标检测方法。该技术方案首先针对视频流稀疏的关键帧,进行特征网络的计算,并通过递归特征传播将特征传递到下一个关键帧。接下来,对递归特征聚合的权重系数进行正则化,并得到关键帧的聚合特征图。
8、现有技术三:基于深度学习的视频行人目标检测[3]
9、该论文提出了一种基于深度学习的视频行人目标检测方法。该方法首先采用基于混合高斯模型的背景差算法,对当前帧图像进行运动前景提取,得到前景图。然后,及时更新混合高斯模型,并对权重进行归一化处理,按权重重新排序多个高斯模型。
10、现有技术四:基于视频流的运动人体行为识别研究[4]
11、在这项研究中,提出了一种基于视频流的运动人体行为识别方法。该方法采用三帧差分法检测视频的运动区域,构建运动视窗,并利用改进的c-v模型在运动视频范围内提取精确的运动人体轮廓。同时,该方法引入全局梯度信息演化活动轮廓曲线,根据闭合活动轮廓曲线内外部的梯度信息重新定义图像分割能量函数。
12、不过,现有技术四的缺点在于不能很好地区分目标与其影子,导致所得到的目标边界形状不能准确反映目标的实际形状。
13、因此,本发明提出了一种基于视频流的运动人体目标检测方法。该方案旨在利用特征对视频中的目标进行准确的识别、分类与跟踪,以解决在目标被遮挡或快速移动的情况下目标跟踪算法的鲁棒性问题。
14、本发明通过提取视频中的人体动作关键帧,并利用gmm背景建模实现前景与背景的有效分割。随后,使用基于混合高斯模型的背景差算法,从当前帧图像中提取运动前景。通过计算每个检测到的行人的运动得分,并对比得分情况,选取得分较高的一帧作为聚合特征图,用于快速检测视频中出现的行人目标。在这个过程中,本方法利用递归算法、归一化和聚合等技术,以提高目标元素检测的精度。
技术实现思路
1、针对现有技术的不足,本发明的目的是提供一种基于视频流的运动人体目标检测方法。
2、本发明要解决的技术问题为:
3、如何解决视频目标跟踪中的鲁棒性问题,特别是在目标被遮挡或快速移动的情况下。传统的目标跟踪方法在面对这些挑战时往往表现不佳,因此需要一种新的解决方案来提高目标在复杂场景下的识别、分类和跟踪准确性。
4、本发明的目的可以通过以下技术方案实现:
5、一种基于视频流的运动人体目标检测方法,分为以下三个模块:视频流与数据流的转换模块、目标检测网络的训练模块以及目标检测模块。
6、所述数据流转换模块负责逐帧采样视频信息并将其转换为图片信息。这些图片被重新定位到适合作为深度网络模块输入的尺寸。此外,数据流转换模块将深度网络输出的预测结果转换成相应的边界框(bounding box)和目标类别。然后,它将边界框和类别名称叠加在对应帧的图片上,并最终将数据流转换为视频流输出到指定目录。
7、所述目标检测网络的训练模块负责构建适当的深度网络,并将损失函数最小化。
8、所述目标检测模块负责在视频信息上进行实时计算,以满足目标检测任务的实时性要求。它将经过训练模块训练完成的深度网络加载到支持快速、并行浮点运算的gpu中。然后,该模块接收来自视频流与数据流转换模块的矩阵数据(由视频流转换而来),并将该数据输入gpu中的网络结构,从而完成预测任务。
9、进一步地,对本方法具体步骤做详尽的介绍:
10、视频的关键帧提取。采用以下步骤实现智能关键帧提取算法:
11、灰度化预处理:将彩色图像转换为基于亮度的单通道灰度图像,通过减少图像中的噪点来加速卷积运算。
12、聚散熵运动目标检测:使用聚散熵来区分联合梯度运动目标的结果。对于没有运动目标的子镜头,聚散熵相对较大;当运动目标出现时,聚散熵急剧减小,并在有运动目标的子镜头中保持较低的熵值;当运动目标移出画面时,聚散熵又急剧增大。以0到1的上升沿开始,以1到0的下降沿结束,标记了视频子镜头的边界,实现了视频的子镜头分割。
13、构建关键帧图:将每个子镜头的每一帧抽象为一个顶点,并使用顶点之间的连线构成边。每个子镜头可以被视为一个平面上的无向加权图。图中的边权重反映了两个顶点之间的相似程度,即两帧之间的相似程度。边权重的计算采用基于加速鲁棒特征(surf)的方法。首先,利用hessian矩阵的值判断是否为极值点,然后使用surf算法计算每个采样点的haar小波响应,并将其累加形成特征向量,用于描述图像特征点。通过基于欧式距离和rbf核函数的方法,生成视频映射图的边权重,并建立关键帧数据集。随后,通过实时比较提取的初始关键帧和数据集关键帧,并根据视频类型返回相应的参数向量来调节视频映射图的边权重,从而实现最终关键帧的智能提取。
14、需要具体说明的是,本网络方案旨在实现对视频的批量处理和编码。具体而言,该方案通过提取视频的所有帧(以f0,f1,...,fn=1表示)并对视频进行编码。随后,编码视频传入一个简单的前馈神经网络,该网络包含一个多类输出层,每个输出类别对应一个y类标签。网络的参数通过使用标准的多标签分类损失函数lce进行学习,该损失函数是每个y类标签之间交叉熵损失的总和。我们称此损失函数为lce,其中ce表示真实标签y与预测标签y之间的交叉熵损失。
15、
16、进一步地,采用以下步骤进行图像前景与背景的分割与gmm运动检测:
17、gmm背景建模:使用采集的光照下背景图像进行gmm背景建模。然后,将提取的关键帧图像输入gmm模型,获得gmm运动检测结果。在gmm模型中,对运动前景进行提取。
18、采用基于混合高斯模型的背景差算法对当前帧图像进行运动前景提取,得到的前景图记为l。在该算法中,用<w,model>表示一个权重为w的单高斯模型。假设图像中坐标为(x,y)的点处的混合高斯模型为model={<wi,modeli>},i=1,2,...,num}(其中num表示混合高斯模型所包含的单高斯模型的数目),则前景提取的公式如下:
19、
20、在上式中,i0代表当前输入的原始图像,θ代表前景提取的阈值。阈值可以是固定的值,也可以是自适应的(例如,可以选择所有权重中的次小值作为阈值)。
21、运动检测与模型更新:采用基于混合高斯模型的背景差算法对当前帧图像进行运动前景提取。根据混合高斯模型的权重、均值和方差来判断像素点是否与模型匹配。根据匹配与否,更新高斯模型的均值和方差。模型更新后对权重进行归一化处理,并按权重大小重新排序。
22、根据检测结果,按照以下公式对混合高斯模型进行及时更新:
23、wi←(1-α)ωi+αmi(x,y)
24、μi←(1-ρ)μi+ρi(x,y)
25、
26、在上式中,μi为第i个高斯模型<wi,modeli>的均值,为第i个高斯模型的方差。α为混合高斯模型的学习率,且0≤α≤1,背景模型的更新速度取决于α的取值。m(x,y)表示像素点与<wi,modeli>匹配与否,匹配则为1,否则为0。当不匹配时,不对高斯模型的均值和方差进行更新。
27、模型更新后对权重进行归一化处理,并对多个高斯模型按照权重高低重新排序。
28、行人运动得分计算:根据运动检测结果,计算行人的运动得分。根据行人检测结果中每个目标在当前图像中的区域,计算行人的运动得分。如果运动得分大于给定阈值,则认为是正确检测到的行人目标;否则,认为是虚警目标,并从检测结果中去除。对于正确检测的行人目标,使用当前前景区域边界作为目标检测结果的输出,并进行边界修正。
29、
30、
31、进一步地,采用以下步骤进行行人目标的检测:
32、边界框预测:对每个边界框预测四个坐标值(xmin,xmax,ymin,ymax)。通过对当前图像的每个单元格进行预测,记行人检测结果中第i个目标为ti,行人ti的运动得分si计算方式如下:
33、
34、ai=(xmax-xmin+1)·(ymax-ymin+1)
35、
36、若si大于给定阈值,则认为t为正确检测到的行人目标,反之,则认为ti为虚警目标,从检测结果中去除。在此处所使用的阈值是指前景区域占目标区域面积的比例。如果检测到了行人目标且阈值正确,则此算法将使用当前前景区域的边界作为目标检测结果输出,以实现对目标检测边界的修正。修正后的检测结果将被输出。
37、分类:对每个边界框进行分类,采用多标签分类方法。使用逻辑回归进行分类,并使用二值交叉熵损失进行训练。
38、特征提取:对于视频中稀疏的关键帧,需要计算特征网络并将特征传播到下一个关键帧。对于两个连续的关键帧,通过递归特征聚合的方式进行特征传播。递归特征聚合通过权重系数进行特征图的加权求和,其中权重系数需要进行正则化。通过不断递归聚合特征信息,可以计算出所有关键帧的聚合特征图。
39、需要具体说明的是,对于视频流稀疏的关键帧,要计算特征网络nfcat和递归特征传播到下一个关键帧,对于两个连续的关键帧k和k′,从关键帧k传播到关键帧k′的递归特征聚合方式用如下公式表示:
40、
41、其中,θ表示权重系数与特征图中对应的每个位置p使用eltw-multiplication操作。
42、为了实现特征的递归聚合和权重系数的正则化,使用如下公式来处理权重系数与特征图中每个位置的乘法操作,类似于密集特征聚合中的权重系数的正则化方式。具体公式如下:
43、wk→k′(p)+wk→k′(p)=1
44、需要具体说明的是,聚合得到的关键帧k的特征图是由之前所有关键帧中行人运动得分最高的特征信息聚合而成的。因此,递归的含义在于通过公式将特征信息与fk′进行聚合生成接着再通过递归生成下一个关键帧的聚合特征图。通过不断递归的方式,计算出所有关键帧的聚合特征图。
45、目标检测和跟踪:使用已训练好的目标检测器对聚合特征图进行行人目标检测,通过对聚合特征图进行目标检测,可以获取每个行人目标的边界框和置信度得分。
46、将当前帧中检测到的行人目标与前一帧中跟踪到的行人目标进行匹配。匹配可以基于目标框之间的iou(交并比)进行。匹配成功的目标被视为已跟踪的行人,并更新其位置信息。对于新检测到的行人目标,分配新的跟踪器进行跟踪。跟踪过程可以使用相关滤波器或卡尔曼滤波器等跟踪算法实现。
47、将跟踪到的行人目标的位置信息和相应的置信度得分输出为最终的行人目标检测结果。可以使用边界框和置信度得分来标识每个行人目标,并在视频中进行可视化展示或进一步的分析和处理。
48、与现有技术相比,本发明有益效果在于:
49、本发明以离线视频中运动的行人目标为针对点,提出了一种基于离线视频流的运动行人目标检测的方法及系统,一方面是可以对视频中的行人目标准确、全面的外观描述;二是可以挖掘行人目标运动信息,克服传统运动检测出现空洞、易受阴影、光照变化影响等难题,提高行人检测准确率。
50、本发明将待进行目标检测的视频进行人体动作关键帧提取后通过gmm背景建模实现了前景与背景的分割。然后采用基于混合高斯模型的背景差算法对当前帧图像进行运动前景提取后,通过计算每个检测到的行人的运动得分,然后,根据得分情况的比较,选出得分高的一帧作为聚合特征图对目标进行检测,实现快速视频中出现的行人目标。该方法在进行视频目标检测过程中使用了递归算法和归一化、聚合等方法,有利于提高目标元素检测的精度。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194269.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表