一种基于改进Transformer的手写英文识别方法、系统
- 国知局
- 2024-07-31 22:48:48
本发明涉及光学字符识别,具体涉及一种基于改进transformer的手写英文识别方法、系统。
背景技术:
1、ocr(optical character recognition,光学字符识别)是计算机视觉研究的一个热点,它旨在将文本图像转换为可编辑的数字文本文档,为后续的自动数据输入、自然语言处理等操作提供支持。随着智能教育的发展,电子阅卷的需求变多,通过ocr将学生的手写英语作文识别为可编辑文本至关重要。学生的手写英文字体风格强烈,字符之间常出现涂改,插入现象,因此,传统的ocr技术不能很好地应用于手写英文图像识别。
2、目前英文文本识别领域主要有两个数据集研究方向:一种是公共场景下的英文文本识别,场景复杂,但字体风格单一;另一种是对风格多变的手写英文文本识别,手写英文文本由于书写者不同的书写习惯,书写风格,存在字体容易形变,字符之间分割边缘不明显和字符识别特征不明显等问题。
3、近年来,对手写英文图像双模态进行图像文本内容识别已经取得了一些成果,许多研究表明基于多模态的识别方式性能优于单模态,引入语言模型确实能够提高文本识别的准确性,但手写英文图像识别终究是要以图像视觉特征为主,因此,在双模态处理机制的基础上,如何更近一步的进行图像特征的提取成为了手写英文文本识别的研究难点和热点。
4、传统的特征提取方式往往局限于单独的cnn和transformer网络进行特征提取,但是前者容易导致对图像的局部细节关注过强,得到的模型泛化能力差;对于后者,transformer对于图像整体的特征细节把握较强,而对于局部的图像特征细节把握不足,难以挖掘图像局部之间的依赖关系。
技术实现思路
1、本发明所要解决的技术问题是:提供一种基于改进transformer的手写英文识别方法,通过在编码模块引入排列语言建模单元且在解码模块引入反向残差局部特征提取单元,通过双模态处理机制引入更多的语义信息,完善了手写英文任务的处理,并且同时考虑了手写英文文本字体的特殊性,在transformer模型的框架下引入反向残差局部特征提取单元,更好的关注图像的细节特征,有效提高了手写英文识别的准确率。
2、为了解决以上技术问题,本发明采用如下技术方案:
3、一种基于改进transformer的手写英文识别方法,包括以下步骤:
4、s1、获取手写英文图像。
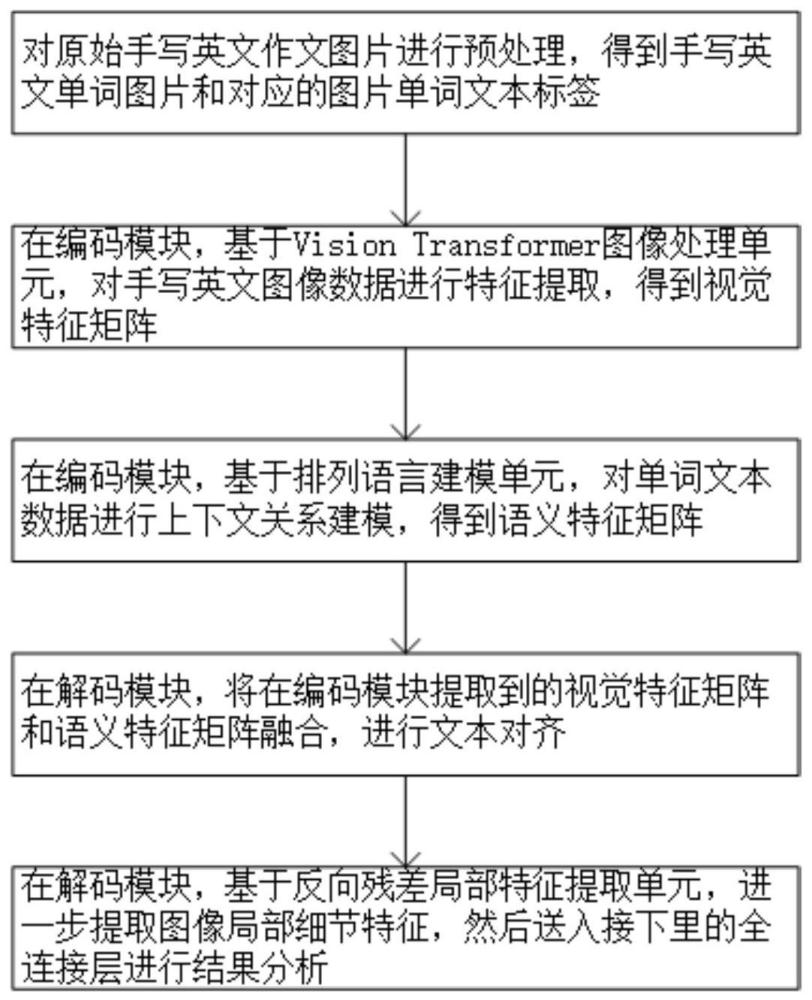
5、s2、对手写英文图像进行预处理,得到单词图像和单词图像文本标签;其中,单词图像文本标签包括单词图像的位置信息和文本内容。
6、s3、构建预设编码模块、预设解码模块和预设分析模块;其中预设编码模块包括第一提取单元和第二提取单元,第一提取单元包括图像嵌入部分和12层的transformer编码层,第二提取单元包括排列语言模型和多头注意力网络;预设解码模块包括多头注意力单元、反向残差局部特征提取单元。
7、s4、利用第一提取单元,对单词图像进行图像特征提取,得到视觉特征矩阵。
8、s5、利用第二提取单元,对单词图像文本标签进行排列语言建模,得到语义特征矩阵。
9、s6、将视觉特征矩阵和语义特征矩阵对齐,输入到预设解码模块中,得到联合反向残差特征矩阵。
10、s7、将联合反向残差特征矩阵输入到预设分析模块中,获得预测概率分布。
11、s8、基于预测概率,对预设编码模块、预设解码模块和预设分析模块进行调整,利用调整后的模块,重复步骤s4-s7的内容,选取每个英文字母类别中概率最高的标记作为手写英文识别的预测结果。
12、进一步的,步骤s2中,得到单词图像和图像单词文本标签包括以下内容:
13、框选手写英文图像的单词,提取整张手写英文图像中的单词图像和对应的文本标签,根据位置信息,裁剪出单词图像,设定单词图像的尺寸以及单词最大的长度。
14、进一步的,步骤s4中,得到视觉特征矩阵包括以下子步骤:
15、s401、将单词图像分割成块,输入到第一提取单元中,通过图像嵌入部分进行映射,得到第一特征矩阵;第一特征矩阵包括单词图像的特征向量。
16、s402、利用12层的transformer编码层将第一特征矩阵编码为第二特征矩阵。
17、s403、对第二特征矩阵通过layer normalization方式,进行归一化,得到视觉特征矩阵。
18、进一步的,步骤s5中,得到语义特征矩阵包括以下子步骤:
19、s501、将单词图像文本标签输入到第二提取单元中,利用排列语言模型进行字母排列,提取单词图像的语义特征,并映射到26*384维的连续向量空间,编码成向量,得到第三特征矩阵;第三特征矩阵包括所有单词图像文本标签的特征向量。
20、s502、利用多头注意力网络,将第三特征矩阵转变为第四特征矩阵。
21、s503、利用layer normalization方式对第四特征矩进行归一化,得到语义特征矩阵。
22、进一步的,步骤s6中,得到联合反向残差特征矩阵包括以下子步骤:
23、s601、将视觉特征矩阵和语义特征矩阵对齐后输入到预设解码模块中,利用多头注意力单元,得到图像和单词文本对齐的特征联合矩阵。
24、s602、将特征联合矩阵中的视觉特征矩阵提取出来,得到优化的视觉特征矩阵a,将矩阵a复制一份,得到优化的视觉特征矩阵b。
25、s603、利用1*1卷积内核对优化后的视觉特征矩阵a进行卷积,同时利用扩展因子μ增加该矩阵中图像的通道数,得到第一视觉特征矩阵,引入了更多的特征表示。
26、s604、利用3*3卷积内核对第一视觉特征矩阵进行卷积,步长为1,填充为1,提取详细局部特征,得到第二视觉特征矩阵。
27、s605、利用1*1卷积内核,并且将输出通道数除以μ,减少第二视觉特征矩阵中图像的通道数,得到第三视觉特征矩阵。
28、s606、对第三视觉特征矩阵进行标准化操作,得到标准化后的第三视觉特征矩阵;
29、s607、为了防止数据的过度拟合和神经信息的传递损失,将优化的视觉特征矩阵b输入到反向残差局部特征提取单元中,与标准化后的第三视觉特征矩阵相加,得到反向残差视觉特征矩阵。
30、s608、将反向残差视觉特征矩阵与特征联合矩阵中的语义特征矩阵融合,得到联合反向残差特征矩阵。
31、进一步的,步骤s7中,获得预测概率分布包括以下内容:
32、将联合反向残差特征矩阵输入到预设分析模块中,利用该模块中的神经元,将输入的矩阵映射到输出标签的空间上,再经过softmax函数激活,将输出值转换为0到1之间的数值,得到每个英文字母类别的预测概率分布,每个字母类别中的概率总和为1。
33、进一步的,步骤s8中,模块调整包括以下内容:
34、将预测概率分布与真实标签概率分布进行比较,通过交叉熵损失函数计算损失值;根据上一次的损失值,利用优化算法梯度下降法调整预设编码模块、预设解码模块和预设分析模块中的权重参数,当模型收敛,损失值保持不变时停止调整,得到调整后的模块。
35、进一步的,本发明还提出了一种基于改进transformer的手写英文识别的系统,包括:
36、图像预处理模块,用于获取手写英文图像,对该图像进行预处理,得到单词图像和单词图像文本标签;其中,单词图像文本标签包括单词图像的位置信息和文本内容。
37、模块构建模块,用于构建预设编码模块、预设解码模块和预设分析模块;其中预设编码模块包括第一提取单元和第二提取单元,第一提取单元包括图像嵌入部分和12层的transformer编码层,第二提取单元包括排列语言模型和多头注意力网络;预设解码模块包括多头注意力单元、反向残差局部特征提取单元。
38、矩阵提取模块,用于利用第一提取单元,对单词图像进行图像特征提取,得到视觉特征矩阵;利用第二提取单元,对单词图像文本标签进行排列语言建模,得到语义特征矩阵;将视觉特征矩阵和语义特征矩阵对齐,输入到预设解码模块中,得到联合反向残差特征矩阵。
39、预测概率分布获取模块,用于将联合反向残差特征矩阵输入到预设分析模块中,获得预测概率分布。
40、预测结果获取模块,用于基于预测概率,对预设编码模块、预设解码模块和预设分析模块进行调整,利用调整后的模块,块,重复矩阵提取模块和预测概率分布获取模块中的内容,选取每个英文字母类别中概率最高的标记作为手写英文识别的预测结果。
41、进一步的,本发明还提出了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现前文所述的一种基于改进transformer的手写英文识别方法的步骤。
42、进一步的,本发明还提出了一种计算机可读的存储介质,所述计算机可读的存储介质存储有计算机程序,所述计算机程序被处理器运行时执行前文所述的一种基于改进transformer的手写英文识别方法。
43、本发明采用以上技术方案与现有技术相比,具有以下技术效果:
44、本发明提出的方法采用双模态处理机制。一方面,在编码模块引入排列语言建模单元对单词文本进行排列,为模型引入更多的语义信息;另一方面在解码模块引入了反向残差局部特征提取单元,在transformer框架下引入深度卷积,结合两者优势,既利用transformer全局建模的优势,也利用了卷积神经网络关注图像局部细节的能力,有效的提升了手写英文文本识别的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194754.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。