面向裁判文书的文档级法律关系抽取模型产品及方法
- 国知局
- 2024-07-31 22:50:12
本发明属于法律文本的自然语言处理,更具体地,涉及一种面向裁判文书的文档级法律关系抽取模型产品及方法。
背景技术:
1、法律文本如裁判文书包含了丰富的法律信息,如案件事实、法律依据、裁判结果等。文档级关系抽取的核心任务是自动从法律文本中识别并抽取实体间的复杂关系,包括但不限于案件当事人、法律条款及案件事实之间的相互作用和依存关系。这些关系对于理解裁判文书的内容和意图,深度分析和理解案件信息,提高案件审理的准确性和效率具有重要意义。
2、目前,面向裁判文书的法律关系抽取的研究成果集中在句子级关系抽取方法上,无法覆盖跨越数个句子乃至段落的实体间关系,因此难以分析长文本裁判文书。这主要受制于裁判文书中存在多被告与多罪名、案件特征交叉以及文书结构复杂等特点,现有的句子级关系抽取技术无法充分理解并精准抽取。
3、因此,需要研究一种新的方法来解决面向裁判文书的文档级法律关系抽取的问题,以提高抽取的准确性和效率,降低司法实践中文书处理的复杂度。
技术实现思路
1、针对现有技术的以上缺陷或改进需求,本发明提供了一种面向裁判文书的文档级法律关系抽取模型产品及方法,其目的在于解决面向裁判文书的文档级法律关系抽取的问题。
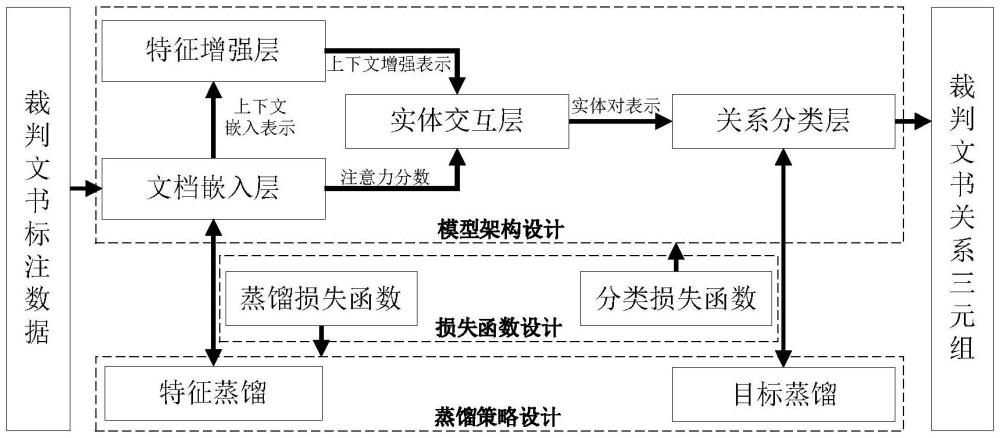
2、为实现上述目的,按照本发明的一个方面,提供了一种面向裁判文书的文档级法律关系抽取模型程序产品,该文档级法律关系抽取模型包括:
3、文档嵌入层,用于在给定裁判文书文档中标注所有实体,在实体边界标注特殊字符作为该实体在文档中的一个提及,在句子结尾插入句子所属章节结构信息;然后将该文档输入lawformer预训练模型中,获取文档的上下文嵌入表示和注意力分数;
4、特征增强层,用于使用双向门控循环单元对所述文档的上下文嵌入表示进行深层次的特征提取,得到增强的文档上下文表示;
5、实体交互层,用于遍历所述增强的文档上下文表示中的两两实体构成实体对,计算实体的向量表示,利用所述注意力分数对实体对中向量表示的两个实体进行融合增强和特征组合,得到增强的实体对;
6、关系分类层,包括线性分类层、激活函数层和关系预测层,所述线性分类层用于计算增强的实体对所属的所有关系类别的概率矩阵即logits,所述激活函数层用于根据logits计算该实体对属于每个关系类别的概率即logit;所述关系预测层用于将各logit与预设的关系类别门限值进行比较,由此判定将哪些关系类别归属于给定的实体对,从而得到裁判文书文档中的实体对-关系三元组集合。
7、优选地,所述lawformer预训练模型为:
8、dpe=lawformer([t1,t2,…,tl])=[c1,c2,…,cl]
9、其中,dpe是lawformer预训练模型编码输出的最后一层的最终隐藏状态也即输出的文档的上下文嵌入表示,layer是lawformer预训练模型编码输出包含的层数,[t1,t2,…,tl]表示输入的插入特殊符号和章节结构信息后的文档d#,ti表示文档d#中位置为i的token,ci是文档d#中第i个token的嵌入表示,1≤i≤l,l是文档d#的长度,dim是lawformer预训练模型的隐藏层维数,表示维度为layer×l×dim;dpa为lawformer预训练模型编码输出的最后一层的注意力分数。
10、优选地,实体交互层中,通过文档中每个实体提及对应的特殊符号实现从增强的文档上下文表示中提取得到实体提及的嵌入表示,通过logsumexp池化聚合同一实体的提及获得对应的实体嵌入即实体的向量表示ei:
11、
12、其中,表示实体ei的实体提及数目,mi,j表示i个实体ei的第j次提及,ei、表示维度为dim;
13、通过平均池化实体ei所有提及的注意力分数得到实体ei的聚合注意力分数
14、
15、其中,aei、表示维度为h×l;
16、计算实体对<eh,et>的上下文向量
17、
18、其中,是实体eh的聚合注意力分数中h个注意力头中第i个注意力分数,是实体et的聚合注意力分数中h个注意力头中第i个注意力分数,是db的转置矩阵,db是特征增强层得到的增强的文档上下文表示;
19、将与实体嵌入eh和et融合得到当前实体对中两个实体的增强表示:
20、
21、
22、其中,wh、wt、均为可训练的权重矩阵,eh、tanh是双曲正切函数;
23、通过分组双线性函数对eh和et进行特征组合得到增强的实体对
24、
25、
26、
27、
28、其中,1≤j≤k,k表示将eh和et分别拆分为k组大小相等的向量矩阵,表示eh拆分出的第j组向量矩阵,表示et拆分出的第j组向量矩阵,和bi分别为对应组向量矩阵的权重矩阵和标量偏置。
29、优选地,所述线性分类层的计算公式为:
30、
31、其中,是增强的实体对对应的logits值,c为关系类别数目,wl是将实体对嵌入映射到每个关系类别的logit的权重矩阵,bl是偏置矩阵;
32、使用激活函数δ得到实体对<eh,et>中关系类别为ri的logit即p(ri|<eh,et>)为:
33、
34、按照本发明的另一个方面,还提供了一种面向裁判文书的文档级法律关系抽取模型构建方法,包括如下步骤:
35、s1、利用裁判文书人工标注数据对随机初始化的教师模型进行训练,训练至分类损失函数收敛得到教师模型权重所述分类损失函数为自适应焦点损失函数和标签分布感知边距损失函数的线性组合;
36、s2、将加载至教师模型,利用裁判文书远程标注数据对教师模型进行微调训练,得到教师模型权重且保留对应的教师软标签logitst;logitst为教师模型的关系分类层中计算得到的logits;
37、s3、将教师软标签logitst和裁判文书远程标注数据绑定,然后对随机初始化的学生模型进行训练,训练至蒸馏损失函数收敛,得到学生模型权重所述蒸馏损失函数为特征蒸馏函数和目标蒸馏函数的线性组合;
38、s4、将加载至学生模型,并利用裁判文书人工标注数据进行学生模型微调训练,得学生模型权重
39、s5、将加载至学生模型,得到训练好的文档级法律关系抽取模型;
40、其中,教师模型与学生模型的结构相同,均采用上述的文档级法律关系抽取模型。
41、优选地,所述分类损失函数lcls为:
42、lcls=laf+αlldam
43、其中,α为控制标签分布感知边距损失函数的损失的权重参数,自适应焦点损失函数laf为:
44、
45、其中,是正类的集合,自适应阈值类rth表示教师模型对每个实体对-关系三元组学习到的动态判断边界,使得每个实体对中关系ri的p(ri)大于rth的p(rth)的关系类别视为正类,其余的视为负类,p(ri)、p(rth)分别为关系类别为ri、rth的logit值;τ为超参数;
46、标签分布感知边距损失函数lldam为:
47、
48、其中,定义实体对-关系三元组<h,r,t>,h和t为实体,r为对应实体对的关系类别标签,pr表示h和t的实体对中关系类别为r的logit,γr是关系类别r的边距。
49、优选地,所述蒸馏损失函数lhsd为:
50、lhsd=ltd+βlfd
51、其中,β是控制特征蒸馏函数损失的权重参数;特征蒸馏函数lfd为:
52、
53、其中,ft和fs分别表示加载了的教师模型和随机初始化训练的学生模型建模的裁判文书文档的上下文嵌入表示dpe;
54、目标蒸馏函数ltd为:
55、
56、其中,crossentropy是交叉熵函数,是加载了的教师模型对h和t实体对计算的logits,为加载了的学生模型对h和t实体对计算的logits。
57、按照本发明的另一方面,还提供了一种面向裁判文书的文档级法律关系抽取方法,将裁判文书文档输入上述面向裁判文书的文档级法律关系抽取模型构建方法得到的训练好的文档级法律关系抽取模型中,得到该裁判文书文档中的实体对-关系三元组集合。
58、按照本发明的另一方面,还提供了一种电子设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时执行上述的面向裁判文书的文档级法律关系抽取模型构建方法,和/或,上述的面向裁判文书的文档级法律关系抽取方法。
59、按照本发明的另一方面,还提供了一种计算机可读存储介质,包括存储的计算机程序,所述计算机程序被处理器执行时,控制所述计算机可读存储介质所在设备执行上述的面向裁判文书的文档级法律关系抽取模型构建方法,和/或,上述的面向裁判文书的文档级法律关系抽取方法。
60、总体而言,通过本发明所构思的以上技术方案与现有技术相比,本发明提供的技术方案主要具有以下有益效果:
61、1.本发明提供了一种基于lawformer的文档级法律关系抽取模型架构设计方法,模型架构由文档嵌入层、特征增强层、实体交互层以及关系分类层组成。文档嵌入层主要是利用lawformer对裁判文书进行深度的上下文编码及特征提取,将文档数据转化为序列向量形式,为后续处理打下基础。特征增强层主要是将文档嵌入层编码得到的上下文嵌入表示向量通过bigru进行更深层次特征挖掘,进一步丰富文本序列的语义表示。实体交互层依托于注意力机制和增强的文档表示,通过学习实体间的动态互动特征得到实体对表示。关系分类层的主要任务是通过概率预测实体对之间的关系。其中重点在于通过lawformer预训练模型深度解析裁判文书,挖掘丰富的上下文信息,并添加章节信息到训练语料中进行语料重构,结合transformer架构的lawformer预训练编码器捕捉长距离依赖,增强模型对裁判文书结构复杂性的全面理解。并采用bigru进一步丰富上下文语义嵌入表示,提高对文本细节的识别能力,有益于提升模型在文档级法律关系抽取上的表现。
62、2.本发明使用了lawformer预训练模型作为编码器,实现裁判文书通篇语义的建模。lawformer预训练模型使用法律数据作为预训练语料库,使其在法律领域具有更强的语义理解能力。相比于通用领域的预训练模型,lawformer能够更好地理解和处理法律文本中的特定语义和逻辑结构,从而更准确地捕捉到裁判文书中的关键信息。且由于裁判文书往往较长,并且涉及多个段落或章节,传统的模型可能会受到输入序列长度限制的影响。而lawformer通过使用更大的模型参数和更长的最大序列长度,能够更有效地处理长文本输入,从而提高了模型对裁判文书全文的理解能力。此外,采用lawformer编码的最后一层的输出作为下游任务的输入,经过提取和变换后,便于下游模块利用相关信息实现文档级法律关系抽取。这样使用lawformer预训练模型进行文档级法律关系抽取能够充分利用法律数据的特点,提高模型对裁判文书的理解能力和处理能力,从而为裁判文书分析提供更加准确和全面的支持。
63、3.本发明在构建方面中结合了知识蒸馏进行模型的训练优化。这里设计了特征蒸馏与目标蒸馏结合的混合自蒸馏的模型训练策略。采用的是自蒸馏方案,即教师模型和学生模型架构一致,设计相关蒸馏损失函数实现基于特征蒸馏和目标蒸馏的双重知识混合蒸馏。重点在于基于文档嵌入层进行lawformer嵌入编码的特征蒸馏,模型可以从裁判文书中学习更丰富的语义信息,并保持对裁判文书编码的语义一致性。通过目标蒸馏在关系分类层引入软标签进行与真实硬标签的联合监督训练,优化了模型关系分类性能。
64、4.本发明结合法律领域数据不平衡问题上设计了对应的分类损失函数以改善模型在文档级法律关系抽取上的分类性能。在自适应焦点损失函数基础上引入了ldam损失函数,为每个关系类别分配基于其标签分布的边距,自动调整文档级法律关系抽取模型在不同类别上的关注度,使得文档级法律关系抽取模型在少数类别上获得更好的泛化能力,有效处理数据不平衡问题,提升模型在文档级法律关系抽取上的表现。
本文地址:https://www.jishuxx.com/zhuanli/20240730/194904.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表