基于单词重要性与同义词替换的文本分类模型防御方法
- 国知局
- 2024-07-31 22:53:17
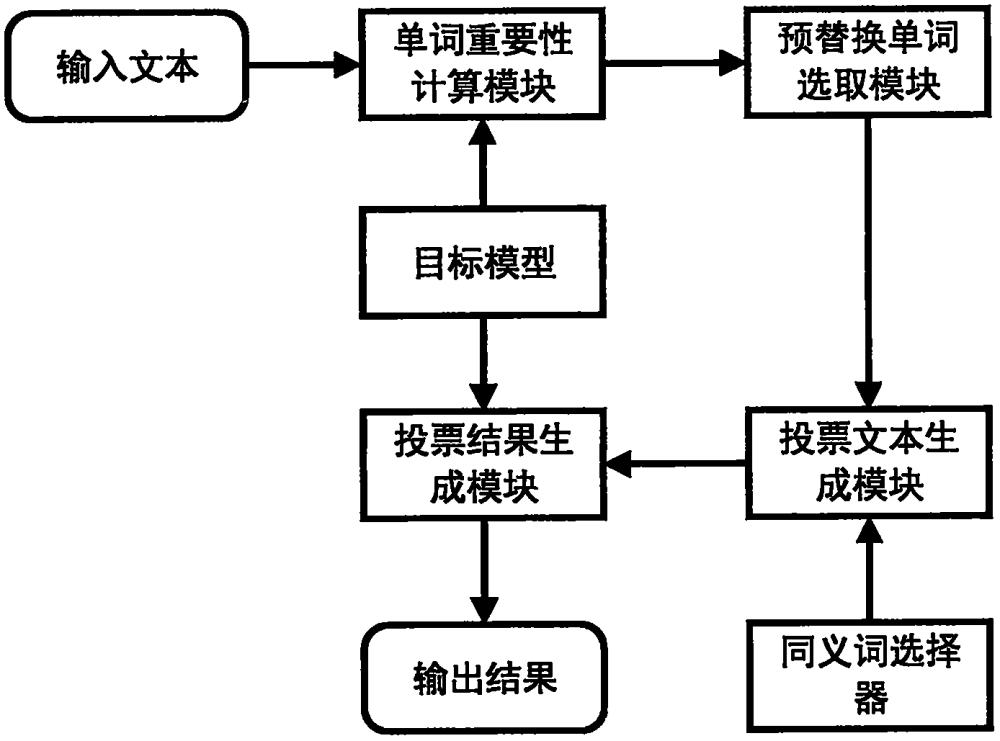
本发明可以有效提高文本分类模型在面对基于同义词替换的对抗攻击时的鲁棒性,属于一种针对自然语言处理模型的对抗攻击防御策略,属于人工智能安全领域。
背景技术:
1、近些年来,自然语言处理技术飞速进步,并在各个领域得到广泛应用,如机器翻译、ai写作、ai客服、新闻分类等。然而,与此同时,自然语言处理模型也面临着越来越多的挑战,尤其是在处理复杂、多变的自然语言数据时。其中,对抗攻击对模型效果的影响尤为显著。那些精心制作的对抗样本往往是难以察觉的,但是却可以在很大程度上改变模型的输出结果。因此,自然语言处理模型的安全性问题越来越受到人们的关注,提升自然语言处理模型的鲁棒性已成为当前自然语言处理领域的研究热点之一。
2、在自然语言处理领域,目前常见的对抗攻击方法主要分为字符层面的对抗攻击、单词层面的对抗攻击和句子层面的对抗攻击。字符层面的对抗攻击主要包括对输入文本进行字符删除、插入,或者交换字符位置等。单词层面的对抗攻击主要包括对输入文本进行单词插入、删除、替换,同义词替换在这类方法中通常被广泛使用。句子层面的对抗攻击与单词层面的对抗攻击相似,但不同与单词层面的对抗攻击总是对单个词进行操作,句子层面的对抗攻击通常是对一组词进行操作。本发明所针对的就是目前常见的基于同义词替换的文本对抗攻击,如pwws、ga等,这类对抗攻击通过将原始输入文本中的部分词替换为其同义词来干扰模型的输出结果。大量的研究已经表明,这类攻击方法往往能够达到相当高的攻击成功率,而这类攻击对于人类来说,往往是难以察觉的。因此,提供一种可靠的防御方法来抵御这类攻击,以提高模型的鲁棒性是很有必要的。
3、不同于传统的防御方法,深度学习模型的对抗攻击防御和鲁棒性提升是一个全新的领域。近年来,相关领域的研究发展迅速,研究者们已经探索各种方法来提升深度学习模型的鲁棒性,以使模型能够在复杂多变的环境中保持稳定的性能。其中,针对自然语言处理处理模型的鲁棒性提升技术主要可以分为基于对抗训练的方法和基于扰动控制的方法。前者大多通过数据增强、正则化的方式来对模型参数进行重新训练,以获得更具鲁棒性的模型。而后者,大多是设计各种防御方法来抵御对抗攻击,例如修改模型训练方法来获取更具鲁棒性的模型参数的方法,或者设计额外的防御模块或对抗识别模块来进行对抗攻击防御。
4、无论是基于对抗训练的方法还是基于扰动控制的方法,近年来都发展迅速,并诞生了许多效果优秀的防御方法。然而,目前的方法仍旧或多或少地存在着部分问题,如对抗防御效果仍不够理想,在干净数据集上的性能下降幅度较大,时间或算力消耗过大等。因此,提出一种效果更加稳定的防御方法是相当有必要的。
技术实现思路
1、发明目的:为了解决自然语言处理模型在面对基于同义词替换的对抗攻击时正确率大幅下降的问题,本发明提出了一种基于单词重要性与同义词替换策略的文本分类模型防御方法,通过计算输入文本中每个单词的重要性,选取重要性较高的单词进行随机同义词替换,生成多个投票文本,然后对投票文本逐个预测,通过投票得出最终预测结果,实现了对同义词替换攻击的防御。
2、本发明采用的总体技术方案如下:对于要被保护的目标模型,在对输入文本进行预测时,先衡量文本中每个单词的重要性,选取重要性较高的单词作为预替换单词。然后生成用于投票的投票文本,对于每个投票文本,先复制原始输入文本,然后从预替换单词中随机选择一部分,进行同义词替换。最后对所有的投票文本进行预测,综合所有投票文本的预测结果作为模型对原输入文本的分类结果。
3、进一步的,上述要被保护的目标模型,特指用于文本分类任务的自然语言处理模型,即f(x)→y,其中x表示输入的文本,y表示预测结果。具体地,y的形式为一个n维行向量,y的第i维表示x属于类别i的概率,n为文本分类任务的总类别数。y中概率最大的类别将作为模型最终的预测结果。
4、进一步的,对于被保护的目标模型,在执行文本分类任务时,对于输入文本x,需要先计算文本x中每个单词的重要性,重要性计算方法如下:
5、对于输入文本x,可以看作是由单词组成的有序集合,因此我们可以将其形式化地表示为:
6、x={w1,w2,w3......wi......wn-1,wn}
7、其中,wi为文本x中的第i个单词,n为文本x中的单词总数。在计算单词wi的重要性时,需要先复制原文本x,并将其中的单词wi修改为unk,得到新的文本xi,形式化地,xi可以被表示为:
8、xi={w1,w2,w3......unk......wn-1,wn}
9、其中unk为特殊占位符,其在模型的embedding层中对应的词向量为0向量,相当于将单词wi从原文本中挖去,并在原位置放置一个无实际意义的占位符。我们将原文本x与替换wi后的文本xi依次喂入目标模型f,得到原始文本预测结果f(x)与替换wi后的文本预测结果f(xi),然后将f(x)与f(xi)间的欧式距离作为单词wi的重要性。形象化的,这里我们可以将单词wi的重要性理解为单词wi对模型分类结果的影响,或者是删去单词wi后模型预测结果的变化。此外,因为后续处理中只涉及对所有单词重要性的比较,因此为了方便处理,我们直接采用f(x)与f(xi)间欧氏距离的平方作为单词wi的重要性。因此,对于单词wi的重要性,其计算公式为:
10、pi=(f(xi)-f(x))·(f(xi)-f(x))
11、需要注意的是,这里的单词wi特指输入文本x中的第i个单词,若x中存在单词wj=wi,j≠i,对于单词wj的重要性,仍需要按照上述步骤计算,而不是直接令pj=pi。
12、在计算得到输入文本x中每个单词的重要性后,将所有单词按重要性排序,选取重要性最高的60%单词,作为后续进行随机同义词替换的预替换单词,记为s。需要注意的是,这里选取的预替换单词,是包含其在原输入文本x中的位置信息的,即在预替换单词列表中,可以存在wj=wi,j≠i的情况。
13、进一步说明,生成用于投票的投票文本,其生成的具体数量为20个,对于第i个投票文本,其具体生成方法如下:
14、复制原始输入文本x,并将复制的文本记为x′i,然后从预替换单词列表s中,随机选取70%的单词,作为需要进行同义词替换的单词。对于每个被选取的单词wi,先获取其同义词集合,记为syn(wi),然后从syn(wi)中随机挑选一个同义词,并将x′i中的单词wi替换为该同义词。被选取的单词全部替换完成后得到的x′i即为第i个投票文本。
15、进一步的,获取单词wi的同义词集合方法为:计算除自身外其它所有单词与wi在词向量空间中的欧氏距离,将那些欧式距离小于0.5的单词认为是wi的同义词。此外,当同义词数量大于8时,只选取欧氏距离最近的8个单词作为同义词,最终得到的同义词集合记为syn(wi)。其中,计算欧式距离时使用的词向量编码为经过counter-fitting的glove(global vectors for word representation)词向量。
16、进一步的,对所有的投票文本进行预测,综合所有投票文本的预测结果作为模型对原输入文本的分类结果,其具体操作如下:
17、将上述步骤得到的20个投票样本依次使用目标模型进行分类预测,得到20个分类预测结果,每一个预测结果为一个n维行向量,代表该文本属于每一个类别的概率。将每个类别在这20个预测结果中获得的概率值相加,得到每个类别的总概率值,选取总概率值最大的类别,作为目标模型对于输入文本x的最终分类结果。其公式表示为:
18、
19、有益效果:
20、(1)有效防御了基于同义词替换的文本对抗攻击,提高了模型的鲁棒性,使模型在面对对抗样本时的预测准确率大幅提高,并且在干净样本上的准确率下降幅度也较小。
21、(2)不需要对模型进行重新训练,与以往常用的对抗训练、数据增强等方法相比,减少了重新训练模型的开销。
22、(3)该防御方法不需要获取模型的参数和结构,只需要知道模型的输入输出即可,属于黑盒验证方法。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195187.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表