一种结合多注意力机制的视线估计方法
- 国知局
- 2024-07-31 22:53:29
本发明涉及计算机视觉,具体为一种结合多注意力机制的视线估计方法。
背景技术:
1、人类注视方向是分析人类行为的重要指标,其反映了对环境中各种视觉刺激的注意水平和认知状态。为了更好地理解人类注视机理,学者需要更好地度量人类视线角度来分析视线中所蕴含人类意识方面的信息,而视线估计方法是指通过相机对人脸或人眼进行采集,使用图像处理手段,获取眼部坐标,并通过计算确定人眼注视点位置或视线矢量方向,该技术在人机交互、虚拟现实、医学和疲劳驾驶检测等诸多领域都有着十分广泛的应用。
2、早期的视线估计方法主要采用基于角膜反射的方法和基于眼球模型的方法。这类方法依赖于昂贵的专用设备和精确的数据校准(如光轴、角膜半径和瞳孔半径),且通常受限于周边环境的影响,很难得到高分辨率的图片,其效果在实际场景中往往不太理想。基于外观的视线估计的目标主要是学习一个图像i到视线向量的映射其中θ、φ为偏航角、俯仰角以及滚动角,而g分别表示在眼坐标系统[gx,gx,gz]中的真实值的分量。早期的基于外观的方法一般针对实验者个人学习映射函数,直接将人眼或人脸图像输入至深度神经网络,输出即为对应的视线方向,这需要耗费时间收集大量个人的训练样本,针对个人的模型虽然具有较好的精度,但每次使用都需要经过大量采集个人数据,并且模型不具有泛化性。后来,多数研究人员使用多人交叉训练的方法已解决模型的泛化性问题。尽管提出了很多基于深度学习的视线估计模型,但现有的精度与鲁棒性仍无法满足实际应用需求。
技术实现思路
1、本发明的目的在于提供一种结合多注意力机制的视线估计方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:一种结合多注意力机制的视线估计方法,包括以下步骤:
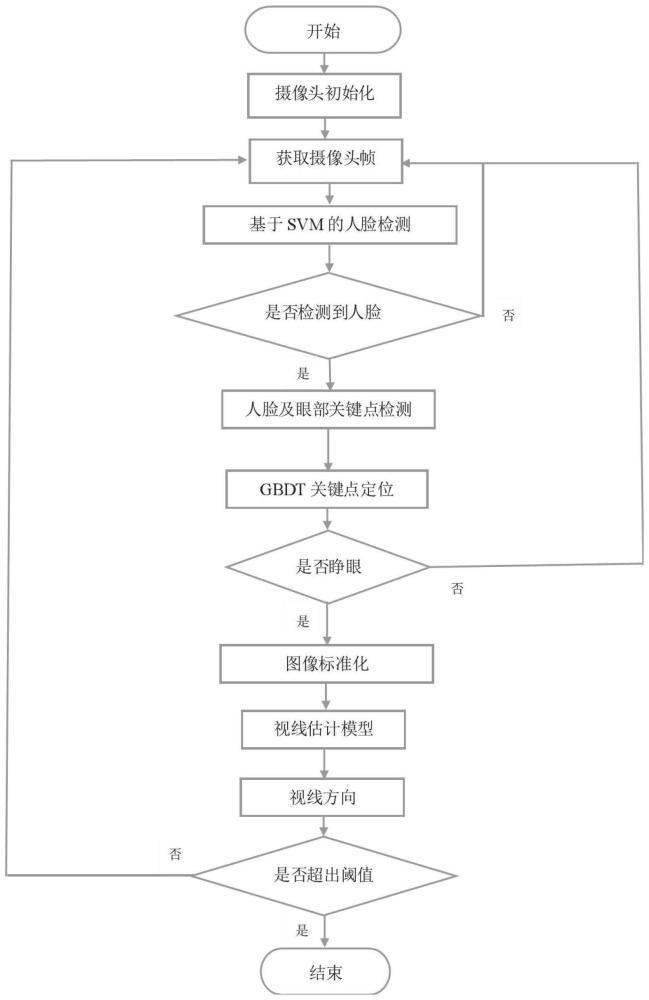
3、s1、人脸数据采集:基于hog特征结合支持向量机(svm)的方法进行人脸检测,在检测到人脸的基础上采用梯度提升决策树(gbdt)对人脸68个关键点进行定位,然后结合眼睛纵横比指标对眨眼行为进行判断,去除无效的视频帧图像,为后续视线估计提供更为准确的输入;
4、s2、视线特征的提取:采用基于cbam注意力机制以及多头自注意力机制改进的残差网络直接从采集到的人脸图像中提取到视线特征并与双向长短期记忆网络(bi-lstm)建立连接,用于获取前后帧视线的变化特征;
5、s3、对前后帧视线特征进行融合:在采集到有效人脸图像中,针对视频的前后三帧图像,利用通道注意力机制对每个时刻的lstm层输出的视线特征进行融合,以达到整合多时刻的视线信息,减少视线估计误差;
6、s4、利用gaze360和mpiifacegaze公共数据集对整个模型进行训练和测试,并在按照步骤s1采集的视频数据上进行方法验证,并在所基于采集人脸信息获取各帧用户图像的视线偏航角、俯仰角、滚转角以及角度误差。
7、优选的,所述gaze360在公共数据集上训练视线估计模型对人脸及图片进行训练及测试,采用特殊的pinball loss获得某一分位数下的预测输出,利用输出完成预测输出范围的回归模型;
8、而pinball loss由式(1)、(2)定义:
9、
10、
11、优选的,所述θgt为视线真实值,θ为测量值,σ为5%和95%分位点之间的方差,τ为任意分位数,τ设置为5%。
12、优选的,所述视线估计模型的网络初始输入形状为32×21×224×224的7帧3通道图像,经过一个多头注意力机制的输入模块得到形状为32×16×56×56的多头注意力图。
13、本发明针对resnet-18这个主干网络探究了注意力机制在不同深度下的具体效果,通过加入了cbam注意力机制来减少模型参数以及增强主干网络的特征提取能力,之后通过两层的mlp映射为32×7×256的特征图。最后将这7通道的特征图输入到双向lstm中并通过两层全连接层映射为3维的视线向量。
14、优选的,所述多头自注意力机制用于增强输入图像中视线的显著性特征,多头自注意力机制由式(3)所定义;
15、
16、fc=σ(mlp(gap(η′))+mlp(gmp(η′)))×η′ (4)
17、ms(fc)=σ(f7×7([avg pool(fc);maxpool(fc)])) (5)
18、优选的,所述q、k、v分别为查询值、关键值和输入值,且满足q=k=v,dscale为缩放尺度,η′表示多头注意力特征图,fc表示通道注意力特征图,ms(fc)为空间注意力图,σ为激活函数,gap表示全局平均池化,gmp表示全局最大池化,mlp由1×1的卷积、relu激活函数和1×1的卷积组成。
19、而在残差结构中加入cbam注意力机制,其结合空间注意力和通道注意力机制,通过在残差结构中引入cbam注意力机制来减少模型参数以及增强主干网络的特征提取能力。cbam注意力机制由式(4)和(5)定义。
20、优选的,所述视线估计模型的训练方式包括:
21、图像预处理:对gaze360数据进行训练集和测试集的划分,同时进行标签归一化及图像的标准化处理,得到用户的头部信息。
22、参数的设置:结合多注意力机制的视线估计模型在pytorch框架中使用adam优化器进行训练。以下超参数设置来训练网络,批处理大小为32、学习速率为0.0001、训练周期为80。
23、优选的,基于hog特征结合支持向量机的方法进行人脸检测,以获取人脸图像,所采集的视频时长需大于3秒,预处理模块用于视频中裁剪视频的7帧×3的视频序列,并对该序列的图像进行标准化处理。
24、采用将7帧全脸图像作为输入,输入到基于多种注意力机制改进的resnet-18主干网络中提取视线的高维特征;之后利用双向lstm及通道注意力层获取7帧人脸图像的上下文信息,最后回归求解出最后的三维视线角度和角度误差。
25、步骤s1人脸数据采集中,我们将所采集视频分割为3秒时长的视频段,并提取出3×7帧形状为3×224×224大小图片输入到视线估计模型中进行验证,在此之前还对将样本数据进行图形增强和标准化处理,进而在gaze360测试集上取得了小于9.39°的角度误差。
26、所述步骤s2视线特征的提取中,传统的卷积层或全连接层在信息传递时或多或少会存在信息丢失的问题。而resnet是具有残差结构的深度卷积神经网络,其可以有效缓解网络深度带来的梯度弥散问题,可以学习到更复杂、更丰富的图像特征表示,这对于视线估计任务来说是有益的;同时对于实时的视线估计任务,全局的空间信息和上下文信息也是非常重要的,因此提出采用cbam注意力机制和多头自注意力机制来获取图像中所蕴含的视线空间信息,利用双向lstm结合通道注意力机制来获取视线的上下文信息。
27、在所述步骤s3前后帧视线特征融合中,该模块有2层lstm层,lstm的具体原理如公式(6)所示,其中xt为该层的输入数据矩阵,σ、tanh为激活函数,wf、wi、wc为权重矩阵,bo、bc、bi为各项偏置,h为每层lstm的输出。
28、输入数据矩阵xt和上一个lstm细胞的隐藏输出ht-1首先经过遗忘门ft过滤出与前一帧的注视方向相关但与当前目标明显无关的特征。而记忆门则是用gt和it函数将当前时刻输入xt的和上一时刻隐藏层的输入ht-1中的视线信息提取出来,然后遵循公式ct=ft*ct-1+it*gt来控制这些记忆,即合并遗忘门和输入门的信息后得到当前时刻的细胞状态ct。然后通过输出门ot=σ(wo·[ht-1,xt]+bo)得到一个归一化权重ot。最后根据公式ht=ot*tanh(ct)得到当前细胞的隐藏输出ht,并合并其他6个lstm细胞的隐藏层输出后得到包含上下文信息的输出并将其送入一个通道注意力层增强特征之间的时间相关性。
29、
30、与现有技术相比,本发明的有益效果是:本发明通过通道注意力机制来权衡各时间点的视线特征,并基于双向lstm设计了一个视线时变特征融合结构以正确得出视频帧数中的视线的相关性,从而更好地获取短时间中最优的视线估计。之后利用gaze360公共数据集对整个模型进行训练和测试,依照采集人脸图像建立验证集,设定一个视线误差阈值α,根据模型在验证集上的表现来调整阈值,当视线估计任务的角度误差小于阈值α时,输出一个精确的视线角度。在满足实时性、稳定性、精确性、通用性的条件下,解决神经网络模型体积大、速度慢、需要大量训练样本等技术难题,利用终端设备仅有的资源实现最有效的视线估计。
本文地址:https://www.jishuxx.com/zhuanli/20240730/195205.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。