一种基于多智能体强化学习的无人机集群动态避障方法
- 国知局
- 2024-07-31 23:30:42
本发明涉及无人机的三维位置或航道控制,具体提出了一种基于多智能体强化学习的无人机集群动态避障方法。
背景技术:
1、新型任务执行概念所构想的未来任务执行场景中,传统的多任务平台被分解为了众多的小型任务执行单元,这些小型任务执行单元通常具备更高的灵活性,能够根据环境的变化快速对自身所承担的任务进行调整,以实现更好的整体任务执行效果。在未来的新型任务执行场景中,传统的集中式指挥控制模式存在着指挥链路过长、决策复杂度过高等问题,从而导致决策时效性和决策质量难以满足要求。近年来,边缘指挥控制等新型指控模式应运而生,边缘节点也即各任务执行实体将具备一定程度的自主决策能力。由于环境的复杂多变特性,以及任务执行实体的小型化、智能化发展趋势,分布式决策的模式将在未来的决策中发挥越来越重要的作用。
2、任务执行体系是为了完成特定的任务执行任务由一系列具备各项能力的任务执行单元动态构建而成,在以往的集中式决策模式下,体系设计人员会根据任务执行任务的能力需求以及任务执行单元所具备的各项能力,以最大化任务执行效能或最小化任务执行单元的使用成本等为目标,来统一地对各任务执行任务和任务执行单元进行匹配。任务执行体系的“任务执行任务—任务执行单元”匹配问题可以建模为一个优化问题,当问题规模较小时可以采用集中式决策的模式运用整数线性规划等运筹学方法快速得到全局最优解,而当问题规模较大时可以采用遗传算法等启发式算法或者强化学习算法得到问题的近似最优解。采用集中式决策的一个重要前提条件是中心决策节点和任务执行单元叶节点之间的通信畅通,因为叶节点需要将自身的状态信息和观测信息发送给中心决策节点,而中心节点需要将决策命令等发送给叶节点。然而在未来的任务执行场景中,由于敌方的通信干扰等原因,中心节点和叶节点之间的通信链接很难保证连续畅通,同时频繁的信息交互会造一定的通信负载和通信延迟,因此在未来很多的任务场景中需要任务执行单元根据自身的状态信息和观测到的信息独立地进行决策。
3、强化学习是一种利用智能体与环境的交互信息不断地对智能体的决策策略进行改进的方法,随着深度强化学习技术的快速发展,强化学习算法在无人机路径规划、无线传感器方案调度等领域都取得了非常成功的应用,同时近年来多智能体强化学习算法在starcraftⅱ等环境中也取得了很好的效果。在任务执行体系任务分配的场景中,可以将各任务执行单元视为多个决策智能体,那么“任务执行任务—任务执行单元”的匹配任务就可以视为一个多智能体强化学习任务。而当前尚未有将多智能体强化学习方法应用到类似任务执行体系(如无人机集群避障等)的任务分配环境中的先例。
4、在如无人机集群避障任务中,若采用完全集中式训练与决策,即把多个智能体当作一个超级智能体在进行决策,即把所有智能体的状态聚合在一起当作一个全局的超级状态,把所有智能体的动作连起来作为一个联合动作。这样做的好处是,由于已经知道了所有智能体的状态和动作,因此对这个超级智能体来说,环境依旧是稳态的,一些单智能体的算法的收敛性依旧可以得到保证。然而,这样的做法不能很好地扩展到智能体数量很多或者环境很大的情况,因为这时候将所有的信息简单暴力地拼在一起会导致维度爆炸,训练复杂度巨幅提升的问题往往不可解决。若采用完全分布式训练与决策,即假设每个智能体都在自身的环境中独立地进行学习,不考虑其他智能体的改变。这样做的缺点是环境是非稳态的,训练的收敛性不能得到保证,但是这种方法的好处在于随着智能体数量的增加有比较好的扩展性,不会遇到维度灾难而导致训练不能进行下去。
技术实现思路
1、因此,在考虑中心规划器能够与无人机进行通讯、不需要无人机互相之间进行通讯的情况下,我们采用一种基于无人机对障碍物局部观测的集中式训练、部分分布式决策方法,解决了上述方法中存在的维度爆炸与环境非稳态的问题,使算法兼具扩展性与收敛性。在考虑无人机与中心规划器失联、无人机存在有限互相通信的情况下,进一步对无人机局部观测进行改进,使得无人机可以不依赖中心规划器从而进行完全分布式决策。
2、针对多智能体强化学习在无人机避障中存在训练效率低的问题,本发明提供了一种基于模型预测控制的改进多智能体强化学习方法,该方法通过数据驱动的方法学习环境态势和奖励模型,并采用滚动优化区间进行无人机的策略训练。该方法具有较高的学习效率、更快的策略趋近于最优值的收敛速度以及较少的经验重放缓冲区所需的样本容量空间。使得无人机仅通过少量尝试就能学习最佳策略,促进了强化学习方法在避障问题中的应用。
3、本发明完整的技术方案包括:
4、一种基于多智能体强化学习的无人机集群动态避障方法,针对强化学习在无人机避障中存在维度爆炸与环境非稳态的问题,在考虑中心规划器能够与无人机进行通讯,不需要无人机互相之间进行通讯的情况下,提出了一种集中式训练、部分分布式决策方法。在考虑无人机与中心规划器失联,无人机存在有限互相通信的情况下,提出了一种集中式训练、完成分布式决策方法。针对多智能体强化学习在无人机避障中存在训练效率低的问题,提出了一种基于模型预测控制的改进多智能体强化学习方法,使无人机在与环境交互次数更少的情况下策略收敛到最优值。
5、本发明完整的具体方案包括:
6、一种基于多智能体强化学习的无人机集群动态避障方法,所述多智能体强化学习包括策略网络、值函数网络和模型网络,采用滚动优化的方式对策略网络进行训练,所述策略网络为执行器并与环境进行交互,所述值函数网络对执行器与环境进行交互的结果进行评价,具体包括以下步骤:
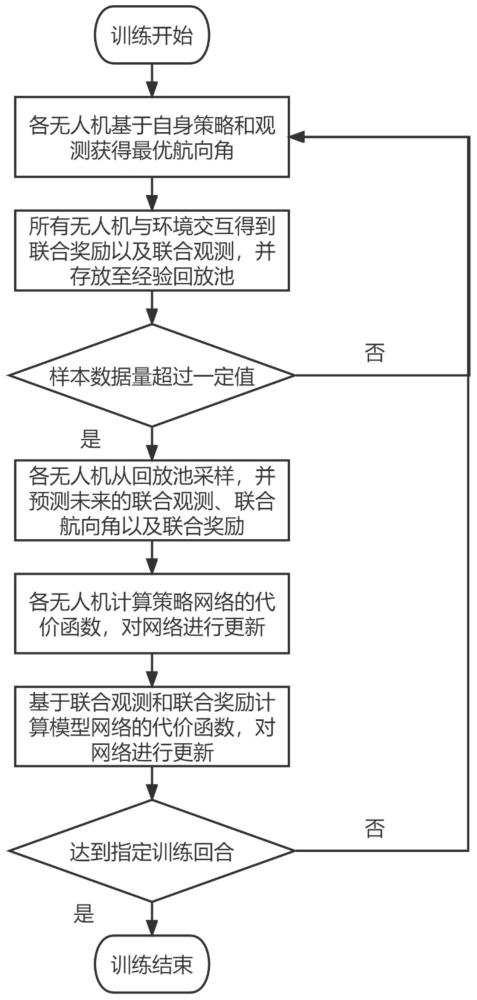
7、步骤(1):无人机集群中的各无人机基于当前时刻的自身策略和观测计算得到当前时刻的最优联合航向角;
8、步骤(2):根据无人机动力学模型、运动学约束与扰动流场法,并结合步骤(1)得到的当前时刻的最优联合航向角得到所有无人机的下一时刻位置,再结合障碍物下一时刻的位置和无人机的目标位置得到下一时刻所有无人机的观测以及当前时刻所有无人机的奖励,将联合观测、联合航向角、联合奖励数据存储到经验回放池中;
9、步骤(3):当经验回放池中的样本数据量超过一定值时,各无人机从经验回放池中采样部分样本数据,采用多步预测方法来预测每一个样本数据的未来所有无人机的联合观测、联合航向角以及联合奖励;
10、步骤(4):各无人机通过步骤(3)中的当前和未来所有无人机的联合观测、联合航向角以及联合奖励计算策略网络的代价函数,并根据策略网络的代价函数对策略网络进行梯度更新;
11、步骤(5):通过步骤(3)中的当前和未来所有无人机的联合航向角以及联合奖励计算模型网络的代价函数,并根据模型网络的代价函数对模型网络进行梯度更新;
12、步骤(6):重复步骤(1)-(5)直至达到指定训练回合,结束策略学习过程,得到训练完毕的策略网络;
13、步骤(7):在无人机集群任务执行过程中,采用步骤(6)训练完毕的策略网络进行动态避障。
14、进一步的,步骤(1)中的最优航向角为:
15、
16、其中,为当前时刻第i架无人机的最优航向角,是第i架无人机当前时刻的观测,第i架无人机当前时刻的策略。
17、进一步的,步骤(1)中的所述观测分为针对集中式训练、部分分布式决策方法的观测,以及针对集中式训练、完全分布式决策方法的观测。
18、进一步的,针对集中式训练、部分分布式决策方法的观测中,无人机能够和中心规划器进行通信,无人机的观测空间包括自身位置信息,终点位置信息,障碍物位置和速度信息。
19、进一步的,针对集中式训练、部分分布式决策方法的观测具体为:
20、
21、式中,为第i架无人机在t时刻的观测,为第j个障碍物中心,为第i架无人机中心,表示第i架无人机和第j个障碍物之间的距离,表示无人机的几何半径,表示障碍物的几何半径;表示终点的位置,表示第j个障碍物的速度。
22、进一步的,针对集中式训练、完全分布式决策方法的观测中,无人机不能和中心规划器进行通信,但能够和部分邻居无人机进行通信,无人机的观测空间包括自身位置信息,终点位置信息,障碍物位置和速度信息,以及周围最近邻居无人机位置信息。
23、进一步的,针对集中式训练、完全分布式决策方法的观测具体为:
24、
25、式中,为第i架无人机在t时刻的观测,为第j个障碍物中心,为自身无人机中心,为自身无人机和第j个障碍物之间的距离,为无人机的几何半径,为障碍物的几何半径;为终点的位置,为第i架无人机中心,为第j个障碍物的速度,为最近邻居无人机中心,为自身无人机和最近邻居无人机之间的距离。
26、进一步的,所述模型网络包括态势转移函数网络和奖励函数网络。
27、本发明相对于现有技术的优点包括:
28、(1)针对多智能体强化学习在无人机避障中存在维度爆炸与环境非稳态的问题,在考虑中心规划器能够与无人机进行通讯、不需要无人机互相之间进行通讯的情况下,提出了一种集中式训练、部分分布式决策方法,即无人机的局部观测包括自身位置信息、终点位置信息、障碍物位置和速度信息,使算法兼具扩展性与收敛性。
29、(2)在考虑无人机与中心规划器失联、无人机存在有限互相通信的情况下,提出了一种集中式训练、完全分布式决策方法,即无人机的局部观测包括自身位置信息、终点位置信息、障碍物位置和速度信息、邻居无人机位置信息,使得无人机可以不依赖中心规划器从而进行完全分布式决策。
30、(3)针对多智能体强化学习在无人机避障中存在训练效率低的问题,提出了一种基于模型预测控制的改进多智能体强化学习方法,该方法应用滚动优化方法来最大化每个预测区间的累积回报。该方法提高了无人机在多智能体强化学习中的学习效率和样本利用率。
31、以上方法使得多智能体强化学习方法能够应用于无人机集群动态避障问题,并具有较高的学习效率,更快的最优策略收敛速度以及较少的经验重放缓冲区所需的样本容量空间。
本文地址:https://www.jishuxx.com/zhuanli/20240730/197830.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。