一种基于深度强化学习的无人船对动态目标避障规划方法
- 国知局
- 2024-08-01 00:13:24
本发明涉及智能决策,尤其涉及一种基于深度强化学习的无人船对动态目标避障规划方法。
背景技术:
1、随着无人船在军用领域和民用领域的运用,各种复杂场景任务环境下需要无人船根据障碍物的分布情况结合自身位置给出避障规划决策。传统的路径规划避障算法,如人工势场法,动态窗口法,遗传算法等可以解决面对静态障碍时的避障规划,但在面对具有一定速度的障碍物表现不佳。而在现实的任务作战环境中往往无人船需要面对动态的环境,结合探测到的障碍物位置速度信息做出实时决策。
2、深度强化学习是一种综合深度学习感知能力和强化学习决策能力的算法,目前在无人船避障领域,已经有不少学者利用dqn、ddpg等模型对避障问题进行了研究,给出了静态障碍环境下的算法优化方案。但是在面对动态障碍物时,这些已有算法难以取得理想的效果,需要对算法加以改进,以避免出现碰撞的情况。
技术实现思路
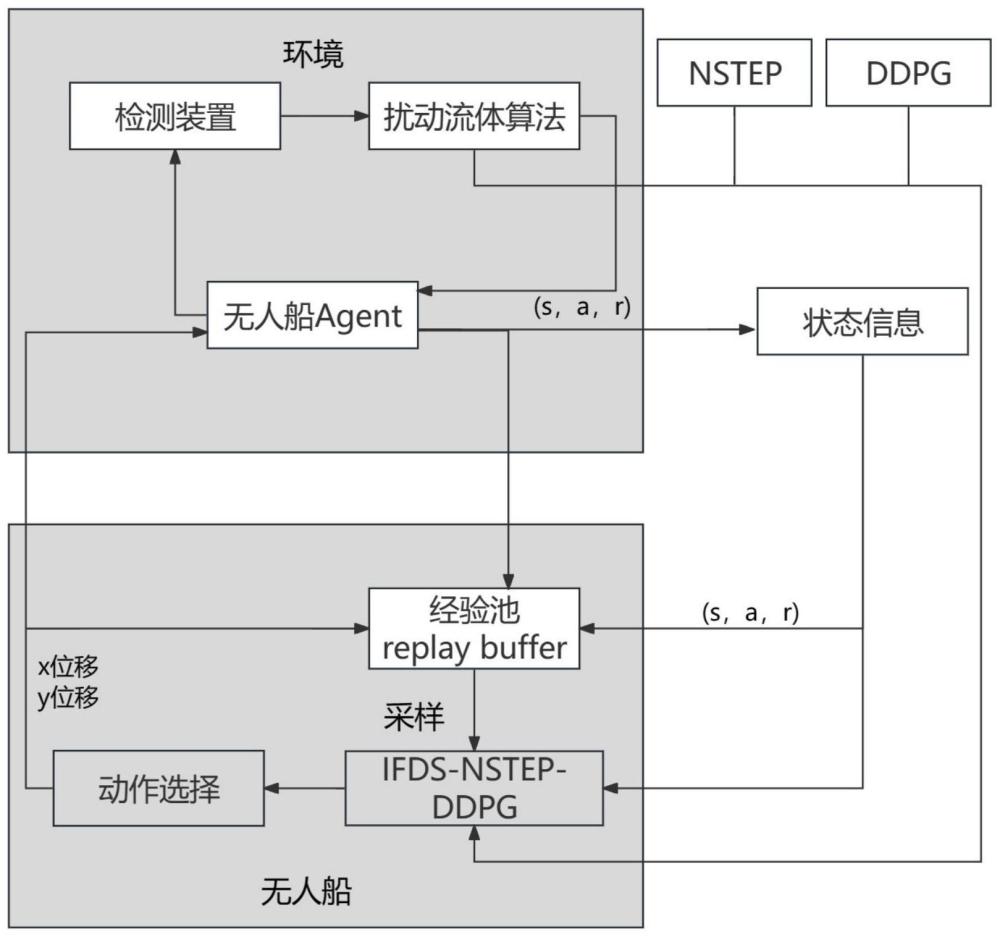
1、发明目的:本发明的目的是提供了一种基于深度强化学习的无人船对动态目标避障规划方法将ddpg算法结合了扰动流体算法(ifds)用于对训练避障过程进行干预,结合多步自举(nstep)改进网络reward值,从而实现动态障碍物避障并优化网络训练效果。
2、技术方案:本发明所述的一种基于深度强化学习的无人船对动态目标避障规划方法,包括以下步骤:
3、(1)创建不同的海面仿真场景,在定义的障碍库中随机生成障碍物,并随机指定无人船的起始位置和目标点。
4、(2)基于马尔可夫过程设计环境交互模型,包括模型状态空间s,动作空间a,奖励函数r以及状态转移概率p;
5、(3)搭建基于ifds-nstep改进的ddpg网络结构;
6、(4)利用改进后的ddpg算法训练模型,将训练模型加载到具体环境中验证算法的动态避障效果。
7、进一步的,所述步骤(2)中,无人船在坐标系中的状态转移公式为:
8、
9、其中,x,y表示无人船的坐标,vx,vy表示无人船的速度,t表示单位采样时间,vxe,vye表示无人船单位采样时间内速度的变化量;
10、进一步的,所述步骤(2)中,状态空间s包括:输入状态s=[si,st,so],其中,si表示无人船当前的状态信息,包括:无人船的位置坐标,速度向量,速度方向:si=[xi,yi,vxi,vyi],xi,yi表示无人船的平面坐标;vxi,vyi表示速度的向量,st表示无人船目标的状态信息,包括目标的位置坐标:st=[xt,yt];so表示无人船目标的状态信息,包括每个障碍物的中心位置坐标,速度向量,障碍半径:表示第k个障碍物的中心坐标,表示第k个障碍物的速度向量,表示第k个障碍物中心点到障碍物边缘的半径;
11、动作空间a包括:在收到外界反馈信息后针对当前状态s做出的输出动作、输出动作为表示单位时间内无人船速度的变化量、对速度变化量进行约束,公式如下:
12、设定最大值当速度变化量大于最大值e时,输出动作
13、奖励函数rw设计为:
14、
15、其中,r1为抵达目标奖励,在任务成功抵达目的地时获得奖励;r2为无人船与目标点的位置关系发生变化产生的奖励;r3为在与障碍物距离较近时以安全距离避障得到的安全避障奖励;r4为路径平滑奖励;d表示无人船距离目标点的距离;t表示目标与起始坐标的距离;dx表示无人船与最近障碍物的距离;r表示障碍物半径;ds表示无人船与障碍的安全距离;r表示无人船航迹角当前时刻和前一时刻相比的变化量;rw通过各奖励值相应的权重w设置得到:r=w1r1+w2r2+w3r3+w4r4;
16、状态转移概率表示在状态s下通过训练后的策略动作,状态转移到的概率。
17、进一步的,所述步骤(3)具体如下:定义u为原始流速,为起始点到目标点的直线,将障碍与障碍的速度定义为扰动势场,定义障碍物扰动矩阵定义vk为障碍参考速度:k表示第k个障碍物,λ为正值,vkl为障碍物质心的平移速度。结合三者得到实际流场流速:在无人船航行的过程中基于流场流速,对本体航行的速度进行修正:
18、
19、其中,vt为当前时刻的速度向量,α为调节系数,为当前速度流场。
20、进一步的,所述步骤(3)中,reward值通过介于1-step和n趋于无穷的monte carlo方法之间的n-step方法,记录当前n-1个时刻的reward值rt,并通过公式得到总的reward值。
21、进一步的,所述步骤(4)中,具体如下:首先,初始化训练,随机选定一个起始位置q,重置环境状态随机从障碍库中选择障碍在环境中生成,同时初始化actor和critic网络;
22、其次,在每个训练周期,agent无人船与环境进行交互,根据状态state和当前网络q选择动作action返回环境中,计算对应的reward值:
23、f(s,a,θ)=q*(s,a)
24、并由得到的reward值计算最小损失函数l,以此为依据根据梯度下降更新a-c网络参数;如果无人船达到目标点则训练周期结束,否则执行至最大次数;完成后将每个周期的训练经验存储在经验缓冲区中,不断更新actor网络和critic网络参数直到达到设置的训练轮数完成。
25、本发明所述的一种基于深度强化学习的无人船对动态目标避障规划系统,包括:
26、初始模块:用于创建不同的海面仿真场景,在定义的障碍库中随机生成障碍物,并随机指定无人船的起始位置和目标点。
27、交互模块:用于基于马尔可夫过程设计环境交互模型,包括模型状态空间s,动作空间a,奖励函数r以及状态转移概率p;
28、ddpg网络模块:用于搭建基于ifds-nstep改进的ddpg网络结构
29、验证模块:用于利用改进后的ddpg算法训练模型,将训练模型加载到具体环境中验证算法的动态避障效果。
30、本发明所述的一种设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的程序,所述处理器执行所述程序时实现任一项所述的一种基于深度强化学习的无人船对动态目标避障规划方法。
31、本发明所述的一种存储介质,存储有计算机程序,所述计算机程序被设计为运行时实现任一项所述的一种基于深度强化学习的无人船对动态目标避障规划方法。
32、有益效果:与现有技术相比,本发明具有如下显著优点:基于ddpg算法,结合ifds算法和nstep思想,生成障碍速度的扰动矩阵干预训练避障过程,赋予模型结合多个时间步综合决策的能力,实现了无人船在动态障碍环境下的避障,且对于价值函数的优化在一定程度上提高了算法训练的效率和整体避障的安全性。
技术特征:1.一种基于深度强化学习的无人船对动态目标避障规划方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于深度强化学习的无人船对动态目标避障规划方法,其特征在于,所述步骤(2)中,无人船在坐标系中的状态转移公式为:
3.根据权利要求2所述的一种基于深度强化学习的无人船对动态目标避障规划方法,其特征在于,所述步骤(2)中,状态空间s包括:输入状态s=[si,st,so],其中,si表示无人船当前的状态信息,包括:无人船的位置坐标,速度向量,速度方向:si=[xi,yi,vxi,vyi],xi,yi表示无人船的平面坐标;vxi,vyi表示速度的向量,st表示无人船目标的状态信息,包括目标的位置坐标:st=[xt,yt];so表示无人船目标的状态信息,包括每个障碍物的中心位置坐标,速度向量,障碍半径:表示第k个障碍物的中心坐标,表示第k个障碍物的速度向量,表示第k个障碍物中心点到障碍物边缘的半径;
4.根据权利要求1所述的一种基于深度强化学习的无人船对动态目标避障规划方法,其特征在于,所述步骤(3)具体如下:定义u为原始流速,为起始点到目标点的直线,将障碍与障碍的速度定义为扰动势场,定义障碍物扰动矩阵定义vk为障碍参考速度:k表示第k个障碍物,λ为正值,vkl为障碍物质心的平移速度。结合三者得到实际流场流速:在无人船航行的过程中基于流场流速,对本体航行的速度进行修正:
5.根据权利要求1所述的一种基于深度强化学习的无人船对动态目标避障规划方法,其特征在于,所述步骤(3)中,reward值通过介于1-step和n趋于无穷的monte carlo方法之间的n-step方法,记录当前n-1个时刻的reward值rt,并通过公式得到总的reward值。
6.根据权利要求1所述的一种基于深度强化学习的无人船对动态目标避障规划方法,其特征在于,所述步骤(4)中,具体如下:首先,初始化训练,随机选定一个起始位置q,重置环境状态随机从障碍库中选择障碍在环境中生成,同时初始化actor和critic网络;
7.一种基于深度强化学习的无人船对动态目标避障规划系统,其特征在于,包括:
8.一种设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的程序,其特征在于,所述处理器执行所述程序时实现如权利要求1-6任一项所述的一种基于深度强化学习的无人船对动态目标避障规划方法。
9.一种存储介质,存储有计算机程序,其特征在于,所述计算机程序被设计为运行时实现根据权利要求1-6任一项所述的一种基于深度强化学习的无人船对动态目标避障规划方法。
技术总结本发明公开了一种基于深度强化学习的无人船对动态目标避障规划方法,包括以下步骤:(1)创建不同的海面仿真场景,在定义的障碍库中随机生成障碍物,并随机指定无人船的起始位置和目标点。(2)基于马尔可夫过程设计环境交互模型,包括模型状态空间S,动作空间A,奖励函数R以及状态转移概率P;(3)搭建基于IFDS‑NSTEP改进的DDPG网络结构;(4)利用改进后的DDPG算法训练模型,将训练模型加载到具体环境中验证算法的动态避障效果;本发明提出了结合扰动流体算法和多步自举的改进DDPG避障方法,提高了训练过程的效率以及动态避障路径规划的成功率。技术研发人员:李震,吴一凡,李阳受保护的技术使用者:江苏科技大学技术研发日:技术公布日:2024/7/11本文地址:https://www.jishuxx.com/zhuanli/20240730/200078.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表