基于深度强化学习的高超飞行器智能突防机动决策方法
- 国知局
- 2024-08-01 00:14:50
本发明属于飞行器,具体涉及一种基于深度强化学习的高超飞行器智能突防机动决策方法。
背景技术:
1、近年来,战场作战模式和高超声速相关技术不断发展,高超声速飞行器凭借速度快、攻击范围广的优势,已成为各大国的国防重点研究对象。高超声速飞行器将成为未来战争中的重大威胁,势必刺激未来防空反导系统的不断发展和革新。美国、俄罗斯等国家大力发展返临能力,且在反导系统试验中多采用“二拦一”的方式拦截近程弹道导弹。
2、现有的传统程序式机动突防方式适应性低、手段固定,难以应对敌方日益增长的拦截能力和日益复杂的作战场景,突防效果不确定性大;基于规则设计的经典突防算法需要获取敌方拦截弹的完备运动信息,并对运动进行线性化建模,在实际作战中导致精度损失,突防效果欠佳;基于威胁区的轨迹优化算法需要敌方威胁区的完备信息,在实际作战中完全避开敌方威胁区,弹道轨迹过于保守,消耗大量燃油和攻击时间。
3、深度强化学习具备优秀的决策规划和态势认知能力,在基于“探测+机动博弈”的主动机动突防策略研究中有广阔的应用场景。但目前针对深度强化学习的机动突防博弈策略研究较少,且大都为二维平面上针对一枚拦截弹的机动策略研究,在场景建模和算法应用上具有较大的局限性。
技术实现思路
1、为了克服现有技术的不足,本发明提供了一种基于深度强化学习的高超飞行器智能突防机动决策方法,首先设计了高超声速飞行器面对敌方两枚拦截弹的典型攻防对抗场景。然后设计并训练深度强化学习算法,得到以飞行状态、相对运动状态为输入,高超声速飞行器机动过载指令为输出的机动决策。通过上述方法实现了高超声速飞行器的智能突防策略。
2、本发明解决其技术问题所采用的技术方案如下:
3、步骤1:攻防对抗作战典型场景建模;
4、步骤1-1:建立攻防对抗数学模型,在地面坐标系中建立高超声速飞行器h和两枚拦截弹(i1,i2)的三自由度质点模型,对于高超声速飞行器:
5、
6、
7、式中,下标h表示高超声速飞行器;vh表示飞行速度;θh,ψh分别表示弹道倾角和弹道偏角,用于描述高超声速飞行器在空间中的飞行姿态;xh,yh,zh表示地面坐标系下的位置坐标;nhx,nhy,nhz表示在弹体坐标系下三个方向的过载,其中nhx为切向过载,nhy,nhz为法向过载;g为重力加速度,取9.8;
8、步骤1-2:将飞行器的自动驾驶仪模型假设为一阶动力学环节,则高超声速飞行器和拦截弹获得的实际过载与过载指令的关系表述如下:
9、
10、式中,norder(s)为飞行器设计的过载指令,n(s)为过载响应,t为一阶动态特性的响应时间常数,s为拉普拉斯算子;
11、步骤1-3:将三维空间的运动投影到横向和纵向二维平面上;
12、由于突防机动主要体现在水平面中,在横向平面中拦截弹i1与高超声速飞行器h的相对运动学方程为:
13、
14、式中,下标h和i1分别表示高超声速飞行器和拦截弹;rhi1表示双方相对距离,表示相对距离的变化率;qh表示目标线方位角,简称视角,表示目标线hi的旋转角速度;ψh,分别表示飞行器的速度向量与目标线hi之间的夹角,即速度前置角;表示速度前置角的变化率;和分别表示水平面中攻防双方的弹道偏角;vh和分别表示高超声速飞行器和拦截弹的速度;
15、步骤2:典型作战场景想定;
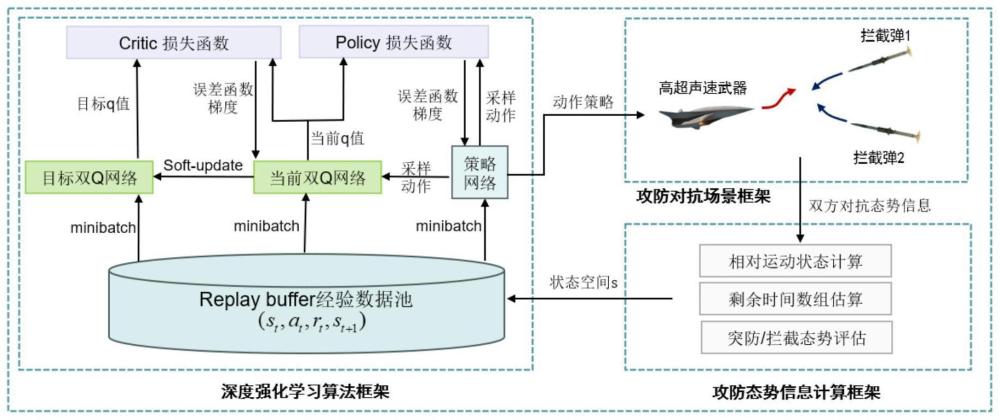
16、高超声速飞行器发射后,受地球曲率的影响,敌方雷达将在h1km外发现我方高超声速飞行器,并从不同发射阵地发射拦截弹进行拦截;在拦截过程中假设敌方已知我方高超声速飞行器的最终攻击目标,故在整个拦截过程中制导率不切换,为比例制导率,导航比随攻防双方相对距离变化;制导加速度指令为:
17、
18、式中,n为有效导航系数,取值为:
19、
20、我方高超声速飞行器在相距h1km时机载雷达开始工作,基于自身的告警探测设备和设计算法输出指令过载,进行规避突防;在不机动的情况下,高超声速飞行器处于平飞状态;高超声速飞行器采用倾斜转弯btt技术,数学表达式为:
21、
22、
23、式中,ayc和azc为惯性系下俯仰和偏航的制导指令;γbc0为弹体系下的滚转角大小,对其进行处理后输出γbc滚转控制指令;αybc为弹体系下俯仰控制指令;
24、步骤3:设计智能突防决策算法框架,分为深度强化学习算法框架、攻防对抗场景框架、攻防态势信息计算框架;
25、深度强化学习算法框架根据输入的攻防态势信息,输出作用于攻防对抗场景的动作指令;攻防对抗场景框架分别根据机动过载指令解算出模拟高超声速飞行器和拦截弹的运动信息,并生成弹道轨迹;攻防态势信息计算框架根据攻防对抗双方的相对运动信息计算相对运动状态和剩余时间数组、并对拦截态势和突防威胁进行评估;
26、步骤4:sac(soft actor-critic with maximum entropy)算法模型搭建;
27、步骤4-1:采用sac算法进行智能机动决策训练,交互过程用马尔可夫决策过程(markov decision process,mdp)表示:
28、[s,a,p,r,γ]
29、式中,s为状态空间(state),智能体(agent)根据状态空间信息做出决策;a为动作空间(action),表示智能体做出的决策信息;p是状态转移概率(probability);r表示回报函数(reward),用于给智能体的决策打分;γ表示折扣因子,以γ为参数对r加权累计,得到一次完整的mdp过程中得到的总回报,深度强化学习的训练过程即为使得总回报最大的过程:
30、ut=rt+γ·rt+1+γ2·rt+1+...+γn-t·rn
31、式中,rt表示t时刻的奖励值,rt+1表示t+1时刻的奖励值,rn表示t+n时刻的奖励值;γ表示折扣系数,用于调节未来奖励相对于当前奖励的重要性;ut表示总回报大小;
32、步骤4-2:sac算法基于actor-critic架构,内部的深度神经网络结构由双q值网络和策略网络构成,输入层与输出层都是全连接网络的结构;双q值网络用qθ(st,at)表示,策略网络用π(at|st)表示;sac算法通过最大化奖励的期望值和熵的加权和来进行优化,目标函数为:
33、
34、式中,参数α是温度项,用来控制上一时刻策略的熵对于奖励的重要程度;st表示当前t时刻的状态值,st+1表示t+1时刻的状态值;at表示动作值;r(st,at,st+1)表示奖励值;h(π(·|st))表示熵值,即策略π(·|st)的随机性或不确定性;α表示温度参数,即用于控制探索的程度;γ表示折扣系数;
35、步骤4-3:q网络的目标函数为:
36、
37、其中,d表示经验回放池中的数据;s,s′表示t时刻与t+1时刻的状态值;表示目标网络对状态s的预测价值估计;并使用mseloss作为loss函数,θ表示q网络的权重、偏置参数;q网络每次选择输出中较小的一个状态动作值作为目标q值:
38、
39、式中,表示状态动作值中的较小值,s′和a'表示下一时刻的状态和动作;α表示温度系数;
40、采用重参数化技巧对动作采样,sac算法用一个带噪声的神经网络表示策略:
41、at=fφ(ε;st)
42、式中,ε表示噪声强度,fφ(.)表示噪声函数,即策略输出的概率分布;
43、由此得策略网络的目标函数为:
44、
45、式中,n表示给定的噪声策略;
46、熵的温度项自动调节的损失函数为:
47、
48、式中,h0表示算法的目标熵,πt(at|st)表示当前策略;
49、步骤5:突防决策模型状态空间设计;
50、状态空间设计为:
51、
52、式中,表示高超声速飞行器与第i枚拦截弹的相对位置矢量,通过雷达对目标的探测以及自身惯组信息解算得到;ε,β分别表示飞行器自身的弹道偏角和弹道倾角,由自身惯组测量得到;△r表示飞行器和打击目标之间的径向距离,通过雷达对目标的探测以及自身惯组信息解算得到;consumefuel表示飞行器能量的消耗量,用于约束飞行器的机动大小;
53、在输入sac网络之前,手动缩放对不同的单位特征进行无量纲处理;
54、步骤6:突防决策模型动作空间设计;
55、采用过载指令信息作为智能体的动作空间:
56、nagent=[ny,γopt]
57、式中,ny.γopt分别是智能体产生的纵向过载和法向过载指令;
58、智能体输出的过载指令为连续变量;若得出决策为不机动,则输出0;
59、步骤7:突防决策模型奖励函数设计;
60、奖励函数将感知的状态信息映射为增强信号,用来评估动作的好坏;设置奖励函数为:
61、reward=reward_stage+reward_end
62、式中,reward_stage是阶段突防奖励,reward_end是使命任务奖励。
63、阶段突防奖励用于评价每一仿真步长中高声速飞行器机动决策的效果,具体表示为:
64、reward_stage=reward1+reward2
65、reward1=-consumefuel×k1
66、reward2=-k2×[rmt(i+1)-rmt(i)]
67、式中,reward1表示对能量消耗的惩罚项,用于约束飞行器在突防过程中的能消耗;reward2用来引导飞行器向预设打击目标方向不断飞行;rmt(.)表示高超声速飞行器与打击目标之间的相对距离。
68、使命突防任务用于评价高超声速飞行器是否完成对全部拦截弹的突防:
69、
70、其中,k1到k5为奖励项权重;
71、步骤8:突防决策模型终止条件设置:
72、
73、此式表示高超声速飞行器和拦截弹的相对距离开始变大时,可判断为突防过程结束。
74、优选地,所述h1=40。
75、优选地,所述步骤2中的拦截弹为两枚sm-6拦截弹。
76、本发明的有益效果如下:
77、本发明方法依靠高超声速飞行器上的弹载雷达探测敌方拦截弹的位置信息,输出机动过载指令以打破逆轨拦截态势、完成突防,具备决策速度快、突防效果稳定、能量消耗低的优势。
本文地址:https://www.jishuxx.com/zhuanli/20240730/200232.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表