一种基于数据驱动的控制系统关键部件故障诊断方法
- 国知局
- 2024-08-01 00:19:05
本发明涉及控制系统故障诊断,尤其涉及一种基于数据驱动的控制系统关键部件故障诊断方法。
背景技术:
1、控制系统关键部件参数众多,参数之间高耦合高关联,它是一个高度融合的软硬件集成系统,状态数据规模庞大。控制系统故障诊断是控制工程中的一个关键领域,其目标是检测、隔离并补偿控制系统中的故障。这是确保工业过程安全和高效运行的必要步骤,准确的故障诊断定位能够最大限度地保障复控制系统的运行效率。
2、随着传感器数量的增加和数据采集频率的提高,数据的维度和量都在急剧增长,这为数据处理和分析带来了挑战。但传统工业场景存在数据分布不平衡的问题,这会导致训练过程中的小样本问题。此外,数据的分布差异会导致泛化性能较差的专用模型无法实现高精度的诊断结果,这在变工况场景中尤为常见。
3、因此如何提供一种提高变工况场景下控制系统关键部件数据诊断精度的故障诊断方法,成为本领域技术人员急需解决的技术问题。
技术实现思路
1、本发明目的是提供了一种基于数据驱动的控制系统关键部件故障诊断方法,以解决上述问题。
2、本发明解决技术问题采用如下技术方案:
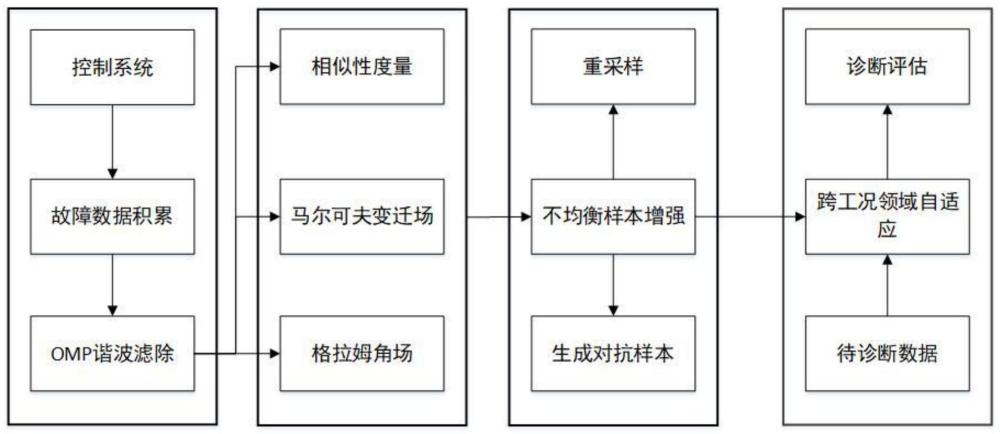
3、一种基于数据驱动的控制系统关键部件故障诊断方法,其特征在于,包括如下步骤:
4、步骤s1、积累不同设备历史运行过程中产生的时序信号,包含故障数据和正常数据;
5、步骤s2、对控制系统时序信号进行数据预处理,通过谐波滤除的方法进行故障特征增强;
6、步骤s3、建立控制系统时序信号多重特征提取技术,利用多模态特征提取技术将一维度信号,转换为二维图像化特征变量,输入信号为步骤s2中经过谐波滤除的时序信号;同时进行相似性度量、统计特征提取等传统特征工程;
7、步骤s4、针对数据正负样本比例不均衡的问题,采用重采样方式进行数据增强,通过gan网络和d-smote插值法扩充少数类样本;
8、步骤s5、建立领域自适应模型,针对不同工况下的数据,利用领域对抗学习网络训练域不变特征,通过分类器对域不变特征进行分类。
9、步骤s6、将待诊断数据通过同步骤s2、s3相同的数据预处理及图像化特征提取后,输入诊断网络,输出健康状态及故障概率。
10、进一步地,所述步骤s2具体包括:
11、对数据进行预处理,包括缺失值填充和归一化处理;
12、对数据信号进行谐波滤除,其步骤如下:
13、1)创建傅里叶字典f;
14、2)计算其中表示原始信号s与算法迭代匹配得到谐波分量sk的残差,k为迭代轮次,初始化为0。fk为之前轮次正交匹配过的傅里叶字典中原子的集合,fk初始化为0,gn为该轮次待匹配的原子集合,n为对应原子的索引;
15、3)寻找其中α为自适应比例参数,由7)中公式计算得到,sup表示集合上界;
16、4)如果则停止运算,ε为人工设定的阈值;
17、5)更新字典f,使
18、6)计算直到且<γk,gn>=0,n=1,…,k。其中为第k轮次正交匹配原子gn对应的系数集合,γk为第k轮次正交匹配的余项;
19、k+1轮次索引为n的原子gn的系数。
20、8)设置k←k+1,重复步骤2-8
21、通过omp算法来寻找最优局部解,匹配出谐波分量后用原始振动信号减掉,获取残差值,以此方法去除谐波,保留含有故障信息的冲击成分以及噪声。
22、进一步地,所述步骤s3具体包括:
23、通过格拉姆角场提取图像化特征,格拉姆角场的获取具体包括:
24、1)对于给定控制系统时间序列x=x1,x2,x3,…,xn
25、
26、其中为标准化后的序列,max()和min()分别表示最大值和最小值。
27、2)将缩放的时间序列通过下+公式在极坐标中表示出来。
28、
29、其中表示极角,r表示极径。
30、3)将重新缩放的时间序列转换到极坐标系中后,这时角度的取值范围为[0,π],接下通过计算每个点间的三角和或者差来表示不同时间间隔内的时间相关性。根据选取和或者差情况的不同,格拉姆角场可以分为格拉姆和角场(gasf)以及格拉姆差角场(gadf)。其中gasf定义如下:
31、
32、gadf定义如下:
33、
34、将2)中得到的代入上述两式即可得到格拉姆和角场以及格拉姆差角场通过马尔可夫变迁场提取图像化特征,马尔可夫变迁场的获取具体包括:
35、1)对于给定的时间序列x,将该时间序列分为的值域分为q个部分,使得该时间序列中任一xi都会被映射到相对应的q上;
36、2)沿时间轴为顺序,以一阶马尔科夫链的方式计算出数据点间的转移概率即可构造出一个q×q的加权解矩阵w。其中wi,j表示分位点qj转移到分位点qi的频率。通过∑jwij=1标准化后,生成矩阵w,w即为马尔科夫转移矩阵;
37、
38、进一步地,所述步骤s4具体包括:
39、分别利用gan网路和s-dtw的方法进行数据增强。
40、对于gan网路,其进行数据增强的原理在于对少数类样本进行样本生成实现过采样,其基本步骤包括:
41、1)确定数据集:首先,准备一个原始的、有限的数据集,该数据集包含了您想要进行数据增强的样本。这些样本可以是图像、音频、文本等。
42、2)构建gan模型:构建生成对抗网络,包含生成器(generator)和判别器(discriminator)。生成器负责生成合成样本,而判别器则负责区分真实样本和合成样本。
43、3)训练gan:通过训练gan来学习生成器和判别器的参数。训练gan的过程中,生成器试图生成逼真的合成样本以骗过判别器,而判别器则试图区分真实样本和合成样本。
44、4)生成合成样本:在训练完成后,使用已经训练好的生成器来生成合成样本。您可以通过从潜在空间(latent space)中抽取随机向量来生成不同的合成样本。
45、5)添加合成样本:将生成的合成样本添加到原始数据集中。这样,您的数据集将扩充为原始样本加上合成样本。
46、6)调整数据集:根据需要,对生成的合成样本和原始数据集进行混洗和调整,以确保数据集的平衡和多样性。
47、对于基于动态规整的过采样方法(sdtw),其进行数据增强的原理为smote的插值思想以及动态法规整距离的结合,其基本步骤为:
48、①首先,确定需要生成的少数类样本的总数:
49、g=(n--n+)×α
50、其中,n-、n+分别表示原数据中少数类、多数类样本数;α(0<α≤1)为调整程度,通常取1。
51、②对每一个少数类样本xi,计算它与其他样本之间的dtw距离和规整路径,根据dtw距离排序找出该样本的k个最近邻样本,计算比率:
52、ri=ki+/k,i=1,2,...,n+
53、其中,ki+为k个最近邻样本中属于少数类的样本数。
54、③设置阈值θ(0<θ≤1),根据阈值将比率ri划分为两个数值集合,分别对应样本集的两个不同区域:噪声集χnoise(ri∈[0,θ))和安全集χsafe(ri∈[θ,1])。考虑到噪声集带有错误敏感信息,不利于模型的学习过程,因此,属于噪声集的少数类样本不参与到人工样本合成过程。
55、④标准化安全集χsafe的样本的比率分布得到考虑到可能出现比率过小,导致样本被过度忽略的情况,采用指数函数进行平滑修正:
56、
57、⑤确定采样样本数:对安全集中的每一个少数类样本xi+,其采样样本数为
58、
59、其中表示向上取整。
60、⑥采样过程:对安全集中的少数类样本,随机抽取它的k个最近邻样计算规整路径,然后在规整路径的同步点之间进行插值,生成新的样本点;最后对采样时点进行调整,得到生成样本。重复生成以最终达到指定生成样本数。
61、进一步地,所述步骤s5,具体步骤包括:
62、构建领域自适应对抗学习模型,初始化特征提取器、领域鉴别器和故障分类器的网络参数;
63、训练特征领域鉴别器和故障分类器,在每轮迭代中首先固定领域鉴别器,训练故障分类器,再固定故障分类器,训练领域鉴别器;
64、选择故障分类器、领域鉴别器与源、目标的域推土机距离的加权和作为评估指标衡量网络的域不变特征提取质量,当指标达到预设值停止训练;
65、保存模型参数以便后续故障诊断。
66、进一步地,所述步骤s6具体包括:
67、加载保存好的故障诊断模型;
68、对输入数据进行同步骤2的数据预处理;
69、利用步骤s3中的特征提取方法对预处理后的数据进行图像化特征提取;
70、最终将特征提取后的数据输入训练好的网络,由故障分类器得到故障诊断结果和故障概率值。
71、有益效果:
72、1、本发明公开提供了一种基于数据驱动的领域自适应控制系统故障诊断方法,基于时间序列图像化方法,对采集数据进行深度故障特征提取;
73、2、本发明通过结合gan网络和基于动态规整的过采样方法,有效地扩充了少数类样本的数量和多样性,缓解了数据不平衡的问题。
本文地址:https://www.jishuxx.com/zhuanli/20240730/200572.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。