一种基于位线隔离和位线稳压的存内计算单元
- 国知局
- 2024-07-31 19:21:28
本发明涉及电路设计领域,尤其公开一种基于位线隔离和位线稳压的存内计算单元,属于基本电子电路的。
背景技术:
1、随着大数据、人工智能相关技术的快速发展,智能化的人机交互已经成为改善人们日常生产生活必不可少的手段,比如语音识别、人脸识别、自然语言处理等。声音作为人与人之间交流的媒介,包含了丰富的信息,由此也成为人机交互研究者们首选的对象。人类研究声音已经有几十年的历史,随着声学模型、机器学习(machine learning,ml)的快速发展,语音识别已经被广泛运用于日常生活中,比如手机产品中的小艺小艺、小爱同学,智能家居中的扫地机器人等等。
2、关键词唤醒(keyword spotting,kws)是语音识别的一个细分领域,它的识别对象是一个或者少数几个关键词,其任务是对特定的关键词进行检索,主要用于大型系统的前级唤醒模块,其相对简单的识别任务、需要保持常开(always on)的特性以及用于边缘设备的特点决定了关键词唤醒电路对功耗和能效具有极高的要求。目前关键词唤醒的主流算法为深度神经网络(deep neural network,dnn),由于网络模型较大,因此都是在云侧进行参数训练,再部署到端侧,即先在云端针对不同种类和数量的关键词进行训练,然后将训练好的参数部署到硬件平台上,这种方式避免了在端侧进行神经网络的训练,降低了边缘设备的硬件开销。然而,这种在云侧训练、端侧部署的方式也有其弊端,因为在云端的训练是基于官方的数据集,在数据集上的准确率可以做到很高,但是不同的用户在使用过程中,由于地区和口音的差异,会导致实际的准确率骤降,从而降低用户的体验。解决这个问题的方法是针对不同用户进行神经网络的再训练,即先在云端训练好权重,将其部署到硬件中之后,再根据不同用户的语音数据对网络进行再训练,对权重进行调整,从而提高实际场景下的准确率。重新练需要用户的私人数据,一种方法是将私人数据传到云端进行再训练,但是将私人数据传送到云端可能会造成数据泄露从而引发安全问题,并且数据上传的功耗也不容忽视。此外,在没有网络的场景更是无法在云端进行模型的更新。因此,关键词唤醒系统能够进行端侧的高能效片上训练(on chip training)便尤其重要。片上训练加速器的作用主要是为了解决云侧训练的参数在实际场景中准确率下降的问题,实际上是一种特殊的神经网络加速器,由于训练的过程包括了前向推理,因此片上训练加速器不仅需要支持推理,更重要的是能完成神经网络的反向传播,从而完成整个训练过程。
3、片上训练是一个参数迭代的过程,训练数据量庞大、迭代次数多、计算过程复杂多变,并且包含前向推理过程。而且关键词唤醒系统大多应用在边缘设备中,其供电以及算力资源都会严重受限,同时训练的复杂性又需要加速器具有较高的性能,否则训练过程便会非常缓慢,从而影响用户体验。综上所述,针对关键词唤醒应用,设计出一款能够进行高能效片上训练的关键词唤醒加速器是有价值并且有挑战性的。
4、片上训练加速器的核心就是高能效的计算单元。近年来,数字域存内计算的研究非常热门,数字存内计算技术也被应用于训练加速器中。一方面,相比于传统的用于神经网络计算的乘累加单元,数字存内计算单元具有极低的访存功耗,由于存内计算单元的特点是将数据存储在存储单元中,当输入数据到来时与存储单元中的数据计算,因此实现了“存算一体”,大大减小了访存开销,也被业界认为是实现超高算力的重要手段;另一方面,相比于模拟存内计算,数字存内计算单元具有更高的精度,因此更适用于高能效片上训练的关键词唤醒加速器。
5、计算单元是存内计算宏单元(macro)的核心电路,目前主流的基于sram的存内计算macro中,计算单元的常规实现方式是n个比特存储单元(bitcell)复用一个本地的计算单元,乘法器的一端接到bitcell的位线上,乘法器的另一端接到输入数据的端口上。该常规实现方式会造成计算电路产生较大的动态功耗,主要体现在两个方面。第一个方面,当bitcell中存储的值是“0”,并且位线在上次计算中读出的值也是“0”时,在预充阶段位线会发生从低电平到高电平的翻转,而在nmos传输管开启之后,位线需要放电,又会发生从高电平到低电平的翻转,即位线会产生毛刺,从而导致后续电路的无效翻转,增加电路的动态功耗。第二个方面,对于多比特数据输入的情况,数据是串行输入进计算单元的,常见的控制策略会导致位线(bitline,bl)无效翻转等情况,造成不必要的功耗开销。
技术实现思路
1、本发明的发明目的是针对上述背景技术的不足,提供一种基于位线隔离和位线稳压的存内计算单元,通过在存储单元位线和计算单元输入端之间插入三态反相器解决存储单元位线产生的毛刺导致后续电路无效翻转的技术问题,通过在预充管供电电源和存储单元位线之间插入位线稳压模块解决数据串行输入至计算单元时存储单元位线电压不稳定的技术问题,实现降低存储器位线电压无效翻转导致的动态功耗、降低预充和字线开关功耗、保证计算结果正确性的发明目的。
2、本发明为实现上述发明目的采用如下技术方案:
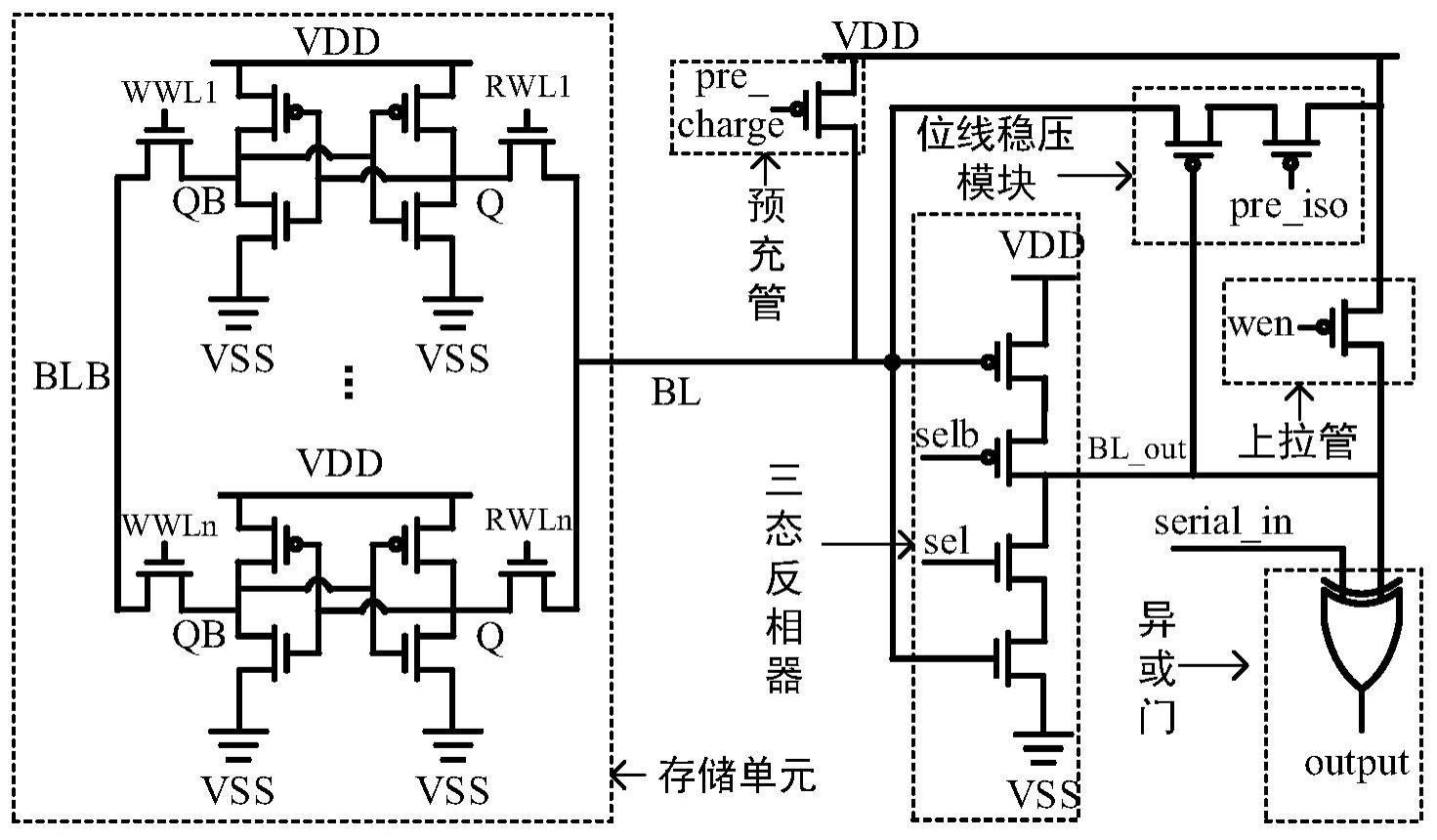
3、基于位线隔离和位线稳压的存内计算单元,包括:存储单元、预充管、三态反相器、计算单元。预充管的电流输入端接供电电源,预充管的控制端接入预充控制信号,预充管的电流输出端连接存储单元的位线,用于根据存储单元的存储值对存储单元位线进行放电操作。三态反相器的输入端连接存储单元的位线,在存储单元位线放电期间隔离位线和计算单元。计算单元的一个输入端连接所述三态反相器输出端,计算单元的另一个输入端接入计算数据,输出从存储单元读取的数据和计算数据的计算结果。
4、作为基于位线隔离和位线稳压的存内计算单元的进一步优化方案,存内计算单元还包括在三态反相器输出为0期间开启的位线稳压模块,位线稳压模块的电流输入端接供电电源,位线稳压模块的控制端连接三态反相器输出端,位线稳压模块的电流输出端连接存储单元位线。
5、作为基于位线隔离和位线稳压的存内计算单元的进一步优化方案,存内计算单元还包括上拉管,上拉管的电流输入端接供电电源,上拉管的电流输出端连接三态反相器的输出端,上拉管的控制端接入写使能信号。
6、作为基于位线隔离和位线稳压的存内计算单元的进一步优化方案,三态反相器由第一pmos管、第二pmos管、第一nmos管、第二nmos管堆叠而成,第一pmos管的源极接供电电源,第一pmos管的漏极连接第二pmos管的源极,第二pmos管的漏极与第一nmos管的漏极相连接作为三态反相器的输出端,第一nmos管的源极连接第二nmos管的漏极,第二nmos管的源极接地,第一pmos管的栅极与第二nmos管的栅极相连接作为三态反相器输入端,第二pmos管栅极接第一选择信号、第一nmos管栅极接入第二选择信号,所述第一选择信号和第二选择信号反相,第一选择信号在存储单元位线放电完成后拉高。
7、作为基于位线隔离和位线稳压的存内计算单元的进一步优化方案,位线稳压模块由左右两个pmos晶体管堆叠而成,从左到右依次是第三pmos管、第四pmos管,第四pmos管的源极作为位线稳压模块的电流输入端接供电电源,第四pmos管的漏极连接第三pmos管的源极,第三pmos管的漏极作为位线稳压模块的输出端连接存储单元位线,第三pmos管的栅极作为位线稳压模块的控制端连接三态反相器输出端,第四pmos管的栅极接入在第一次读数据时拉高在第一次读取数据完毕后拉低的控制信号。
8、作为基于位线隔离和位线稳压的存内计算单元的进一步优化方案,上拉管由第五pmos管组成,第五pmos管的源极作为上拉管的电流输入端接供电电源,第五pmos管的漏极作为上拉管的电流输出端连接三态反相器输出端,第五pmos管栅极作为上拉管的控制端接入写使能信号。
9、作为基于位线隔离和位线稳压的存内计算单元的进一步优化方案,计算单元为异或门,用来完成单比特的乘法运算,异或门的两个输入信号为三态反相器输出信号和计算单元输入信号,输出三态反相器输出信号和计算单元输入信号的乘法计算结果。
10、本发明采用上述技术方案,具有以下有益效果:
11、(1)相较于传统的计算单元,本发明所提存内计算单元利用三态反相器将预充阶段位线产生的毛刺与后续电路进行隔离,从而避免后续电路的无效翻转和动态功耗,解决了常规计算单元的预充操作让位线产生毛刺的技术问题。
12、(2)相较于传统的计算单元,本发明所提存内计算单元利用位线稳压模块保持bl在多周期计算时的电压稳定,,面向高效能关键词唤醒片上训练加速器等输入数据串行输入的场景,采用对于相同输入数据的多周期计算只预充一次的方式,降低多次预充导致的计算电路的计算次数,减小预充操作带来的功耗和无效翻转,避免了数据串行输入时bl漏电导致的计算出错,解决多周期串行输入数据只预充一次导致位线漏电的技术问题。
13、(3)相较于传统的计算单元,本发明所提存内计算单元利用上拉管在写操作期间对异或门的一个输入端进行电压钳位,避免了写操作期间异或门产生较大的静态功耗。
本文地址:https://www.jishuxx.com/zhuanli/20240731/182379.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表