基于k-shape的交叉口信号控制多时段划分方法
- 国知局
- 2024-07-31 20:40:19
本发明涉及道路交叉口交通控制多时段划分方法,尤其涉及一种基于k-shape的交叉口信号控制多时段划分方法。
背景技术:
1、定时式控制仍然是目前交叉口信号控制的主要方式。但实际的交通情况复杂多变,存在时效性差的问题,通常需要在定期对现有的信号控制方案进行调整。因此,如何提升定时式信号控制中分时段控制的效率是城市交通信号控制需首要解决的关键问题。
2、单点交叉口多时段信号配时优化是缓解道路交通拥堵、提高通行能力和减少交通延误的重要手段,其核心思想是在交叉口信号配时优化过程中,根据一天中交叉口交通流的变化规律,将一天划分为几个交通流状态相同的若干个控制时段。其主要划分方法有粗糙方法、启发式搜索算法、聚类分析算法等。在启发式算法方面,park引入贪婪搜索算法划分控制时段,考虑控制配时方案过渡期间带来的损失,优化每个单位时间的配时参数,以每个单位时间内周期为层次聚类的输入变量初步划分时段,最后利用贪心算法搜索初始时段划分点附近一些可能划分点。这种方法对于初始划分点比较敏感,而且最佳聚类数目无法确定。国内外对于交叉口多时段划分方法研究大多集中于聚类分析算法方面。wang等基于流量数据,采用k-means聚类方法划分交叉口时段,通过各个进口车道的流量数据进行时间转换点的识别。后续很多时段划分的方法都是基于k-means算法衍生而来的。但k-means等聚类算法是一种通用聚类算法,它对于时间序列数据的聚类效果可能并不理想,因为它没有考虑时间序列数据的特殊性。且假设簇是凸形状的,但是交叉口的多时段数据可能包含非凸形状的模式。此外,k均值聚类算法进行交叉口的多时段划分时,存在部分时段划分持续时间过短的问题。为了划分的结果能够在实际中正常运行,会将持续时间段的划分时段归并到其相邻时段中,存在一定的主观性。
技术实现思路
1、发明目的:针对现有技术中存在的不足之处,以及考虑到交通流量数据为时间序列数据,随时间呈现不同的趋势且具有一定的规律性,本发明提出一种基于k-shape的交叉口信号控制多时段划分方法,通过采用k-shape算法在交通控制时段划分时进行形状的相似性匹配以及适应不同长度的时间序列,并由calinski-harabasz(ch)指数和轮廓系数法确定聚类数目,解决了传统需要人工确定k值的缺陷,为交叉口的信号配时多时段划分提供了新思路,且在不同时段缓解道路交叉口的拥挤程度,提高了交叉口的运行效率。
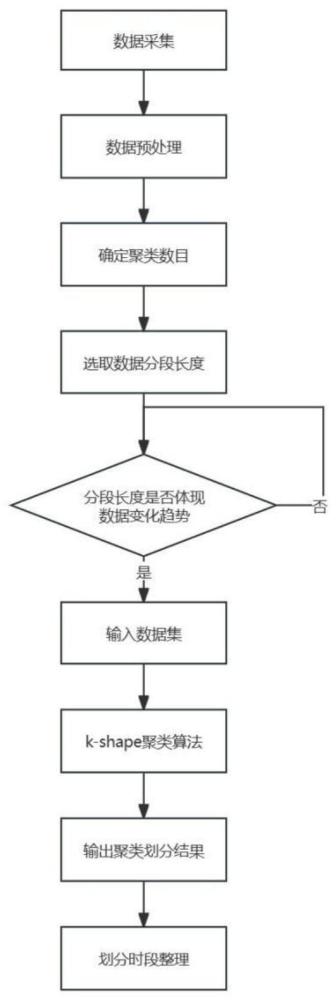
2、技术方案:本发明基于k-shape的交叉口信号控制多时段划分方法包括以下步骤:
3、(1)数据准备与采集:在交叉口获取每个进口道的车流量时序数据,若要正确反映出不同时段的流量变化趋势,则对时序数据进行拆分。若对每个进口道的数据都进行分段,那么聚类完成后的时段划分将造成混乱。因此,将进口道的数据合并,形成交叉口24小时的交通流量数据。
4、(2)数据预处理:采用z标准化对交叉口24小时的各进口道总交通流量进行数据标准化,z标准化的步骤如下:
5、先计算每个时间序列均值μ和标准差σ:
6、
7、
8、其中,n是时间序列的长度,qti是第i个时间点的交通流量。
9、然后z标准化每个时间序列其中是z标准化后的第i个时间点的交通流量;进而确保每个维度对于距离计算的贡献是相等的,避免了数值范围不同对距离度量的影响。
10、(3)k值确定:在采用k-shape聚类算法前预先确定聚类数即k值。首先根据交叉口的交通流量的变化情况按照人工经验初步确定k值的取值范围。对于给定的k值范围,再利用calinski-harabasz(ch)指数和轮廓系数法进行进一步确定k值。ch指数关注簇内相似性和簇间差异性的比值,而轮廓系数综合考虑了簇内相似性和簇间差异性,因此在选择聚类簇的数量k时,通过最大化ch指数及轮廓系数来确定最佳的k值,过程为:
11、(3.1)ch指数包括簇内离散度和簇间离散度。簇内离散度度量了簇内数据点之间的紧密度,其中wk是第k个簇的簇内离散度,ci是第i个簇,μi是簇ci的中心,即同一个簇内的数据点越紧密越好,通常使用簇内协方差矩阵的迹来表示。簇间离散度度量了不同簇之间的分离度,其中,bk是第k个簇的簇间离散度,ni是簇ci中的数据点数量,μ是全局数据的中心,即不同簇之间的数据点越分散越好,通常使用全局协方差矩阵的迹来表示。对于给定的k值范围,分别计算每个k值对应的ch指数,并选择使得ch指数最大的ka值作为最优的簇数,计算公式为:
12、
13、其中,ch(k)代表k值范围内每个k值所对应的ch指数。
14、(3.2)利用轮廓系数检验(3.1)步骤确定的ka值。且轮廓系数取值范围在[-1,1]之间。当轮廓系数的值接近1表示簇内的紧密度高,簇间的分离度也高,聚类效果较好。轮廓系数的值接近0时表示簇内的紧密度和簇间的分离度相近,聚类效果一般。接近-1时表示簇内的紧密度低,簇间的分离度低,聚类效果差。通过比较选择的k值范围内的轮廓系数,来确定最优的聚类数目,计算公式如下:
15、
16、其中,s(i)是第i个数据点的轮廓系数;a(i)是数据点i到同簇其他点的平均距离;b(i)是数据点i到最近异簇点的平均距离。
17、将k值与相应的轮廓系数绘制成图形,找到轮廓系数最大的点对应的kb值即为最佳k值。最后检验kb=ka。如果两值的结果一致,即同一个k值在两种方法中均表现较好,则选择这个k值。
18、(4)采用k-shape算法对不同时段长度进行对比分析:将交通流的趋势分为上升趋势,下降趋势与无明显趋势。在上升趋势中,交通流从低峰趋向平峰或者平峰趋向高峰,若由低峰趋向高峰时中间平峰持续时间短,则会呈现出上升幅度大的形状。下降趋势是从高峰趋向平峰或由平峰趋向低峰。无明显趋势为平峰时段,交通流起伏波动较多。根据上述趋势选取不同的时段长度进行对比分析,合适的时段长度必然能很好的体现出上述趋势形状。具体的长度选取应根据交叉口的流量调查情况进行判断。如果选择的时段长度过长,那么交通流量变化趋势中一些细节会被掩盖;如果过短,难以体现交通流的变化趋势。为规避相同类别时间段不连续,有较多分段,实际应用过程中使控制方案切换较为频繁。设置每个时段的长度均在2h以上,且划分好类别与早、晚高峰对应较紧密且符合实际情况。本发明先使用互相关度量来度量时间序列的形状相似性,再使用shape-based distance(sbd)距离计算将形状相似性转化为一个距离度量。k-shape聚类利用互相关度量和sbd距离的步骤如下:
19、(4.1)选取时段长度m进行数据分段,组成一个时间序列输入数据集其中是以组成的一组时间序列,表示m时刻的交通量数值,其它组以此类推。数据分段后组的个数为t为数据总数。
20、(4.2)选择初始聚类中心,即初始簇心。先对于每个分段,从分段内随机选择一些索引序列作为初始簇心,确保所选的初始簇心代表分段内的不同形状和模式。因此,覆盖分段内不同的时间序列形态,避免在同一分段中选择相似的时间序列。
21、(4.3)计算互相关度量:计算每对时间序列和簇心(索引序列)在不同时间滞后下的互相关度量,即在时间轴上滑动两个序列,并比较它们的重叠程度。在互相关计算中,一个序列被滑动到另一个序列上的不同位置,通过比较它们之间的相似性来生成一个新的序列。这个新的序列的值反映了两个序列在不同时间点上的匹配程度,其中较大的值表示更好的匹配。在进行相似度比较时,使用零填充(zero-padding)来解决长度不同的问题,使簇心和时间序列的长度相等。如果簇心的长度小于时间序列的长度,采用在簇心的末尾添加零的方式,以使簇心的长度与时间序列相等。通过零填充,在不同长度的簇心和时间序列之间进行互相关计算,确保它们有重叠区域。假设有时间序列和索引序列序列长度均为m,为实现平移不变性,设滑动窗口为s,保持y不变,一步一步滑动x计算两个序列之间的内积:
22、
23、式子中s的取值范围为[-m,m]。
24、定义长度为2m-1的互相关序列w为所有移动的次数。互相关序列的计算公式为:
25、
26、其中,的依次计算按如下公式进行:
27、
28、s=k=w-m
29、利用r计算x和y在每一步的相似度,最终r是有效区域的点积之和(对每个对上的小块加和)。r越大两个序列越相似。上述计算的目标是找到w的位置使得互相关序列最大。如此,相对于的最佳偏移量就在w位置确定下来。然后进行归一化处理来消除固有的畸变,具体计算如下:
30、
31、表示互相关序列归一化。
32、(4.4)计算sbd距离:使用选定的在计算中比较时间序列和簇心之间的形状相似性,取最相似的然后用得到sbd,即形状越相似,距离sbd越小。归一化后的ncc值在[-1,1]之间,因此,sbd值在[0,2]之间。将形状信息转化为一个距离值,公式如下:
33、
34、表示两时间序列之间相似性的距离值。
35、(4.5)对于每个时间序列,找到距离值中对应的最小值,表示该时间序列与所对应簇心的距离最小。找到全部最接近的簇心的时间序列,并将时间序列分配到最小距离对应的簇。
36、(4.6)计算每个簇的所有成员的平均形状。对于已经进行了簇分配的每个簇,首先确定该簇内的所有成员时间序列,并对齐时间序列,以确保它们在相同的时间点上具有对应的数据。计算每个时间点上所有簇成员的值的平均,得到了一个平均形状的时间序列,以此类推。将计算得到的平均形状作为该簇中所有时间序列的更新簇心。确保了簇心反映簇中时间序列的整体形状。即具有k个簇的时间序列,每个序列长度为m,对于每个时间点t,计算平均形状的值jt如下:
37、
38、其中,ai,t表示第i个簇成员在时间t处的值。
39、(4.7)重复步骤(4.3)、(4.4)、(4.5)和(4.6),k-shape聚类重新计算每个时间序列与新簇心之间的距离,并根据最小距离重新分配时间序列到最近的簇;然后,再次更新簇心。这个过程迭代进行,直到满足收敛条件,即簇心不再变化或达到预定的迭代次数。
40、(5)利用可视化图展示聚类结果:将输出后的聚类中各组数据进行趋势比对,将各组数据划分到其所属的簇中,形成聚类可视化图。此时已经完成了基本的时段划分,再结合交通量的实际情况进行时段的组合微调,即完成交叉口多时段划分的目标。
41、步骤(1)中,将采集的交通流量数形成时间序列数据q,q有t个数据,则对于一维样本数据表示i时刻的交通量数值。如,将一天24h根据相位以15min为间隔,得t=96。
42、步骤(2)中,采用z标准化时,通过减去均值并除以标准差,将数据转换为均值为0,标准差为1的标准正态分布从而对交叉口24小时的各进口道总交通流量进行数据标准化。
43、步骤(4)中,设置时段长度大于2小时。
44、步骤(4.2)中,所选的初始簇心代表分段内的不同形状和模式。
45、步骤(4.3)中,计算每对时间序列和簇心在不同时间滞后下的互相关度量时,在时间轴上滑动两个序列,并比较重叠程度。
46、步骤(4.5)中,找到全部最接近的簇心的时间序列,并将时间序列分配到最小距离对应的簇。
47、步骤(4.6)中,对已经进行了簇分配的每个簇,首先确定该簇内的所有成员时间序列,并对齐时间序列。
48、有益效果:与现有技术相比,本发明具有以下优点:
49、(1)本发明基于k-shape的交叉口信号控制多时段划分方法中采用的聚类算法专注于处理时间序列的形状相似性,而不仅仅是考虑数据的数值。对于处理非凸形状的数据有优势,能够更灵活地适应不同的交通模式,更适用于不同时段交叉口数据。使其在交通控制时段划分中更具鲁棒性和准确性,为智能交通管理提供了一种强有效方法。
50、(2)本发明所采用的k-shape聚类算法能够识别出具有相似形状的交通流量模式,从而划分出不同的时段,有助于更精细地理解不同时间段的交通特征,且对异常值具有一定的鲁棒性,避免受到异常值的干扰,增强了时段划分的稳健性,使得时段划分更为精准,为交叉口的信号控制和交通管理提供个性化策略。
本文地址:https://www.jishuxx.com/zhuanli/20240731/187328.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
上一篇
防盗装置和系统的制作方法
下一篇
返回列表