一种基于多智能体强化学习的交通自适应控制方法
- 国知局
- 2024-07-31 20:40:01
本发明涉及智慧交通,具体为一种基于多智能体强化学习的交通自适应控制方法。
背景技术:
1、自适应交通控制方法是能够应对日益增长的交通需求,缓解道路交通拥堵的有效方法之一。
2、现有的相关技术大多数的交通自适应信号控制(atsc)多智能体视角的工作都集中在基于独立优化的方法,这些方法主要强调其他协调智能体的局部观测和信息,并没有很好的将多个交叉口同时处理交通流的多智能体环境中的长序列决策问题,且现有很多框架的最佳实践应并不能简单地用于交通自适应信号控制系统之中。
3、采用多智能体强化学习的交通自适应信号控制(atsc)方法与整个交通系统环境进行交互,并通过学习来控制信号灯,对于信号配时是有效的解决方法之一,本发明在此基础提出了一种基于优先经验回放机制的sac(soft actor-critic)多智能体强化学习网络(mper-sac)来解决交通自适应信号控制问题。
技术实现思路
1、本发明的目的在于提供一种基于多智能体强化学习的交通自适应控制方法,以解决上述背景技术中提出问题的至少一个。
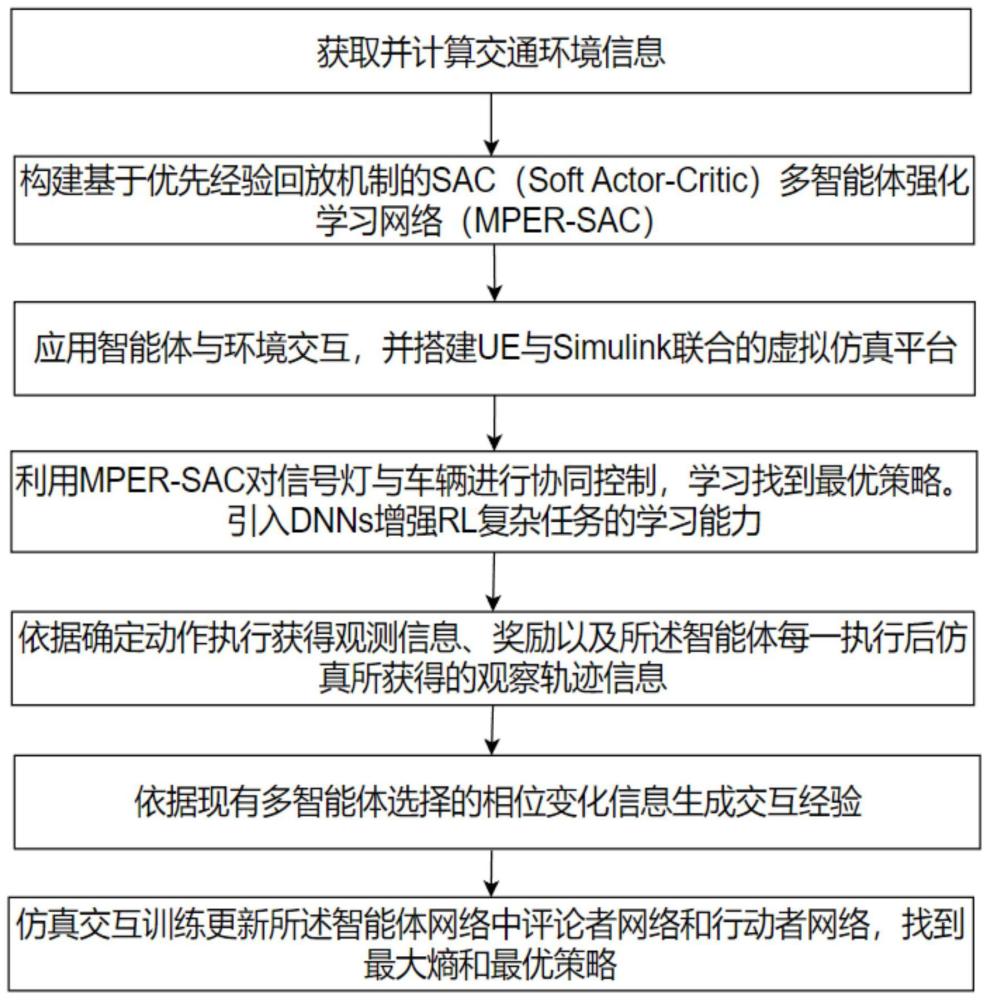
2、为实现上述目的,本发明提供一种基于多智能体强化学习的交通自适应控制方法,包括如下步骤:
3、s1:获取道路交通环境的交通信息并计算道路交通环境的信息;
4、s2:根据相关定义以及现有交通路网,建立与各个交叉路口对应的智能体,所述智能体包括整个交通场景中的特殊交叉路口与普通交叉路口的智能体;依据现有交通环境,定义区域中交通信号多智能体强化学习框架,并对交通路网中各个交叉路口进行排序,确定各个交叉路口的相位选择顺序;
5、s3:构建基于优先经验回放机制的sac多智能体强化学习网络,智能体与环境交互并积累交互数据且各智能体之间进行状态信息的交互,优化交叉口的信号控制策略,间接实现区域交通联合控制,并搭建ue与simulink联合的虚拟仿真平台对其仿真;
6、s4:获取交通路网中各个交叉路口的实时交通特征,针对于各个交叉路口对应的智能体,根据各个交叉路口的实时交通特征获得其智能体本身和邻居智能体的观测信息,从而获得相邻智能体的联合动作;
7、s5:根据多智能体执行确定的联合动作,获取执行动作后的观测信息、奖励以及智能体每次执行后仿真所获得的观察轨迹信息;
8、s6:利用现有的车辆行车轨迹信息和多智能体选择的相位变化信息,生成交互经验;
9、s7:利用仿真后的交互经验,实时更新智能体中的评论者网络和行动者网络,以找到最优策略。
10、进一步地:所述多智能体强化学习框架,其中由马尔可夫博弈过程对多个路口交通灯进行决策定义,并定义其中的智能体i、动作状态s、状态转移概率p和奖励rt,i;
11、所述智能体i构成智能体集合i,i∈i,i={i|i=1,2,3,…,n},其中n为自然数;
12、所述状态:对于任意时间t,智能体都会收到一个局部的观测所有的新环境状态的观测为
13、进一步地:所述局部的观测是由智能体的当前相位和交叉路口周围的交通状况组成,所有的观测值构成了状态空间s,定义如下:
14、
15、其中,l是智能体i的每个进入车道,awtt[s]测量当前相位车辆的总累计等待时间,wave[veh]主要测量沿每个车道以及接近交叉路口不超过50m的车辆总数。
16、进一步地:所述动作对应任意时间t,具体如下:
17、智能体i采取一个动作从而为下一个tp时间段选择对应的相位操作为p,所述整个的智能体i的动作空间为a;
18、其中,p为单个智能体所有可能相位的数量集合;
19、如果动作与当前的绿灯相位相同,此相位的绿灯时间将被延长一个特定的时间间隔tk,绿灯同时也被切换到相位ak,其中时间间隔tk定义如下:
20、
21、其中为相位ak对应的最小绿灯时间,为相位ak对应的黄灯时间,为相位ak对应的全红时间。
22、进一步地:所述状态转移概率依据当前给定的局部的观测以及通过这一阶段的智能体i所采取的的该状态下的动作得到对应的转移概率函数p为:
23、s×a×s→[0,1];
24、其中,a为智能体i的空间动作。
25、进一步地:所述奖励rt,i定义如下:
26、
27、其中,a为权衡系数,单位为veh/s;
28、queuet+δt为沿着每个传入车道测量的队列长度;
29、awtt+δt为当前相位车辆的总累计等待时间。
30、进一步地:所述构建基于优先经验回放机制的sac多智能体强化学习网络,具体规则为:通过在训练过程中引入优先级经验回放采样机制,同时根据critic和actor的误差计算td误差,使td误差较大的样本有更大的概率被采样及训练,并使网络优先训练估值误差较大和策略表现不好的样本,主要通过两个部分实现;
31、第一部分采用sac算法,其最大化熵值算法sac优化目标定义如下:
32、
33、其中,e为当前状态的回报数学期望,ρπ是策略π下轨迹的分布,h是用于计算策略π的熵值,λ用于控制关注熵和奖励;
34、进一步为了在交通环境下减少值函数的估计误差,从而在ac体系的基础上增加了价值网络,主要由1个actor网络以及4个critic网络组成,分别又代表了状态价值估计v和target v网络,由v critic表示;动作-状态价值估计qi网络,由q critic表示;其步骤主要有如下相关操作:
35、已知每个交叉口t时刻交通环境中的状态通过actor网络就能得到所有动作概率为依概率采样得到相对应的再将输入到动态交通环境中得到和获得experience:放入到迭代经验池当中;
36、在q critic的网络中,就从经验池当中采样取出数据并且进行网络参数ω的更新,并将动作的值即为的预测价值估计,再依据最优bellman方程得到作为状态的真实价值估计:
37、
38、其中,eπ即为当前状态得累计回报期望;
39、γ为折扣因子;
40、r为所有奖励rt,i构成的集合;
41、再利用均方损失函数作为损失,对于q critic网络进行训练,损失函数定义为:
42、
43、其中b为从经验池当中取出一个batch的数据大小;
44、对于v critic网络,利用经验池采样取出数据再对网络参数θ更新,v critic网络输出的真实值如下:
45、
46、其中,a′t为为actor网络的策略π预测的下一步智能体的所有可能采取的动作;
47、为熵值;
48、依据v critic网络输出的真实值计算v critic网络的损失函数,其定义如下所示:
49、
50、在actor网络中,进行对应的梯度下降训练对应的损失函数定义如下所示:
51、
52、再通过时序差分误差衡量算法的修正幅度,采用计算td误差值的方式对策略选择的动作进行评估,即对定义的td误差值δi评估,其定义如下所示:
53、
54、其中,q为critic的状态价值;
55、进一步地,因为per-sac算法的td误差考虑三部分网络的误差进行简单相加,但由于策略网络π的输出是整个交通环境agent采取不同动作的概率,其概率值不超过1,而q网络的输出则是对当前状态下采取动作后得到的累计汇报的期望值,该值会由于不同交通环境差异值很大,其绝对值远大于1,如果对其进行误差绝对值相加就会出现策略网络π误差部分对整体的评估影响较小,所以需通过引入参数β进行适当放大,得到总的td误差计算方法如下所示:
56、δj=abs(td(q))+abs(td(v))+βabs(td(π));
57、利用其进行更新经验池,随着训练的进行,整个经验池的样本误差都被替换为真实的td误差,从而最大程度发挥算法性能;
58、第二部分引入优先经验回放机制,设计改进后的mper-sac算法,其定义整个样本权重为样本采样训练时的td误差,td误差越大,优先级就越大;
59、依据定义的td误差值δj进行样本采样概率计算,其定义如下所示:
60、
61、其中,κ是优先级中的控制系数,即为样本j的权重系数;
62、然后再引入重要性采样来更新样本训练时梯度的误差权重其中l为整个经验回放池的容量大小;
63、最后使用计算出的重要性采用权重对q网络和v网络进行损失函数更新:直至奖励最优。
64、进一步地:所述步骤s4,为了进一步提高策略和值的逼近度,还引入深度神经网络dnns,具体地:
65、采用一种基于长短期记忆网络lstm的方法,lstm网络通过维护隐藏状态来记忆短期历史,从而提取状态的表示特征,在网络结构方面,该方法采用了单独训练参与者和lstm的方式,并使用全连接层和lstm层来处理输入和输出,提高策略和值的逼近,进而提高交通效率。
66、本发明具的有益效果为:提出利用优先经验回放机制的sac(softactor-critic)多智能体强化学习网络(mper-sac)来解决交通自适应信号控制,整个网络优先训练值估计误差较大和策略表现不好的样本,从而提高了整个智能体训练过程中的稳定性与收敛速度;实现将全局奖励最优分配给各个单个智能体,使得智能体能够根据此选择对全局有利的动作,从而提高整个交通道路信号控制的整体性能;将强化学习与深度神经网络结合,进一步提高策略和值的逼近度。
本文地址:https://www.jishuxx.com/zhuanli/20240731/187305.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表