考虑不平衡数据的道路交通事故双阶段生成增强网络模型
- 国知局
- 2024-08-08 16:53:18
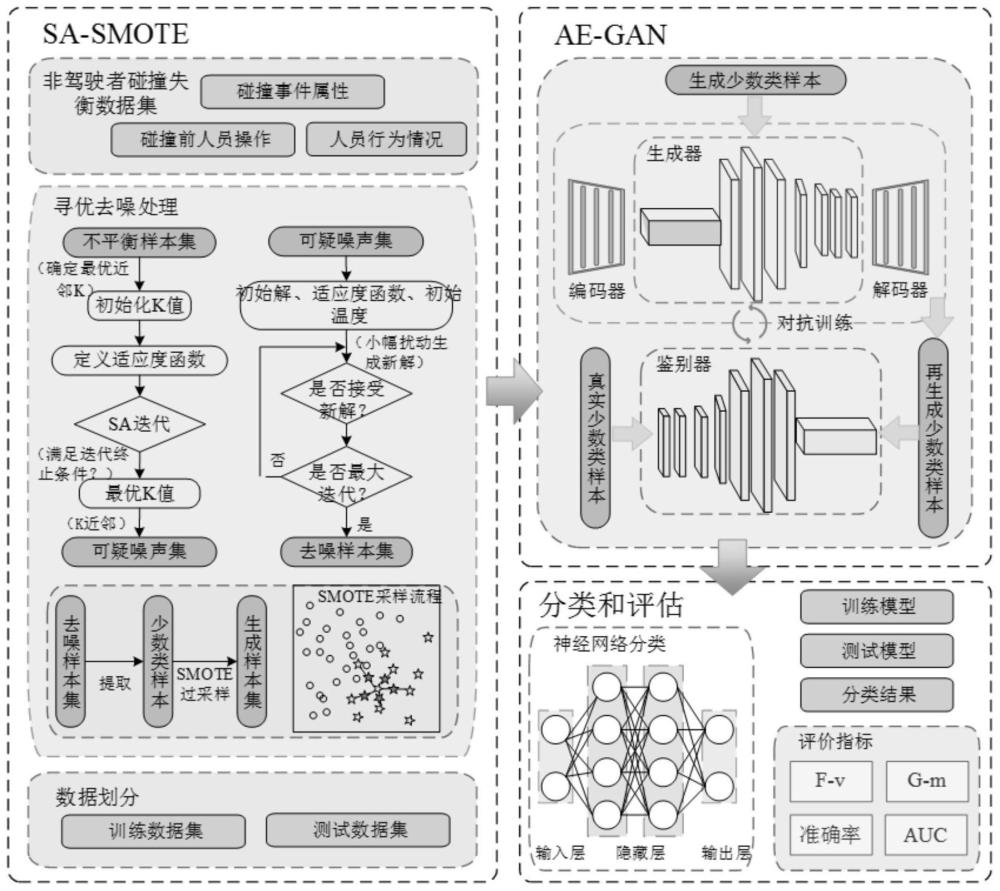
本发明属于网络模型,具体涉及一种考虑不平衡数据的道路交通事故双阶段生成增强网络模型。
背景技术:
1、在交通事故研究中,由于致命伤害相对稀缺,各类别之间的碰撞数据存在失衡,这对监督学习的训练带来巨大的挑战。交通安全研究中常用的统计模型也无法解决样本不平衡问题。因此,如何高效实现类间平衡成为交通安全研究的热点。
2、具体就碰撞数据而言,事故中多数类(碰撞非致命)的损伤严重程度预测准确率远高于少数类(碰撞致命)。致命碰撞是罕见的,因此处理伤害数据的极端不平衡对模型预测是必不可少。为解决数据不平衡问题,不同的数据再平衡方法被提出以提高预测模型性能。其中,合成少数过采样技术(smote)是被广泛应用的过采样方法。在道路安全研究中,现有技术将smote作为不平衡的数据处理对策。现有技术采用smote的改进算法进行处理,如多数加权少数过采样(mwmote)、边界过采样(borderline-smote,bl-smote)、自适应合成过采样(adasyn)以及其它变种方法。但smote生成样本过程存在一定盲目性,可能导致“分布不均”、噪声和无信息的问题。smote的改进方法针对其问题做了一定改进,但仍存在参数敏感性弱和生成样本多样性不足的问题。除此之外,在深度学习中应用也有一定限制,尤其不能直接适用于高维、复杂结构的深度学习数据。生成对抗网络(gan)及其变体数据增强技术是新兴的深度学习数据增强技术,通过两个深度学习的协同作用生成真实数据属性的“假”样本,有助于平衡类分布避免过拟合。在交通领域中,现有技术基于gan对追尾事故进行数据填补,就是还有利用深度卷积生成对抗网络(dcgan)、图自编码-生成对抗网络(dvgae-gan)和wasserstein梯度惩罚生成对抗网络(wgan-gp)的深度学习策略有效解决数据不平衡问题。但由于它们被设计为仅对单个标签数据进行训练,无法生成合成输入序列和相应的标签,因此gan在不平衡问题上的应用面尚窄。
技术实现思路
1、针对上述gan在不平衡问题上的应用面尚窄的技术问题,本发明提供了一种考虑不平衡数据的道路交通事故双阶段生成增强网络模型,通过借鉴迁移学习思想,构建双阶段生成增强网络框架。结合启发式算法simulated annealing(sa),以及嵌入自编码器组件(autoencoder,ae)克服其各自存在的不足。。
2、为了解决上述技术问题,本发明采用的技术方案为:
3、考虑不平衡数据的道路交通事故双阶段生成增强网络模型,包括下列步骤:
4、s1、收集数据,并对数据进行预处理;
5、s2、基于模拟退火改进smote解决近邻插值过程中参数固定和噪声影响的问题;
6、s3、嵌有自编码器组件的生成对抗网络;
7、s4、利用人工神经网络进行分类预测;
8、s5、使用shap进行模型解释。
9、所述s1中收集的数据来源于flhsmv数据库,采用2011-2019年佛罗里达州公共道路上发生非机动车交通事故报告和统计数据。
10、所述s1中对数据进行预处理的方法为:通过梳理报告内容和非机动车事故数据集,采用代码对基本信息进行总结,同时在整理过程中剔除存在变量信息严重缺失的事故记录。
11、所述s2中基于模拟退火改进smote解决近邻插值过程中参数固定和噪声影响的问题的方法为:
12、使用sa找到最优采样率,并将基于k最近邻的可疑噪声视为sa中的状态或解的一部分,这些状态通过一个状态向量表示,每个状态被编码为一组参数,其中每个参数表示对应的可疑噪声的处理决策,将每个状态看作是一个sa的解,假设少数类的k个最近邻中有r个可疑噪声,那么sa-smote中的状态向量表示为:
13、s=(s1,s2,....,sr)
14、其中si表示对应可疑噪声的处理决策,这个决策向量是一个二进制向量,其中1表示保留该可疑噪声,0表示消除;
15、将f-λ值作为适应度函数衡量sa-smote中的每个状态,并反映出原始数据集去噪的合理程度,根据每个噪声处理方案的每个状态去除真实的噪声样本,然后在去除噪声后,应用smote方法以获得平衡的样本集,f-λ值的计算方法为:
16、
17、其中,recall为召回率,precision为精确率;
18、在适应度函数f-λ的指导下,获得了适应度值最优的状态,这个状态代表最优的噪声处理方案,通过采用这个最优方案,能够有效地去除噪声;在sa的迭代过程中,状态通过温度参数的调整和随机搜索逐渐优化,以找到在数据集中保留假噪声的最佳策略。
19、所述s3中嵌有自编码器组件的生成对抗网络的方法为:
20、自编码器通过学习输入和输出之间的潜在特征空间来计算非线性映,在学习潜在信息的同时将其投影到潜在空间,从而确保生成器在生成过程中保持对原始数据的重构能力,自编码器的目标函数lrec表示为:
21、
22、gan通过内部生成模型和判别模型的对抗训练引导生成器学习高度区分的特征,促使生成器和判别器反复竞争学习,优化两个网络性能;gan网络的目标函数lgan为:
23、
24、其中,ex~pdata、ex~pz(x)不是变量,ex~pdata表示对于从真实数据分布pdata(x)中采样的随机变量x的期望;ex~pz(x)表示对于从生成数据分布pz(x)中采样的随机变量x的期望;
25、通过最小化自编码器和生成对抗网络的结合,促进ae-gan生成更逼真、更接近真实世界的数据,生成数据的特征表达层次性也有所提高,总体目ae-gan目标函数lae-gan表示为:
26、lae-gan=λlrec+βlgan
27、其中zn=fn(xn),xn表示样本,fn表示编码器,gn表示解码器,g(z)是生成器的输出,n代表训练样本量,d(·)是鉴别器,z潜在空间中采样的随机向量,pdata表示真实数据分布,pz表示生成数据分布,超参数λ、β用于平衡各项损失。
28、所述s4中利用人工神经网络进行分类预测的方法为:
29、在训练过程中,使用反向传播更新网络中的权重捕捉数据的非线性,以最小化代表瞬时误差的能量函数;若表示ann输出层中第k个神经元的目标输出,则特定训练场景的第k个神经元的预测误差;若输出层中存在一组神经元,计算预测误差;计算考虑所有训练场景的总误差;
30、bp是通过最小化预测中的均方差来完成的,对网络中分支的权重进行更新,ann权重会调整迭代,直到迭代次数达到定义的最大值或误差小于定义的容差水平。
31、所述特定训练场景的第k个神经元的预测误差ek的计算公式为:
32、
33、若输出层中存在一组神经元,计算预测误差的方法为:
34、
35、计算考虑所有训练场景的总误差etol的方法为:
36、
37、其中,tok是第k个神经元的目标输出,ook是第k个神经元的s实际输出,tokl为第l个训练样本的第k个神经元的目标输出,ookl为第l个训练样本的第k个神经元的实际输出。
38、所述通过最小化预测中的均方差来完成bp的方法为:
39、
40、对网络中分支的权重进行更新的方法为:
41、
42、其中,η是比例常数,wjk表示连接神经元j和k之间的权重。
43、所述s5中使用shap进行模型解释的方法为:
44、s5.1、对于输入样本的特征空间,通过对特征的不同组合进行采样来创建所有可能的子集;
45、s5.2、对于每个特征子集,计算模型对于包含该子集的样本的预测输出;
46、s5.3、计算每个特征子集对模型输出的边际贡献,即模型输出的差异,针对所有可能的子集进行计算;
47、s5.4、确定每个特征的贡献。
48、所述s5.4中确定每个特征贡献的方法为:
49、
50、其中,φi是特征i的shap值;n是特征集合;v(s)是模型对特征子集s的预测输出;s是特征子集s的大小。
51、本发明与现有技术相比,具有的有益效果是:
52、本发明结合sa-smote和ae-gan的双阶段生成增强网络模型(agsmf),每个阶段以及每个模型组件都旨在最大限度地发挥其优势。且本发明应用agsmf模型的整体性能表现优于symprod、smotewb、ans、amsco等目前流行的数据增强方法,即所提模型能够有效解决碰撞严重程度数据不平衡的问题,进一步证明了该模型在提升道路碰撞事故预测性能方面的卓越潜力。本发明通过shap方法对模型结果进行解释,不仅揭示了交通事故严重程度预测中关键因素的重要性,还为制定有效的交通事故预防策略提供了深入洞察和科学依据。
本文地址:https://www.jishuxx.com/zhuanli/20240808/271001.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。