考虑遮挡不确定性的自动驾驶决策方法及系统
- 国知局
- 2024-08-02 17:04:41
本发明属于车辆驾驶决策,尤其涉及一种考虑遮挡不确定性的自动驾驶决策方法及系统。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
2、在城市环境中,遮挡导致的感知受限所带来的环境不确定性是自动驾驶决策规划的一个重大障碍,作为典型的“长尾问题”制约自动驾驶发展。人类驾驶员可以通过预测被遮挡区域可能出现的交通参与者的运动评估碰撞风险,从而做出合理的决策,如提前减速或试探性前进等。然而,很多自动驾驶决策规划算法仅根据已知的环境车辆状态调整自身行为,忽视障碍物的遮挡造成的碰撞风险,做出危险的决策和规划,比如保持原速或加速行驶,从而不可避免引发交通事故。
3、尽管可利用车辆对车辆或其他基础设施(vehicle-to-everything,v2x)通信,提供遮挡阴影区域的交通参与者信息,但是目前短时间难以建设相应基建设施;在数据计算方面,随着环境复杂性的增加,基于pomdp求解器的方法通常需要大量的计算工作,影响模型的实时性能和效率;分布式强化学习的方法在处理阻塞区域带来的不确定性方面具有有效性,但没有考虑周围信息理解对决策模型的影响。
技术实现思路
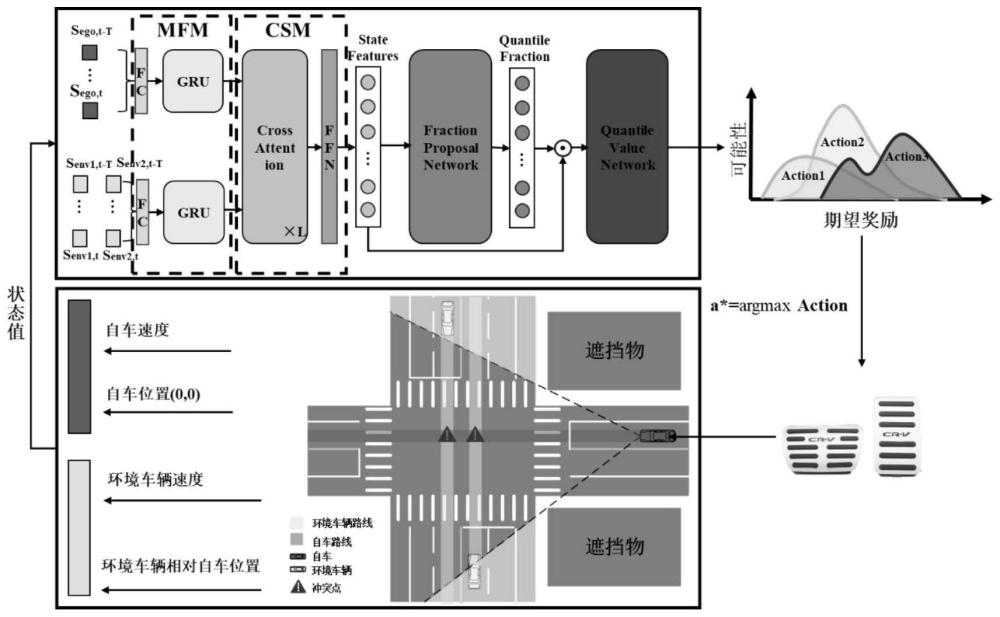
1、为克服上述现有技术的不足,本发明提供了一种考虑遮挡不确定性的自动驾驶决策方法及系统,所述方案基于对遮挡场景的考虑,通过在遮挡边界设置虚拟车辆,提出并采用多帧融合模块进行特征提取,结合基于交叉注意力机制的关键车辆选择模块获得全局融合特征,有效加深了自动驾驶决策中对环境的理解,进而保证了自动驾驶车辆在遮挡造成的不确定性下的通行安全性和效率。
2、根据本发明实施例的第一个方面,提供了一种考虑遮挡不确定性的自动驾驶决策方法,包括:
3、获取自车状态信息和环境车辆状态信息;其中,在自车对应的环境车辆中引入虚拟车辆;
4、基于获得的自车和环境车辆的状态信息,采用多帧融合模块获得包含时间信息的自车的状态嵌入和环境车辆的状态嵌入;以及基于自车的状态嵌入和环境车辆的状态嵌入,采用基于交叉注意力机制的关键车辆选择模块,获得全局状态特征;
5、基于获得的全局状态特征,采用预先训练的基于值分布的强化学习模型,获得车辆输出动作,实现自车车辆的自动驾驶决策。
6、进一步的,所述虚拟车辆设置于自车的遮挡边界处,其中,所述遮挡边界为自车位置与遮挡物边界点所连射线,与环境车辆所在车道线中线相交所构成的边界。
7、进一步的,所述自车状态信息由连续若干时刻的自车速度以及自车坐标系下自车位置进行表示;所述环境车辆状态信息由若干环境车辆对应的连续若干时刻的环境车辆相对自车位置以及环境车辆速度进行表示。
8、进一步的,所述采用多帧融合模块获得包含时间信息的自车的状态嵌入和环境车辆的状态嵌入,其中,所述多帧融合模块具体为:分别以自车和环境车辆的状态信息作为全连接网络的输入,并以全连接网络的输出作为gru层的输入,获得自车和环境车辆的状态嵌入。
9、进一步的,所述采用基于交叉注意力机制的关键车辆选择模块,获得全局状态特征,其中,所述关键车辆选择模块具体为:以自车的状态嵌入、环境车辆的状态嵌入以及环境车辆的掩码表示作为第一交叉注意力层的输入,并以第一交叉注意力层的输出作为第二交叉注意力层的输入,获得全局状态特征。
10、进一步的,所述基于值分布的强化学习模型,具体采用fqf模型,所述模型包括分位数提议网络和分位数值网络,基于获得的全局状态特征,利用分位数提议网络,获得每个时间步对应的可调分位数分数;基于获得的可调分位数分数,利用分位数值网络,拟合得到对应的可调分位数值。
11、进一步的,所述基于值分布的强化学习模型的训练,采用如下奖励函数:
12、rt=rs+rcomf+reff+rtime
13、其中,rs为安全性奖励,rcomf为舒适性奖励,reff为效率奖励,rtime为时间奖励。
14、根据本发明实施例的第二个方面,提供了一种考虑遮挡不确定性的自动驾驶决策系统,包括:
15、数据获取单元,其用于获取自车状态信息和环境车辆状态信息;其中,在自车对应的环境车辆中引入虚拟车辆;
16、特征提取单元,其用于基于获得的自车和环境车辆的状态信息,采用多帧融合模块获得包含时间信息的自车的状态嵌入和环境车辆的状态嵌入;以及基于自车的状态嵌入和环境车辆的状态嵌入,采用基于交叉注意力机制的关键车辆选择模块,获得全局状态特征;
17、决策单元,其用于基于获得的全局状态特征,采用预先训练的基于值分布的强化学习模型,获得车辆输出动作,实现自车车辆的自动驾驶决策。
18、根据本发明实施例的第三个方面,提供了一种电子设备,包括存储器、处理器及存储在存储器上运行的计算机程序,所述处理器执行所述程序时实现所述的一种考虑遮挡不确定性的自动驾驶决策方法。
19、根据本发明实施例的第四个方面,提供了一种非暂态计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现所述的一种考虑遮挡不确定性的自动驾驶决策方法。
20、以上一个或多个技术方案存在以下有益效果:
21、本发明提供一种考虑遮挡不确定性的自动驾驶决策方法及系统,所述方案基于对遮挡场景的考虑,通过在遮挡边界设置虚拟车辆,采用多帧融合模块进行特征提取,结合基于交叉注意力机制的关键车辆选择模块获得全局融合特征,有效加深了自动驾驶决策中对环境的理解,进而保证了自动驾驶车辆在遮挡造成的不确定性下的通行安全性和效率。
22、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:1.一种考虑遮挡不确定性的自动驾驶决策方法,其特征在于,包括:
2.如权利要求1所述的一种考虑遮挡不确定性的自动驾驶决策方法,其特征在于,所述虚拟车辆设置于自车的遮挡边界处,其中,所述遮挡边界为自车位置与遮挡物边界点所连射线,与环境车辆所在车道线中线相交所构成的边界。
3.如权利要求1所述的一种考虑遮挡不确定性的自动驾驶决策方法,其特征在于,所述自车状态信息由连续若干时刻的自车速度以及自车坐标系下自车位置进行表示;所述环境车辆状态信息由若干环境车辆对应的连续若干时刻的环境车辆相对自车位置以及环境车辆速度进行表示。
4.如权利要求1所述的一种考虑遮挡不确定性的自动驾驶决策方法,其特征在于,所述采用多帧融合模块获得包含时间信息的自车的状态嵌入和环境车辆的状态嵌入,其中,所述多帧融合模块具体为:分别以自车和环境车辆的状态信息作为全连接网络的输入,并以全连接网络的输出作为gru层的输入,获得自车和环境车辆的状态嵌入。
5.如权利要求1所述的一种考虑遮挡不确定性的自动驾驶决策方法,其特征在于,所述采用基于交叉注意力机制的关键车辆选择模块,获得全局状态特征,其中,所述关键车辆选择模块具体为:以自车的状态嵌入、环境车辆的状态嵌入以及环境车辆的掩码表示作为第一交叉注意力层的输入,并以第一交叉注意力层的输出作为第二交叉注意力层的输入,获得全局状态特征。
6.如权利要求1所述的一种考虑遮挡不确定性的自动驾驶决策方法,其特征在于,所述基于值分布的强化学习模型,具体采用fqf模型,所述模型包括分位数提议网络和分位数值网络,基于获得的全局状态特征,利用分位数提议网络,获得每个时间步对应的可调分位数分数;基于获得的可调分位数分数,利用分位数值网络,拟合得到对应的可调分位数值。
7.如权利要求1所述的一种考虑遮挡不确定性的自动驾驶决策方法,其特征在于,所述基于值分布的强化学习模型的训练,采用如下奖励函数:
8.一种考虑遮挡不确定性的自动驾驶决策系统,其特征在于,包括:
9.一种电子设备,包括存储器、处理器及存储在存储器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现如权利要求1-7任一项所述的一种考虑遮挡不确定性的自动驾驶决策方法。
10.一种非暂态计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现如权利要求1-7任一项所述的一种考虑遮挡不确定性的自动驾驶决策方法。
技术总结本发明提供了一种考虑遮挡不确定性的自动驾驶决策方法及系统,包括:获取自车状态信息和环境车辆状态信息;其中,在自车对应的环境车辆中引入虚拟车辆;基于获得的自车和环境车辆的状态信息,采用多帧融合模块获得包含时间信息的自车的状态嵌入和环境车辆的状态嵌入;以及基于自车的状态嵌入和环境车辆的状态嵌入,采用基于交叉注意力机制的关键车辆选择模块,获得全局状态特征;基于获得的全局状态特征,采用预先训练的基于值分布的强化学习模型,获得车辆输出动作,实现自车车辆的自动驾驶决策。技术研发人员:陈雪梅,杨熠璇,田奕宏,董宪元,吴甲,朱宇臻,刘跃泽,曲睿,布占昊,姚诚达,高丛政受保护的技术使用者:北京理工大学前沿技术研究院技术研发日:技术公布日:2024/7/15本文地址:https://www.jishuxx.com/zhuanli/20240718/253930.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表