一种面向分布外目标数据环境的数据收集方法及装置
- 国知局
- 2024-08-19 14:27:52
本发明属于数据收集和分布外泛化领域,特别提出一种面向分布外目标数据环境的数据收集方法及装置。
背景技术:
1、近年来,机器学习领域经历了前所未有的增长。传统的机器学习范式通常假设训练数据和测试数据来自相同的分布。然而,这一假设与现实世界中的数据显著异质性形成了鲜明的对比,导致了不同领域之间分布的变化。例如,医疗场景里,由于地区不同,不同医疗中心面对的人群分布存在明显差异。如果利用某个医疗中心收集的病例数据(比如:肺炎诊疗数据)训练预测该疾病(比如:肺炎)是否发生的模型,当其他医疗中心应用该模型进行预测时,往往会出现很大的预测误差的问题,导致模型诊疗预测结果不可靠。因此,在解决在实际应用中部署机器学习模型的挑战时,越来越多的关注集中在提高模型在面对分布偏移时的性能上。例如,疾病诊疗的场景里,研究提高模型跨不同医疗中心(即不同的训练数据环境和目标环境)的泛化能力,保证模型面对不同人群分布的稳定水平,可以有效提高预测疾病预测的可靠性,辅助医生提高诊疗水平。
2、目前,为了促进模型在目标环境的泛化,领域适应方法提出在数据分布、数据表征和模型参数上对源环境和目标环境进行对齐。在只有来自测试域的无标签数据可用的情况下,无监督领域适应的解决方案包括通过样本重新加权减轻分布差异,通过自监督学习生成伪标签等等。然而,这些方法假设训练样本是预先确定的,因此它们的模型性能密切依赖于训练数据质量。
3、最近,以数据为中心的机器学习已经引起了越来越多的关注。通过提高数据准备过程,它们成功地通过收集更有效的训练数据样本,突破了原来模型性能的瓶颈。为了应对目标环境的分布偏移,部分方法提出选择和标记来自未标记测试数据的最代表性样本,从而有效地获取目标环境信息。然而,在许多现实世界应用中,样本标签不能由第三方提供。因此,如何利用有限数据成本从数据源收集优质的训练数据,保证数据对目标环境的代表性,是很有挑战,但也非常重要的问题。
4、尤其,在医疗数据处理领域,由于数据稀缺性、隐私性等问题,病例数据获取难度大,单个医疗中心针对某一疾病的病例数据量往往较少;同时,多个医疗中心之间群体分布差异明显,导致来自单个医疗中心的训练病例数据缺乏对全体测试病例数据的代表性。为了建立预测模型应用到目标环境,传统方法从可以使用的数据环境中均匀收集训练数据样本,训练预测模型。例如,利用肺炎病例数据建立肺炎预测模型时,传统方法从可采样的医疗中心均匀收集病例数据。但这种方法忽略了不同医疗中心中的病例样本对目标医疗中心的代表性,因此收集的训练病例样本也不能很好地表示目标医疗中心分布,导致学习的肺炎预测模型应用到目标医疗中心表现水平较差,使得疾病判定出现错误。因此,如何提高训练数据样本的收集质量,更合理地从数据环境中收集尽可能代表目标环境的训练数据样本,是改善模型向目标环境泛化的关键问题。
技术实现思路
1、本发明的目的是为克服已有技术的不足之处,提出一种面向分布外目标数据环境的数据收集方法及装置。本发明针对在有限采样预算下从各种数据源获取训练样本的实际需求,可以快速有效地提高训练数据质量,提高模型面向目标环境的表现水平;尤其是在疾病预测领域,可以改善从不同数据环境(即不同医疗中心)收集训练病例数据的质量,提高收集到的病例数据对目标医疗中心的代表性,减小训练病例数据和测试病例数据的差别,从而保证建立的疾病预测模型在目标医疗中心进行有效预测,显著改善该疾病预测模型对疾病诊断的正确率,从而有助于智慧医疗模型的安全落地。
2、本发明第一方面实施例提出一种面向分布外目标数据环境的数据收集方法,包括:
3、选取多个训练数据环境,其中每个所述训练数据环境提供类型一致的训练数据样本,每个所述训练数据样本包括该样本的数据特征和对应的数据类别;
4、选取待利用所述训练数据样本进行模型训练的目标环境,获取来自所述目标环境的无标签测试样本,所述无标签测试样本的数据特征与所述训练数据样本的数据特征类型一致;
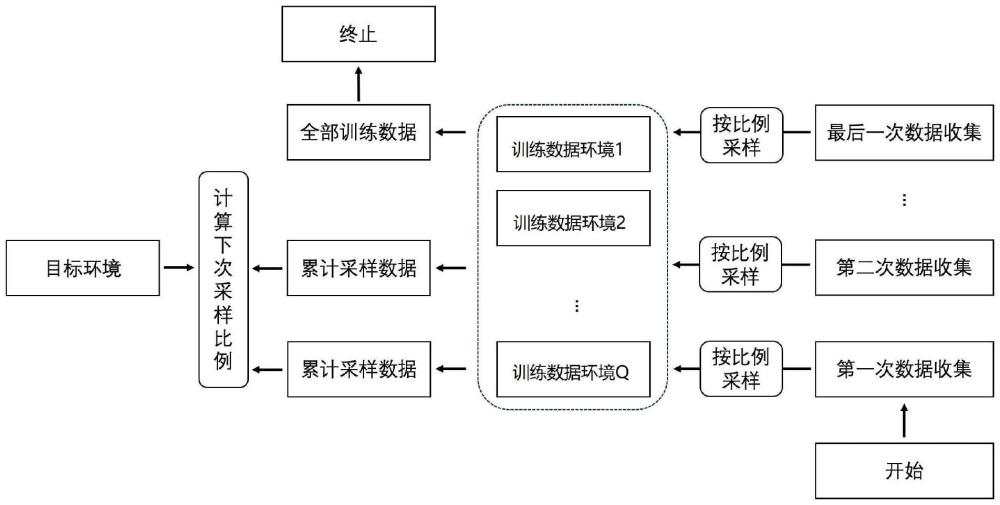
5、按照设定的所述训练数据样本收集总数,对所述训练数据环境进行多个轮次的训练数据样本收集;其中,每个轮次收集的所述训练数据样本的数目相等;在第一次收集时,从每个所述训练数据环境收集的所述训练数据样本的数目相等;从第二次收集开始,基于之前所有轮次收集的所述训练数据样本,结合所述无标签测试样本的数据特征,优化得到从每个所述训练数据环境收集所述训练数据样本的采样比例,然后基于所述采样比例进行当前轮次的所述训练数据样本收集,直至所有训练数据样本收集完毕。
6、在本发明的一个具体实施例中,还包括:
7、所述训练数据环境为可获取任一种疾病病例数据的医疗中心,将所述训练数据环境中的所述病例数据作为所述训练数据样本,所述训练数据样本的数据特征为反映所述疾病特征的参数,所述训练数据样本对应的数据类别为反映是否具有所述疾病的标签;
8、所述目标环境为待训练所述疾病预测模型的医疗中心,获取所述目标环境中无所述疾病诊断结果的病例数据作为无标签测试样本,将所述无标签测试样本的反映所述疾病特征的参数作为对应的数据特征。
9、在本发明的一个具体实施例中,所述优化得到从每个所述训练数据环境收集所述训练数据样本的采样比例,包括:
10、1)令每个训练数据环境的训练数据分布由表示,其中,(x,y)表示一个训练数据样本,x表示训练数据样本的数据特征,y表示训练数据样本对应的数据类别;表示第j个训练数据环境的样本(x,y)的联合分布,j=1,2,…,q,q为训练数据环境的总数;
11、将无标签测试样本记为xte~pte(x,y),其中,xte是无标签测试样本的数据特征,pte(x,y)表示无标签测试样本的联合分布;
12、2)在进行第(c+1)次数据收集时,1≤c≤k-1,利用前c次已经收集的训练数据样本集合j=1,2,…,q,分别计算从各训练数据环境收集的训练数据样本的数据特征的均值记为其中,表示从第j个训练数据环境第i次收集的训练数据样本,表示从第j个训练数据环境第i次收集的训练数据样本的数据特征,yji表示从第j个训练数据环境第i次收集的训练数据样本对应的数据类别,表示前c次从第j个训练数据环境收集的训练数据样本的数据特征的平均值;
13、3)利用步骤2)的结果,构建优化问题如下:
14、
15、其中,wj表示从第j个训练数据环境收集训练数据样本的采样比例;为目标环境的数据特征均值,即是通过对来自目标环境的无标签测试样本的数据特征xte计算均值得到;
16、求解所述优化问题,得到优化后的各训练数据环境对应的采样比例wj',j=1,2,...,q。
17、在本发明的一个具体实施例中,所述求解所述优化问题采用梯度下降方法。
18、本发明第二方面实施例提出一种面向分布外目标数据环境的数据收集装置,包括:
19、训练数据环境选取模块,用于选取多个训练数据环境,其中每个所述训练数据环境提供类型一致的训练数据样本,每个所述训练数据样本包括该样本的数据特征和对应的数据类别;
20、目标环境选取模块模块,用于选取待利用所述训练数据样本进行模型训练的目标环境,获取来自所述目标环境的无标签测试样本,所述无标签测试样本的数据特征与所述训练数据样本的数据特征类型一致;
21、数据收集模块,用于按照设定的所述训练数据样本收集总数,对所述训练数据环境进行多个轮次的训练数据样本收集;其中,每个轮次收集的所述训练数据样本的数目相等;在第一次收集时,从每个所述训练数据环境收集的所述训练数据样本的数目相等;从第二次收集开始,基于之前所有轮次收集的所述训练数据样本,结合所述无标签测试样本的数据特征,优化得到从每个所述训练数据环境收集所述训练数据样本的采样比例,然后基于所述采样比例进行当前轮次的所述训练数据样本收集,直至所有训练数据样本收集完毕。
22、在本发明的一个具体实施例中,还包括:
23、所述训练数据环境为可获取任一种疾病病例数据的医疗中心,将所述训练数据环境中的所述病例数据作为所述训练数据样本,所述训练数据样本的数据特征为反映所述疾病特征的参数,所述训练数据样本对应的数据类别为反映是否具有所述疾病的标签;
24、所述目标环境为待训练所述疾病预测模型的医疗中心,获取所述目标环境中无所述疾病诊断结果的病例数据作为无标签测试样本,将所述无标签测试样本的反映所述疾病特征的参数作为对应的数据特征。
25、在本发明的一个具体实施例中,所述优化得到从每个所述训练数据环境收集所述训练数据样本的采样比例,包括:
26、1)令每个训练数据环境的训练数据分布由表示,其中,(x,y)表示一个训练数据样本,x表示训练数据样本的数据特征,y表示训练数据样本对应的数据类别;表示第j个训练数据环境的样本(x,y)的联合分布,j=1,2,…,q,q为训练数据环境的总数;
27、将无标签测试样本记为xte~pte(x,y),其中,xte是无标签测试样本的数据特征,pte(x,y)表示无标签测试样本的联合分布;
28、2)在进行第(c+1)次数据收集时,1≤c≤k-1,利用前c次已经收集的训练数据样本集合j=1,2,…,q,分别计算从各训练数据环境收集的训练数据样本的数据特征的均值记为其中,表示从第j个训练数据环境第i次收集的训练数据样本,表示从第j个训练数据环境第i次收集的训练数据样本的数据特征,表示从第j个训练数据环境第i次收集的训练数据样本对应的数据类别,表示前c次从第j个训练数据环境收集的训练数据样本的数据特征的平均值;
29、3)利用步骤2)的结果,构建优化问题如下:
30、
31、其中,wj表示从第j个训练数据环境收集训练数据样本的采样比例;为目标环境的数据特征均值,即是通过对来自目标环境的无标签测试样本的数据特征xte计算均值得到;
32、求解所述优化问题,得到优化后的各训练数据环境对应的采样比例wj',j=1,2,...,q。
33、在本发明的一个具体实施例中,所述求解所述优化问题采用梯度下降方法。
34、本发明第三方面实施例提出一种电子设备,包括:
35、至少一个处理器;以及,与所述至少一个处理器通信连接的存储器;
36、其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被设置为用于执行上述一种面向分布外目标数据环境的数据收集方法。
37、本发明第四方面实施例提出一种计算机可读存储介质,所述计算机可读存储介质存储计算机指令,所述计算机指令用于使所述计算机执行上述一种面向分布外目标数据环境的数据收集方法。
38、本发明的特点及有益效果:
39、1)本发明学习训练数据环境的采样比例,收集训练数据样本,使得训练数据分布尽可能接近目标环境分布,从而提高模型面向目标环境的表现水平。
40、2)本发明从零开始,从多个训练数据环境中同时收集训练数据,并更新各训练数据环境的采样比例,可以保证即使在收集成本有限的情况下,可以最大程度地保证收集到的训练数据具有良好的目标环境代表性。
41、3)在医疗数据处理领域,本发明可从不同训练数据环境(即不同医疗中心)有效地收集训练病例数据,包括但不限于医学影像数据、临床特征数据、基因/蛋白/代谢等多组学数据,使基于收集的训练数据训练的预测模型更好地泛化到目标环境(即目标医疗中心),显著改善预测模型在目标环境下对疾病诊断的正确率,保证智慧医疗模型的安全落地。
本文地址:https://www.jishuxx.com/zhuanli/20240819/275288.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。