一种基于集成学习框架的疾病预测方法及系统
- 国知局
- 2024-08-22 14:48:22
本发明涉及机器学习领域,尤其涉及一种基于集成学习框架的疾病预测方法及系统。
背景技术:
1、糖尿病是一种常见且严重的慢性疾病,对人们的健康造成了很大的威胁,由于慢性疾病发病过程的特殊性,如何预防是慢性疾病管理中最有效的措施,疾病预测对提高慢性疾病管理效率有着重要的意义。早期的糖尿病预测可以帮助医生和患者采取及早的干预措施,从而减少并发症的发生,提高患者的生活质量,降低致残率,延长寿命;然而,由于体检数据过于单一,很难将疾病和体检数据进行关联,因此在对体检数据的利用方面一直处于较低的水平,而且由于数据敏感性,以及复杂的环境因素,对糖尿病进行预测仍然是一个具有挑战性的问题。
2、机器学习和医疗健康相结合是近年来的热点,然而现有研究对糖尿病的预测大多还是采用单一模型,单一模型的缺陷比较明显,在面对复杂的环境因素时,其鲁棒性不够强且模型的性能有限,难以实现准确的预测。
技术实现思路
1、本发明的目的在于克服现有技术的缺点,提供了一种基于集成学习框架的疾病预测方法及系统,解决了现有技术存在的不足。
2、本发明的目的通过以下技术方案来实现:一种基于集成学习框架的疾病预测方法,所述预测方法包括:
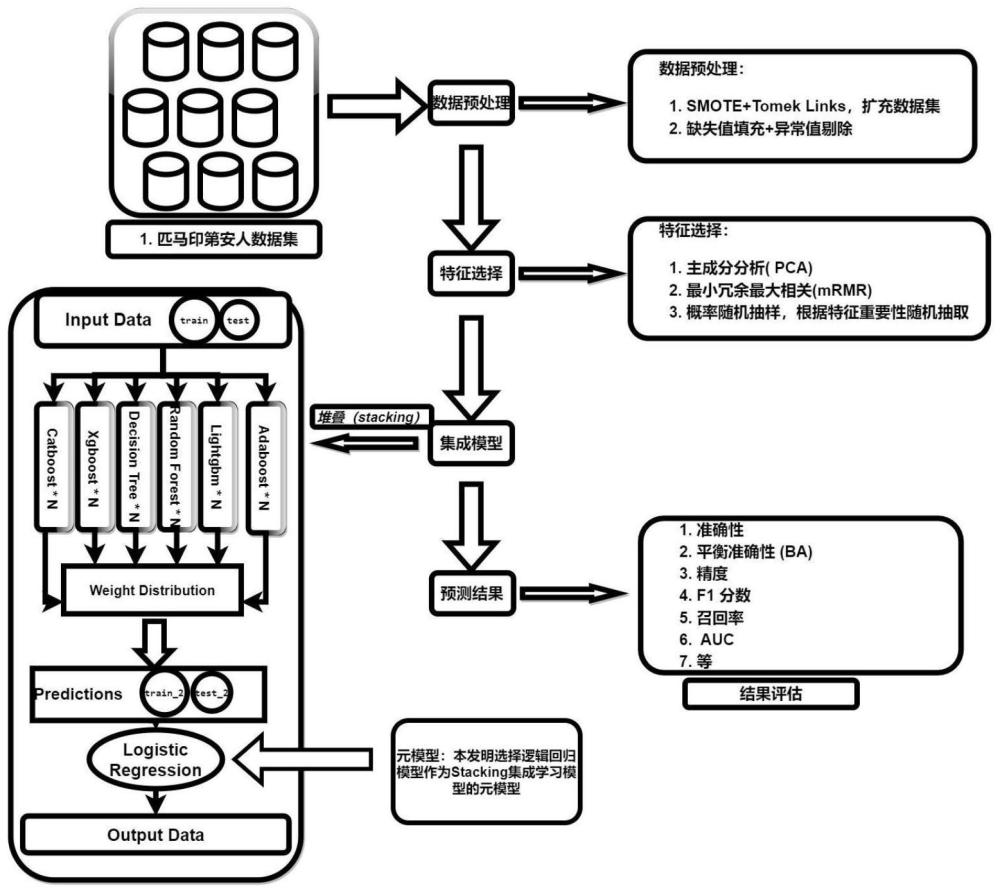
3、数据预处理步骤:采用smote+tomek links方法对糖尿病数据集进行扩充,并将数据集按比例划分为训练集和测试集;
4、特征选择步骤:选择糖尿病数据集中所有特征,对基模型进行预训练,确定基模型的初始参数,并计算各个特征的重要性概率,得到总和为1的特征重要性概率表g;
5、概率随机采样步骤:根据特征重要性概率表,采用随机有放回的采样方式确定训练数据集中的数据特征,每次抽取80%的数据特征作为训练数据,重复多次得到多个数据子集,用于多个基模型的训练,得到最终的基模型;
6、基模型数据加权步骤:选择多种类别的模型作为基模型,并把每种类别的基模型数量扩充到m个,将每次随机有放回采样选择的数据特征用于拟合预训练好的基模型,并利用产生的验证集对模型性能进行评估,并保存相应类别模型的性能评估指标数据;
7、元模型数据加权融合步骤:根据集成学习模型预测数据的公式得到预测值,k为基模型的类别数量,m为每个类别基模型的数量,表示第k类别基模型中的第m个基模型权重,表示第k类别基模型中的第m个基模型所选取的特征输入,表示第k类别基模型中的第m个基模型,表示第k类别基模型中的第m个基模型预测,表示元模型预测,表示预测值。
8、所述数据预处理步骤具体包括:
9、首先对原始数据集内的异常数据进行剔除,通过均值填充的方式对缺失数据项进行填充;
10、以每个样本点的z个最邻近样本点为依据,随机选择n个邻近点进行差值乘以一个[0,1]范围的阈值,从而合成得到新样本点实现数据的扩充。
11、所述特征选择步骤中选择的数据特征以及重要性从大到小的排序依次包括:餐后血清胰岛素含量、口服葡萄糖耐量试验中2小时后的血浆葡萄糖浓度、年龄、三头肌皮褶厚度、怀孕次数、体重指数、糖尿病家系作用和舒张压。
12、所述概率随机采样步骤具体包括:
13、基模型预训练:将数据集以7:3的比例划分为训练集和测试集,将训练集平均划分为5等份,依次选择其中1份作为验证子集,其余4份作为训练子集用于模型训练,采用网格搜索算法确定基模型的初始最优参数设定,选择数据集内的所有数据特征用于训练,以实现多个类别基模型的初始参数设定。
14、在集成学习模型中采用概率随机采样选择数据集内80%的数据特征进行训练,即每次随机抽取80%的数据特征,重复m次,可以组成m个独立数据子集,用于m个基模型训练,重复上述过程,直至完成多个基模型训练,得到最终的基模型。
15、一种基于集成学习框架的疾病预测系统,它包括数据预处理模块、特征选择模块、概率随机采样模块、基模型数据加权模块和元模型数据加权融合模块;
16、所述数据预处理模块:采用smote+tomeklinks方法对糖尿病数据集进行扩充,并将数据集按比例划分为训练集和测试集;
17、所述特征选择模块:选择糖尿病数据集中所有特征,对基模型进行预训练,确定基模型的初始参数,并计算各个特征的重要性概率,得到总和为1的特征重要性概率表g;
18、所述概率随机采样模块:根据特征重要性概率表,采用随机有放回的采样方式确定训练数据集中的数据特征,每次抽取80%的数据特征作为训练数据,重复多次得到多个数据子集,用于多个基模型的训练,得到最终的基模型;
19、所述基模型数据加权模块:用于选择多种类别的模型作为基模型,并把每种类别的基模型扩充到m个,在每次随机采样时通过一个初始化的模型进行拟合,并利用产生的验证集对模型性能进行评估,并保存相应类别模型的指标数据;
20、所述元模型数据加权融合模块:用于根据集成学习模型预测数据的公式得到预测值,k为基模型的类别数量,m为每个类别基模型的数量,表示第k类别基模型中的第m个基模型权重,表示第k类别基模型中的第m个基模型所选取的特征输入,表示第k类别基模型中的第m个基模型,表示第k类别基模型中的第m个基模型预测,表示元模型预测,表示预测值。
21、所述数据预处理模块具体包括:
22、首先对原始数据集内的异常数据进行剔除,通过均值填充的方式对缺失数据项进行填充;
23、以每个样本点的z个最邻近样本点为依据,随机选择n个邻近点进行差值乘以一个[0,1]范围的阈值,从而合成得到新样本点实现数据的扩充。
24、所述概率随机采样模块具体包括:
25、基模型预训练:将数据集以7:3的比例划分为训练集和测试集,将训练集平均划分为5等份,依次选择其中1份作为验证子集,其余4份作为训练子集用于模型训练,采用网格搜索算法确定基模型的初始最优参数设定,选择数据集内的所有数据特征用于训练,以实现多个类别基模型的初始参数设定。
26、在集成学习模型中采用概率随机采样选择数据集内80%的数据特征进行训练,即每次随机抽取80%的数据特征,重复m次,可以组成m个独立数据子集,用于m个基模型训练,重复上述过程,直至完成多个基模型训练,得到最终的基模型。
27、本发明具有以下优点:一种基于集成学习框架的疾病预测方法及系统,通过smote+tomek links方法在扩充数据集的同时也可以很好解决样本的不平衡问题;选择了随机森林、决策树、adaboost、xgboost、lightgbm、catboost作为基础模型,以逻辑回归模型作为元模型,相对于直接平均加权,通过衡量基模型各自的性能表现来有针对性的偏向,将加权之后的数据整合得到元模型的训练数据集即逻辑回归的训练数据集,可以很大的提升集成学习模型的性能。
技术特征:1.一种基于集成学习框架的疾病预测方法,其特征在于:所述预测方法包括:
2.根据权利要求1所述的一种基于集成学习框架的疾病预测方法,其特征在于:所述数据预处理步骤具体包括:
3.根据权利要求1所述的一种基于集成学习框架的疾病预测方法,其特征在于:所述特征选择步骤中选择的数据特征以及重要性从大到小的排序依次包括:餐后血清胰岛素含量、口服葡萄糖耐量试验中2小时后的血浆葡萄糖浓度、年龄、三头肌皮褶厚度、怀孕次数、体重指数、糖尿病家系作用和舒张压。
4.根据权利要求1所述的一种基于集成学习框架的疾病预测方法,其特征在于:所述概率随机采样步骤具体包括:
5.一种基于集成学习框架的疾病预测系统,其特征在于:它包括数据预处理模块、特征选择模块、概率随机采样模块、基模型数据加权模块和元模型数据加权融合模块;
6.根据权利要求5所述的一种基于集成学习框架的疾病预测系统,其特征在于:所述数据预处理模块具体包括:
7.根据权利要求5所述的一种基于集成学习框架的疾病预测系统,其特征在于:所述概率随机采样模块具体包括:
技术总结本发明涉及一种基于集成学习框架的疾病预测方法及系统,属于机器学习领域,包括:对糖尿病数据集进行预处理;选择糖尿病数据集中所有特征,对基模型进行预训练,确定基模型的初始参数,并计算各个特征的重要性概率,得到总和为1的特征重要性概率表G;根据特征重要性概率表,确定训练数据集中的数据特征,用于多个基模型的训练,得到最终的基模型;选择多种类别的模型作为基模型并进行训练和评估,保存模型的性能评估指标数据;根据集成学习模型得到预测值。本发明选择多种模型作为基础模型,通过衡量基模型各自的性能来有针对性的偏向,将加权之后的数据整合形成元模型即逻辑回归的训练集,可以很大的提升集成学习模型的性能。技术研发人员:谢东海,吴磊,刘明,陈鹏,单文煜受保护的技术使用者:电子科技大学长三角研究院(衢州)技术研发日:技术公布日:2024/8/20本文地址:https://www.jishuxx.com/zhuanli/20240822/279951.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。