一种基于时空特征融合的多相机BEV目标检测方法
- 国知局
- 2024-08-22 14:50:05
本发明涉及目标检测,尤其涉及一种基于时空特征融合的多相机bev目标检测方法。
背景技术:
1、目标检测技术作为自动驾驶的核心议题,旨在帮助车辆理解前方障碍物“是什么”、“在哪里”,是自动驾驶、机器人和交通管理等各种应用中的关键。bev(鸟瞰视图)是一种自然而直接的候选视图,可用作统一的表示,其能够提供自上而下的全视角,可清楚地呈现车辆周围物体的位置和规模。bev更能表征真实世界,特别是包含丰富语义信息、精确位置信息和绝对尺寸信息的交通场景,可以更好地识别有遮挡或交叉交通的车辆,以这种形式表示物体或道路元素将有利于后续规划、控制模块的开发和部署。对此,现有技术提出了如中国专利cn116385845a公开的一种基于bev的多摄像机3d目标检测的深度学习算法,输入六张图像进行特征提取,用resnet50的网络架构进行特征融合,将得到的图像特征转换成bev图像,对bev图像进行特征提取和特征融合,得到最终的高精度3d目标检测结果。但其未利用时序信息,不能融合时空特征,无法识别遮挡目标和推断物体运动状态,使得目标检测性能无法进一步提高。
技术实现思路
1、有鉴于此,本发明的目的在于提出一种基于时空特征融合的多相机bev目标检测方法,以解决夜晚缺乏光照的复杂交通背景下的三维目标检测问题。
2、基于上述目的,本发明提供了一种基于时空特征融合的多相机bev目标检测方法,包括以下步骤:
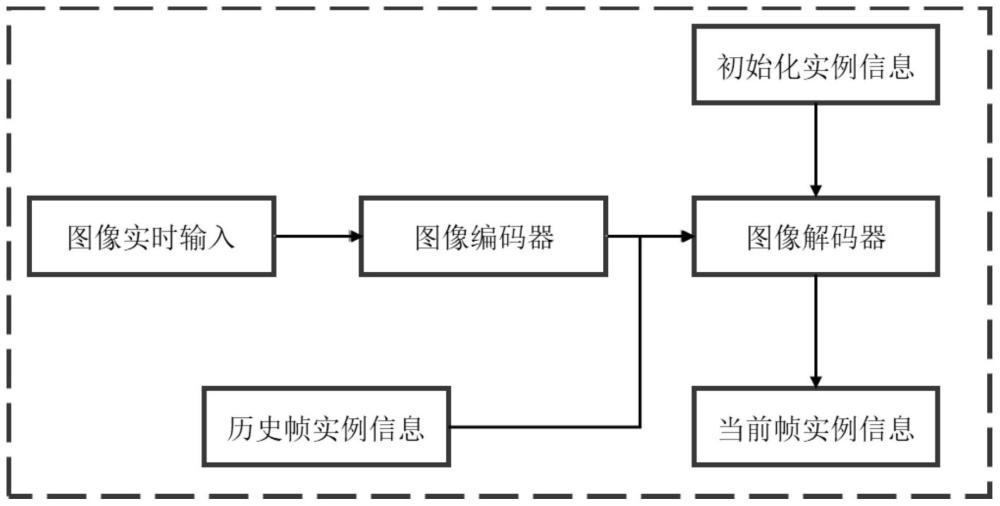
3、s1:获取多视图图像数据;
4、s2:将多视图图像数据输入到图像编码器中,得到多相机bev特征图;
5、s3:初始化一组实例信息,将bev特征图和历史帧实例信息馈送到解码器中输出当前帧实例信息和目标检测框。
6、优选的,步骤s2具体包括:
7、将多视图图像数据输入到图像编码器中,每个图像通过共享图像骨干神经网络提取特征,获取透视图特征映射,并使用mlp视图转换模块将图像特征从透视图转换到相机坐标系,再转换到鸟瞰图,得到多相机bev特征图;
8、优选的,步骤s3具体包括:
9、初始化一组实例信息,将多相机bev特征图和历史帧实例信息馈送到解码器中输出当前帧实例信息和目标检测框,其中解码器包括一个单帧层和六个多帧层,利用时间实例功能的循环传播方式,首先使用单帧层对实例进行优化和评分,将选择的置信度最高的实例和历史帧实例信息作为多帧层的输入,多帧层的输出作为当前帧的检测结果。
10、优选的,所述图像编码器包括透视图图像编码器和视图转换模块,步骤s2具体包括:
11、s21、将来自n个相机的透视视图输入透视图图像编码器,对于每一个图像ii,利用一个通用的图像处理骨干网络φl提取其特征,生成对应的透视特征图该特征图是一个存在于空间中的张量,其中hpv代表其高度,wpv代表宽度,k表示特征维度;
12、s22、将图像特征从透视图转换到相机坐标系,再转换到鸟瞰图,得到多相机bev特征图,用多层感知器对透视图和相机坐标系之间任意两个像素的关系进行建模,得到相机坐标系的特征图过程如下:
13、
14、其中,表示多层感知器对相机坐标系中的位置(h,w)处的特征向量与透视图特征图上的每个像素之间的关系进行建模,hc和wc表示为的自上而下的空间维度;
15、利用相机外部的几何投影对相机坐标系特征进行变换获得bev特征其中hbev和wbev是鸟瞰图中的高度和宽度,将n个相机bev特征求平均值得到最终的bev特征
16、优选的,实例信息包括锚框、实例特征和锚框嵌入,其中锚框用来描述目标状态的结构化信息,用于在图像中初始化和预测目标的位置和尺寸,实例特征表示通过图像编码器从图像数据中提取的复杂语义信息,锚框嵌入是对锚框信息的编码处理。
17、优选的,利用时间实例功能的循环传播方式包括:
18、对锚框进行投影,并利用锚框编码器对投影后的锚框进行编码,将目标的实例特征则保持其原始状态,公式如下所示:
19、at=projectt-1→t(at-1),et=ψ(at),ft=ft-1
20、其中,a代表锚框,e代表锚框嵌入,f指的是目标实例特征,ψ表示锚编码器;
21、将锚框设定为三维边界框,定义特定的投影函数,投影函数为:
22、at-1={x,y,z,w,l,h,sinyaw,cosyaw,vx,vy,vz}t-1,
23、[x,y,z]t=rt-1→t([x,y,z]+dt[vx,vy,vz])t-1+tt-1→t
24、[w,l,h]t=[w,l,h]t-1
25、[cosyaw,sinyaw,0]t=rt-1→t[cosyaw,sinyaw,0]t-1
26、[vx,vy,vz]t=rt-1→t[vx,vy,vz]t-1
27、其中,x,y,z是三维预测框的三维坐标,l,w,h是三维框的长宽高,a是三维框的观测角,vx,vy,vz分别是目标当前沿x,y,z方向的速度值,用于推断物体的运动状态,dt是第t帧和t-1帧之间的时间间隔,rt-1→t和tt-1→t分别表示自车从时间步长t-1到t的旋转和平移矩阵。
28、优选的,单帧层由时空可变形聚合、前馈网络以及用于细化和分类的输出三个子组件组成,所述多帧层还包括时空特征注意力模块和bev自注意力模块,其中时空特征注意力加强时空特征的融合,bev自注意力进行全局范围内的特征操作。
29、优选的,时空特征注意力加强时空特征的融合具体包括:
30、从历史帧实例信息获得时间特征xt∈rc×w×h,从图像编码器获得空间特征xs∈rc×w×h;
31、将时间特征通过一个1×1的卷积层生成一个query特征图qs,该查询特征图qs会被缩放成rc×n,其中n=w×n,将空间特征通过一个1×1的卷积层转为一个key特征图kt∈rn×c;
32、将qs的转置再乘以kt,通过softmax激活函数生成时空融合特征的注意力权重图o∈rn×n:
33、
34、其中,qi与kj分别为qs与kt特征图中的特征值,oji∈o表示的是通过空间特征图第i个像素和时间特征图第j个像素学习到的特征权重;
35、最后,使用另外两个卷积层生成的“值(value)”特征图(vs和vt),利用重塑操作re(·)改变特征图的尺度,并采用一个像素级相加以融合所有的特征图,最终的融合特征图m由下式得到:
36、m=re(vs·o)+xs+re(vt·o)+xt
37、其中,re(·)是重塑操作。
38、优选的,bev自注意力进行全局范围内的特征操作具体包括:
39、对于原始bev特征,通过三个线性变换转变为query、key和value三个特征序列;
40、将转置的key与query进行相似度计算得到权重;
41、使用softmax操作归一化权重;
42、将归一化的权重与对应的value进行加权求和,得到最终的自注意力特征图,bev自注意力机制的数学公式为:
43、
44、其中d代表bev自注意力机制中的维度。
45、优选的,时空可变形聚合的步骤包括:
46、输入特征图、投影点、历史帧特征信息和权重,输出当前帧特征信息;
47、将所有输入信息进行特征采样和缩放视图维度加权封装为cuda操作,在一个步骤中直接输出多点特征,进行多视图图像和多尺度的特征融合。
48、本发明的有益效果:
49、1.利用多相机图像和时空特征融合的方法进行环境感知,通过图像编码器将图像特征转换到bev特征,再输入到解码器中进行bev目标检测,输出3d目标检测框和对应的目标类别,准确识别遮挡目标和推断物体的运动状态,保证目标检测的准确性;
50、2.本发明充分利用时序信息和空间特征,利用时空特征融合注意力模块,充分融合时序信息和空间特征,提高推理和训练速度,弥补单帧感知的局限性,增加感受野,改善目标检测帧间跳动和目标遮挡问题,更加准确地判断目标运动速度,同时提高目标预测精度;
51、3.本发明利用一种时空可变形聚合模块,实现跨多个尺度和视图的多帧特征融合,从历史帧和当前帧的多个特征图中进行特征采样和加权求和,充分利用gpu和ai芯片的并行计算能力,显著提高了效率,同时减少了两种内存消耗和推理时间;
52、4.本发明为解决时空融合bev特征的上下文缺乏全局推理,以及不同位置分布的实例特征无法充分交互的情况,进一步设计bev自注意力机制模块进行特征的全局操作,增强全局推理能力并充分交互实例特征。
本文地址:https://www.jishuxx.com/zhuanli/20240822/280056.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。