模型训练方法及文本转化方法与流程
- 国知局
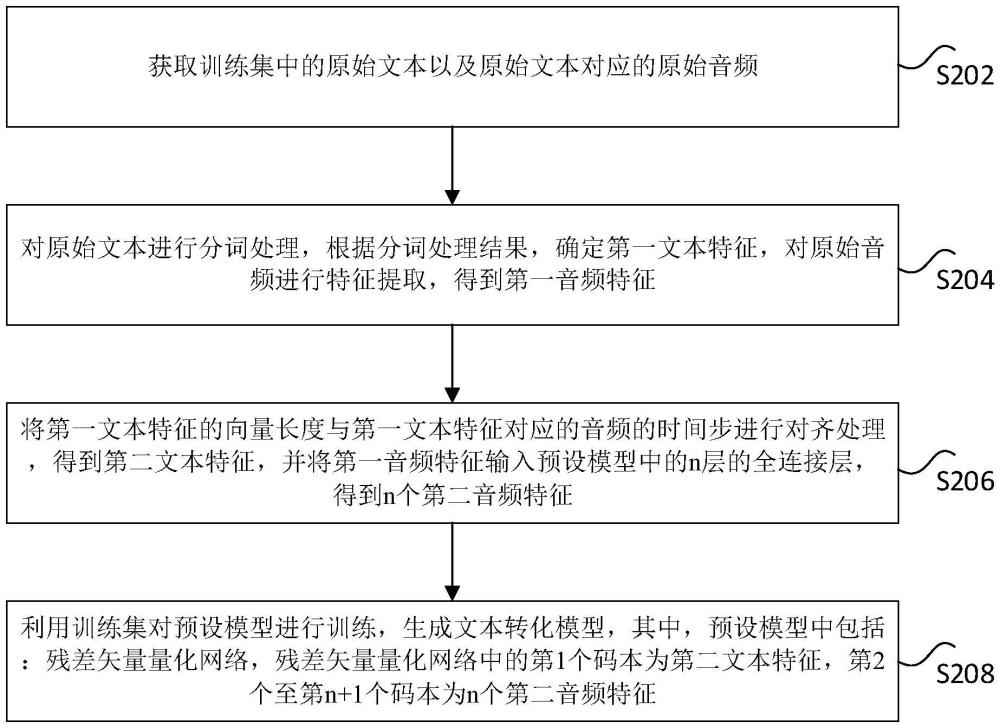
- 2024-08-22 14:55:14
本技术涉及音频生成,具体而言,涉及一种模型训练方法及文本转化方法。
背景技术:
1、语音合成(text to speech,tts)主要是通过组合多个模块构成流水线来实现的,整个系统可以大致分为前端(frontend)和后端(backend)。图1a示出了一种tts系统的结构图,其中,前端又称为语言分析部分,后端又称为声学系统部分,前端和后端基本独立。
2、在相关语音合成技术中,主要分为语言分析部分和声学系统部分,也称为前端部分和后端部分,语言分析部分主要是根据输入的文字信息进行分析,生成对应的语言学规格书,想好该怎么读;声学系统部分主要是根据语音分析部分提供的语音学规格书,生成对应的音频,实现发声的功能。
3、图1b示出了一种语言分析部分的处理流程图,具体包括如下步骤:文本结构与语种判断:当需要合成的文本输入后,先要判断是什么语种,例如中文,英文等,再根据对应语种的语法规则,把整段文字切分为单个的句子,并将切分好的句子传到后面的处理模块。文本标准化:在输入需要合成的文本中,有阿拉伯数字或字母,需要转化为文字。根据设置好的规则,使合成文本标准化。例如,“请问您是尾号为8967的机主吗?”“8967”为阿拉伯数字,需要转化为汉字“八九六七”,这样便于进行文字标音等后续的工作;文本转音素:在汉语的语音合成中,基本上是以拼音对文字标注的,所以我们需要把文字转化为相对应的拼音,但是有些字是多音字,怎么区分当前是哪个读音,就需要通过分词,词性句法分析,判断当前是哪个读音,并且是几声的音调。句读韵律预测:人类在语言表达的时候总是附带着语气与感情,tts合成的音频是为了模仿真实的人声,所以需要对文本进行韵律预测,什么地方需要停顿,停顿多久,哪个字或者词语需要重读,哪个词需要轻读等,实现声音的高低曲折,抑扬顿挫。
4、声学系统部分主要有三种技术实现方式,分别为:波形拼接,基于神经网络的参数合成系统以及端到端的语音合成技术等。严格来说端到端的语音合成技术的输入是原始文本,而并非经过前段处理的因素序列。
5、常见的tts系统例如:传统tts系统以及基于codec tokens的tts系统。其中,传统tts系统例如:wavenet,其中,wavenet不是一个端到端模型,由于它的输入并不是原始文本(raw text)而是经过处理的特征,因此它实际上只是代替了传统tts pipeline的后端(声学系统部分)。又例如:tacotron,tacotron2,fastspeech,其中,tacotron,tacotron2和fastspeech是一种基于深度学习的端到端语音合成系统,其输入为文本,输出为梅尔谱。
6、基于codec tokens的tts系统的出发点是把语言模型的概念套到audio上,让audio也可以实现类似gpt这种模式的生成。这些系统一般较为复杂,推理的耗时也较长,此外,这些系统不是为tts专门设计的,它们可以做到很多tts做不到的其他任务,例如语音续写,piano续写,声学环境保持,说话人情绪保持,说话人转换等功能。
7、例如:audiolm,其中,audiolm的整体架构包含三个部分,1.semantictransformer;2coarse transformer;3fine transformer。做生成的时候大致的流程是,在有prompt的情况下,audio先过w2v-bert得到semantic tokens,然后使用第一个模块semantic transformer得到semantic的未来预测,之后过第二个模块coarsetransformer,将semantic token映射到acoustic token,最后通过fine transformer将acoustic token进一步优化,最后再利用encodec的decoder将acoustic tokens解码回原始的音频wav。用高屋建瓴的观点来看,semantic tokens包含了句子的时序信息,而acoustic token包含了句子的整体信息,最后的fine transformer将两者做了结合,最终还原成语音。这个系统里语音的中间表示不再是梅尔谱,而是压缩的音频编码tokens(也叫做codebook),最终压缩的音频编码还原出语音。
8、又例如:vall-e,其中,图1c示出了一种vall-e的工作原理图,vall-e参考了audiolm的思路,但仅仅利用了acoustic tokens在tts任务上,并取得了惊人的效果。lm结构使模型有强大的in-context learning能力,使用phoneme作为prompt,实现标准的tts,使用音频做prompt,可以做到zero-shot的新说话人语音合成,以及情感/环境等信息的保留,3s音频即可复刻音色。
9、分析上述技术可知,传统方案技术过于复杂,需要多个系统的串联,tts的性能取决于优化的最差的模型的性能。基于encodec和lm的技术,例如audiolm成分复杂,包含了多个网络结构和多个tokens,且这个系统不专注于tts生成,它可以做其他一些音频生成的工作,不专一的特点使得它在某些合成中表现较差,噪音较多,且由于系统的复杂性,推理耗时也较长。
10、此外,vall-e系统需要经过处理的音素序列作为文本输入,额外增加了前端处理模块。进一步地,由于vall-e没有将text token融入codebook中,因此,vall-e没有时序性,所以vall-e的生成需要依赖音素序列和音频输入两个特征,进而导致文本转化的质量较差。
11、针对上述的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本技术实施例提供了一种模型训练方法及文本转化方法,以至少解决由于相关文本转化技术未在残差矢量量化网络的码本中充分利用文本特征,造成的文本转化质量较差的技术问题。
2、根据本技术实施例的一个方面,提供了一种模型训练方法,包括:获取训练集中的原始文本以及原始文本对应的原始音频;对原始文本进行分词处理,根据分词处理结果,确定第一文本特征,对原始音频进行特征提取,得到第一音频特征;将第一文本特征的向量长度与第一文本特征对应的音频的时间步进行对齐处理,得到第二文本特征,并将第一音频特征输入预设模型中的n层的全连接层,得到n个第二音频特征,其中,n为大于1的正整数;利用训练集对预设模型进行训练,生成文本转化模型,其中,预设模型中包括:残差矢量量化网络,残差矢量量化网络中的第1个码本为第二文本特征,第2个至第n+1个码本为n个第二音频特征。
3、可选地,预设模型还包括:待训练的第一卷积层、第一深度学习网络、第二卷积层、第二深度学习网络以及判别器。
4、可选地,对原始音频进行特征提取,得到第一音频特征,包括:将原始音频输入第一卷积层,得到第一卷积层输出的第一音频特征;将第一文本特征的向量长度与第一文本特征对应的音频的时间步进行对齐处理,得到第二文本特征,包括:将第一文本特征输入第一深度学习网络,利用第一深度学习网络预测第一文本特征对应的音频的时间步,并将第一文本特征的向量长度与第一文本特征对应的音频的时间步进行对齐处理,得到第一深度学习网络输出的第二文本特征。
5、可选地,将第一音频特征输入预设模型中的n层的全连接层,得到n个第二音频特征,包括:利用n层的全连接层中的第1个全连接层,对第一音频特征提取,得到第1个全连接层的输出的第1个第二音频特征;利用n层的全连接层中的第2个至第n个全连接层,依次对第1个至第n-1个全连接层输出的第1个第二音频特征至第n-1个第二音频特征进行特征提取,得到第2个至第n个全连接层输出的第2个至第n个第二音频特征。
6、可选地,通过如下方法生成预设模型中的残差矢量量化网络:将第1个第二音频特征确定为残差矢量量化网络中的第2个码本;将第u个第二音频特征确定为残差矢量量化网络中的第u+1个码本,其中,1<u<n,u为正整数;将第n个第二音频特征确定为残差矢量量化网络中的第n+1个码本。
7、可选地,利用训练集对预设模型进行训练,生成文本转化模型之前,方法还包括:采用残差矢量量化网络对第一音频特征进行处理,包括:在第1个码本中确定距离第一音频特征最近的第1个向量,并根据第1个向量和第一音频特征,得到第1个残差向量;在第v个码本中确定距离第v-1个残差向量最近的第v个向量,并根据第v个向量和第v-1个残差向量,得到第v残差向量,其中,1<v<n+1,v为正整数;根据第1个向量至第v个向量,得到残差矢量量化网络输出的编码特征量化结果。
8、可选地,得到残差矢量量化网络输出的编码特征量化结果之后,方法还包括:将编码特征量化结果输入第二卷积层以及第二深度学习网络,得到第二深度学习网络输出的目标音频;将目标音频输入判别器,得到判别器输出的判别结果。
9、可选地,利用训练集对预设模型进行训练,生成文本转化模型,包括:根据原始音频和目标音频,确定第一损失函数;根据到原始音频的原始频谱和目标音频的目标频谱,确定第二损失函数;根据残差矢量量化网络中n+1个残差向量,确定第三损失函数;根据目标音频,确定第四损失函数;根据目标音频、原始音频以及预设偏导数,确定第五损失函数;利用训练集、第一损失函数、第二损失函数、第三损失函数、第四损失函数以及第五损失函数,对预设模型进行训练,得到文本转化模型。
10、可选地,利用训练集、第一损失函数、第二损失函数、第三损失函数、第四损失函数以及第五损失函数,对预设模型进行训练,得到文本转化模型,包括:利用训练集以及第一损失函数,对第一卷积层、第一深度学习网络、残差矢量量化网络、第二卷积层以及第二深度学习网络进行训练;利用训练集以及第二损失函数,对第一卷积层、第一深度学习网络、残差矢量量化网络、第二卷积层以及第二深度学习网络进行训练;利用训练集以及第三损失函数,对第一深度学习网络以及残差矢量量化网络进行训练;利用训练集、第四损失函数以及第五损失函数,对判别器进行训练;在目标损失函数满足预设条件的情况下,完成对预设模型的训练,得到文本转化模型,其中,目标损失函数包括:第一损失函数、第二损失函数、第三损失函数、第四损失函数以及第五损失函数。
11、可选地,原始文本对应的码本空间与原始音频对应的码本空间一致。
12、根据本技术实施例的再一方面,还提供了一种文本转化方法,包括:获取待处理文本,对待处理文本进行分词处理,得到第一特征;将第一特征的向量长度与第一特征对应的音频的时间步进行对齐处理,得到第二特征;将第二特征和/或预设音频输入文本转化模型,得到文本转化模型输出的音频,其中,文本转化模型为采用上述的模型训练训练得到的。
13、根据本技术实施例的再一方面,还提供了一种模型训练装置,包括:获取模块,用于获取训练集中的原始文本以及原始文本对应的原始音频;第一处理模块,用于对原始文本进行分词处理,根据分词处理结果,确定第一文本特征,对原始音频进行特征提取,得到第一音频特征第二处理模块,用于将第一文本特征的向量长度与第一文本特征对应的音频的时间步进行对齐处理,得到第二文本特征,并将第一音频特征输入预设模型中的n层的全连接层,得到n个第二音频特征,其中,n为大于1的正整数;训练模块,用于利用训练集对预设模型进行训练,生成文本转化模型,其中,预设模型中包括:残差矢量量化网络,残差矢量量化网络中的第1个码本为第二文本特征,第2个至第n+1个码本为n个第二音频特征。
14、根据本技术实施例的再一方面,还提供了一种非易失性存储介质,存储介质包括存储的程序,其中,程序运行时控制存储介质所在的设备执行以上的模型训练方法。
15、根据本技术实施例的再一方面,还提供了一种电子设备,包括:存储器和处理器,处理器用于运行存储在存储器中的程序,其中,程序运行时执行以上的模型训练方法。
16、根据本技术实施例的再一方面,还提供了一种计算机程序,其中,所述计算机程序被处理器执行时实现以上的模型训练方法。
17、根据本技术实施例的再一方面,还提供了一种计算机程序产品,计算机程序产品包括非易失性计算机可读存储介质,其中,非易失性计算机可读存储介质存储计算机程序,计算机程序被处理器执行时实现以上的模型训练方法。
18、在本技术实施例中,采用获取训练集中的原始文本以及原始文本对应的原始音频;对原始文本进行分词处理,根据分词处理结果,确定第一文本特征,对原始音频进行特征提取,得到第一音频特征;将第一文本特征的向量长度与第一文本特征对应的音频的时间步进行对齐处理,得到第二文本特征,并将第一音频特征输入预设模型中的n层的全连接层,得到n个第二音频特征,其中,n为大于1的正整数;利用训练集对预设模型进行训练,生成文本转化模型,其中,预设模型中包括:残差矢量量化网络,残差矢量量化网络中的第1个码本为第二文本特征,第2个至第n+1个码本为n个第二音频特征的方式,达到了在残差矢量量化网络的码本中充分利用文本特征的目的,从而实现了提升文本转化质量的技术效果,进而解决了由于相关文本转化技术未在残差矢量量化网络的码本中充分利用文本特征,造成的文本转化质量较差的技术问题。
本文地址:https://www.jishuxx.com/zhuanli/20240822/280403.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表