基于自回归类深度学习语音合成的可控输出方法及设备与流程
- 国知局
- 2024-08-22 14:37:42
本发明涉及自然语言处理和深度学习,更为具体的,涉及一种基于自回归类深度学习语音合成的可控输出方法及设备。
背景技术:
1、自回归类深度学习语音合成方法建立文本端输入与mel频谱端输出的映射关系,基于已生成的部分来预测后续语音,这使得生成的语音在整体结构和局部细节上都较为自然和连贯,更接近真实人类语音。常用的自回归类深度学习语音合成模型在推理阶段会利用随机采样策略提升语音的多样性。尽管随机采样策略的引入使得语音更加流畅、自然,但是也可能加重漏词、重复、说错词现象。
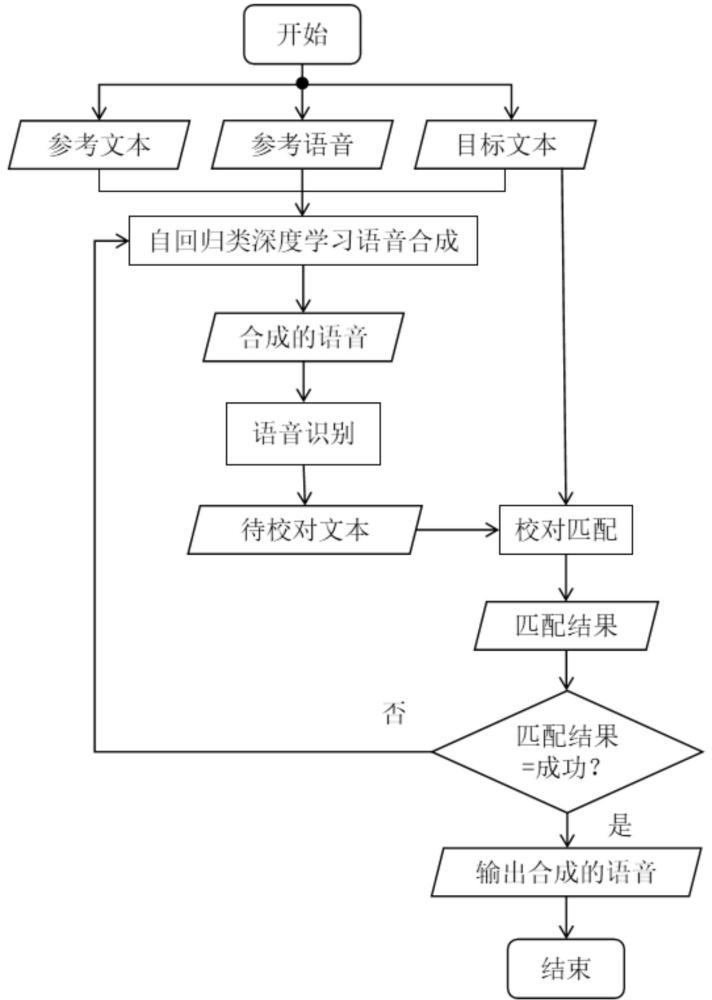
2、通过优化自回归类深度学习语音合成模型的训练可以较好改善漏词、重复、说错词现象,但是数据的收集、标注以及模型的训练都会耗费大量的时间。通过嵌入语音识别模块及校对模块对自回归类深度学习合成的语音进行检查,能够有效改善漏词、重复、说错词现象,并且无需训练。具体而言,通过自回归类深度学习语音合成方法合成参考文本、参考语音、目标文本对应的语音,提取合成语音对应的待校对文本,分别对待校对文本和目标文本进行文本规范化处理和音素提取,然后对待校对文本和目标文本的音素进行字符匹配。若匹配成功,则输出语音;否则重新生成语音,并重复上述步骤。这样,通过嵌入语音识别模块及校对模块检测出异常的语音,当检测出异常后对其进行重新生成,能较好地改善语音合成中出现的漏词、重复、说错词问题,自动化地实现了文字信息自然、流畅、准确的语音化表达。
技术实现思路
1、本发明的目的在于克服现有技术的不足,提供一种基于自回归类深度学习语音合成的可控输出方法及设备,为改善自回归类深度学习语音合成中出现的漏词、重复、说错词问题,提供了新的解决方案。
2、本发明的目的是通过以下方案实现的:
3、一种基于自回归类深度学习语音合成的可控输出方法,包括以下步骤:
4、s1:基于自回归类深度学习语音合成方法,提取目标文本和参考文本的特征,以及提取参考音频的特征,将提取好的特征送入自回归类深度学习模型进行语音合成后,得到合成的语音;
5、s2:对合成的语音进行语音识别,得到合成的语音对应的待校对文本;
6、s3:对目标文本和待校对文本进行文本规范化处理,得到只含发音文字的目标文本和待校对文本,然后根据文本与音素间的固定编码关系,分别得到目标文本音素和待校对文本音素,再对目标文本音素和待校对文本音素进行音素匹配,并输出匹配结果;
7、s4:对匹配结果进行判断,若匹配结果为成功,则合成的语音中没有出现漏词、重复、说错词问题,输出合成的语音;否则,回到步骤s1重新进行语音合成。
8、进一步地,在步骤s1中,所述提取目标文本和参考文本的特征,具体包括子步骤:利用bert模型提取目标文本和参考文本的特征,具体包括子步骤:
9、s21:将文本切割为若干个字单元,通过查询字向量表将字单元转换为一维字向量;
10、s22:提取每个字向量对应的文本向量和位置向量;
11、s23:将字向量、文本向量和位置向量的加和输入transformer模型,输出文本特征。
12、进一步地,在步骤s1中,所述提取参考音频的特征,具体包括子步骤:利用hubert模型提取参考音频的特征,且hubert模型在特征提取时只对部分音频帧进行预测,而利用未被掩码的部分来预测被掩码的部分,从而使模型能够在未见输入的情况下正确预测音频内容。
13、进一步地,在步骤s1中,所述将提取好的特征送入自回归类深度学习模型进行语音合成,具体包括子步骤:所述自回归类深度学习模型由transformer模型和vits模型的解码部分组成,且语音合成的执行过程具体包括子步骤:
14、s31:提取参考语音的短时傅里叶变化特征;
15、s32:将步骤s1中获取的目标文本特征、参考音频特征和参考文本特征送入transformer模型进行编码,得到语义特征;
16、s33:将步骤s32得到的语义特征和步骤s31的短时傅里叶变化特征输入vits解码部分,得到合成的语音。
17、进一步地,所述文本向量在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字的语义信息相融合。
18、进一步地,所述位置向量通过对字向量的位置进行编码,使得文本不同位置的字能表达不同的语义信息。
19、进一步地,所述vits解码部分使用hifigan的声码器作为其核心组件。
20、进一步地,在步骤s2中,所述对合成的语音进行语音识别具体基于语音识别的方法,利用paraformer模型对合成的语音进行语音识别。
21、进一步地,在步骤s3中,所述文本规范化处理,具体包括子步骤:使用正则表达式匹配并删除所有的标点符号。
22、进一步地,在步骤s3中,所述音素匹配,具体包括子步骤:对目标文本音素和待校对文本音素的相同位置的元素进行逐个检查,如果目标文本音素和待校对文本音素相同位置的元素完全一致,则输出成功,否则输出失败。
23、进一步地,在步骤s3中,所述根据文本与音素间的固定编码关系,分别得到目标文本音素和待校对文本音素,具体包括子步骤:通过提取文本的汉语拼音,并按声母、韵母和声调的方式提取文本音素。
24、进一步地,在步骤s4中,所述对匹配结果进行判断,若匹配结果为成功,则合成的语音中没有出现漏词、重复、说错词问题,输出合成的语音;否则,回到步骤s1重新进行语音合成还包括子步骤:引入最大匹配次数限制,用于避免匹配一直失败导致的算法死循环,当校对匹配次数超过设定值时,直接输出合成的语音。
25、一种基于自回归类深度学习语音合成的可控输出设备,包括处理器和存储器,在存储器中存储有程序,当程序被处理器加载时,执行如上任一项所述的基于自回归类深度学习语音合成的可控输出方法。
26、本发明的有益效果包括:
27、本发明方法中,首先分别对参考文本、参考语音、目标文本进行特征提取,利用自回归类深度学习模型对其进行预测,得到合成的语音。其次,对合成的语音进行语音识别,得到待校对文本。再次,通过文本规范化处理滤除目标文本和待校对文本的标点符号。接着,利用文本与音素间的固定编码关系得到目标文本音素和待校对文本音素。最后,对目标文本音素和待校对文本音素进行音素匹配,若音素匹配成功,则输出语音,否则重新进行上述步骤。基于上述步骤。本发明能够有效提高输出语音准确性,改善自回归类深度学习语音合成结果中出现的漏词、重复、说错词现象,得到自然、流畅、准确的语音。
技术特征:1.一种基于自回归类深度学习语音合成的可控输出方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于自回归类深度学习语音合成的可控输出方法,其特征在于,在步骤s1中,所述提取目标文本和参考文本的特征,具体包括子步骤:利用bert模型提取目标文本和参考文本的特征,具体包括子步骤:
3.根据权利要求1所述的基于自回归类深度学习语音合成的可控输出方法,其特征在于,在步骤s1中,所述提取参考音频的特征,具体包括子步骤:利用hubert模型提取参考音频的特征,且hubert模型在特征提取时只对部分音频帧进行预测,而利用未被掩码的部分来预测被掩码的部分,从而使模型能够在未见输入的情况下正确预测音频内容。
4.根据权利要求1所述的基于自回归类深度学习语音合成的可控输出方法,其特征在于,在步骤s1中,所述将提取好的特征送入自回归类深度学习模型进行语音合成,具体包括子步骤:所述自回归类深度学习模型由transformer模型和vits模型的解码部分组成,且语音合成的执行过程具体包括子步骤:
5.根据权利要求2所述的基于自回归类深度学习语音合成的可控输出方法,其特征在于,所述文本向量在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字的语义信息相融合。
6.根据权利要求2所述的基于自回归类深度学习语音合成的可控输出方法,其特征在于,所述位置向量通过对字向量的位置进行编码,使得文本不同位置的字能表达不同的语义信息。
7.根据权利要求4所述的基于自回归类深度学习语音合成的可控输出方法,其特征在于,所述vits解码部分使用hifigan的声码器作为其核心组件。
8.根据权利要求1所述的基于自回归类深度学习语音合成的可控输出方法,其特征在于,在步骤s2中,所述对合成的语音进行语音识别具体基于语音识别的方法,利用paraformer模型对合成的语音进行语音识别。
9.根据权利要求1所述的基于自回归类深度学习语音合成的可控输出方法,其特征在于,在步骤s3中,所述文本规范化处理,具体包括子步骤:使用正则表达式匹配并删除所有的标点符号。
10.根据权利要求1所述的基于自回归类深度学习语音合成的可控输出方法,其特征在于,在步骤s3中,所述音素匹配,具体包括子步骤:对目标文本音素和待校对文本音素的相同位置的元素进行逐个检查,如果目标文本音素和待校对文本音素相同位置的元素完全一致,则输出成功,否则输出失败。
11.根据权利要求1所述的基于自回归类深度学习语音合成的可控输出方法,其特征在于,在步骤s3中,所述根据文本与音素间的固定编码关系,分别得到目标文本音素和待校对文本音素,具体包括子步骤:通过提取文本的汉语拼音,并按声母、韵母和声调的方式提取文本音素。
12.根据权利要求1所述的基于自回归类深度学习语音合成的可控输出方法,其特征在于,在步骤s4中,所述对匹配结果进行判断,若匹配结果为成功,则合成的语音中没有出现漏词、重复、说错词问题,输出合成的语音;否则,回到步骤s1重新进行语音合成还包括子步骤:引入最大匹配次数限制,用于避免匹配一直失败导致的算法死循环,当校对匹配次数超过设定值时,直接输出合成的语音。
13.一种基于自回归类深度学习语音合成的可控输出设备,其特征在于,包括处理器和存储器,在存储器中存储有程序,当程序被处理器加载时,执行如权利要求1~12中任一项所述的基于自回归类深度学习语音合成的可控输出方法。
技术总结本发明公开了一种基于自回归类深度学习语音合成的可控输出方法及设备,属于自然语言处理和深度学习领域,包括步骤:基于自回归类深度学习语音合成完成对参考文本、参考语音、目标文本的语音合成;基于语音识别提取合成语音的待校对文本信息;基于校对匹配去除目标文本和待校对文本中所有非文字部分,分别提取目标文本音素和待校对文本音素,对目标文本音素和待校对文本音素进行音素匹配,输出匹配结果。若匹配结果为成功,则输出语音,否则重新进行以上步骤,直至校对匹配成功。本发明可实现自回归类深度学习语音合成的自动校对,改善自回归类深度学习语音合成中出现的漏词、重复、说错词的问题,提升自回归类深度学习语音合成的稳定性。技术研发人员:陈尧森,姚羽,温序铭受保护的技术使用者:成都索贝数码科技股份有限公司技术研发日:技术公布日:2024/8/20本文地址:https://www.jishuxx.com/zhuanli/20240822/279292.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。