基于改进端到端语音合成模型提升流式语音自然度的方法、系统、设备及介质与流程
- 国知局
- 2024-08-19 14:28:32
本发明涉及智能语音,具体涉及一种基于改进端到端语音合成模型提升流式语音合成自然度的方法。
背景技术:
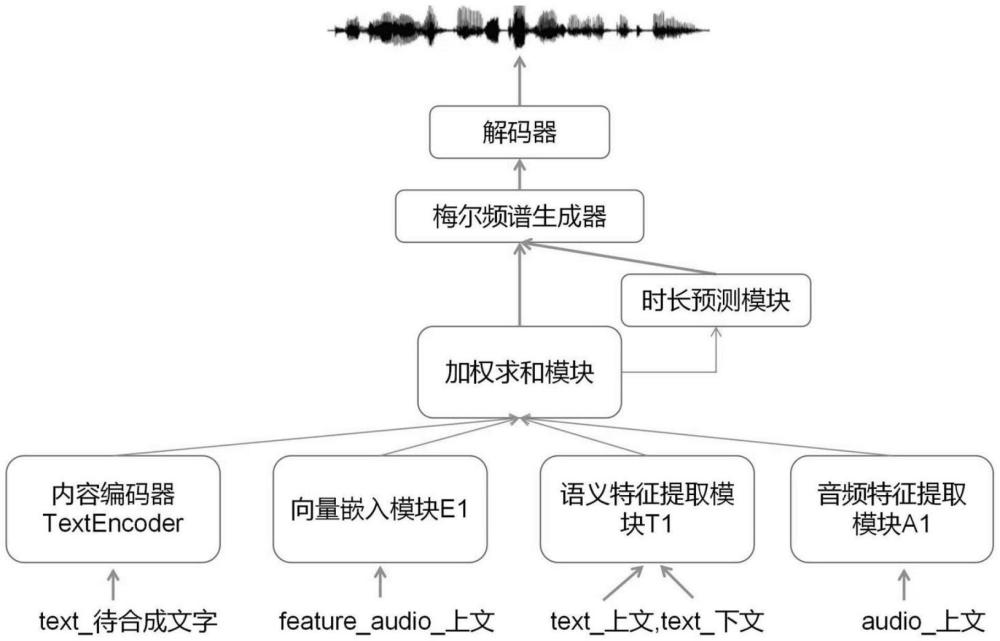
1、主流的端到端语音合成模型结构通常包含:内容编码器、时长预测器、梅尔频谱生成器以及解码器。其中,内容编码器负责将输入的文本转化为内容特征向量;时长预测器则基于这些特征向量,预测每个音节的发音时长,并据此对内容特征向量进行复制和排列;随后,这些特征向量被送入梅尔频谱生成器,以生成合成的梅尔频谱;最终,解码器将这些频谱转化为音频波形,保存为wav文件。
2、然而,传统的端到端模型训练方法是:每次喂入模型的数据为(audio,text),其中audio为一句完整的句子,text为音频对应文字。这种训练方式在流式合成时会导致:针对非标点符号处断句合成的分句,相邻分句间不自然的停顿、不连贯非常明显。
3、为了实现流式语音合成的无延迟效果,需要满足:在当前音频播放完成前,完成下一分句音频的合成。所以,一种常见的策略是:将输入的文字尽可能分割成长度相近的句子进行合成。否则,当短句与长句交替出现时,短句播放完毕后需要等待长句合成完成,从而产生不自然的停顿。(如果出现“此外,”“清华大学还是国内很著名的高校”的分句情况,第一句音频时长0.3s,第二句由于太长,合成需要0.5s,则会出现“此外,”念完后,卡顿0.2s才开始念下一句的情况)
4、目前,主流的分句方法主要是:按照标点符号将待合成文字切分成短句,然后对这些短句进行快速合成。对于较长的无标点句子,根据韵律短语进行进一步切分,如:流式荧光技术是/a公司最主要的/一个技术,语句在斜杠处切分成三个短句,再先后用语音合成模型进行合成。这样就能尽可能保证每一个分句都是较短句子,控制合成时间。但是,这种切分方式在语音合成中仍存在问题。由于模型将每个切分后的短句视为独立的句子进行合成,因此在拼接后的合成音频的衔接处会出现不自然的停顿,类似于人在句子末尾闭口时的声波波形振幅逐渐归零的现象,导致音频听起来存在明显的停顿;如,先后喂入模型的句子:“流式荧光技术是”,“a公司最主要的”,“一个技术”模型认为是三个独立的句子,所以合成的音频在衔接处会出现不自然的停顿、难以直接连接上。
技术实现思路
1、针对上述问题,本发明会对训练数据、训练模块进行调整,使端到端语音模型的输入变为(context,audio,text),并且在损失函数中添加一个l1loss,控制模型当前音频与上文音频衔接处波形振幅尽可能一致,使模型具备合成能够和上下文音频自然衔接的音频的能力。
2、本发明提出了一种针对流式语音合成的方法,通过将前一分句的语义、声学特征及后一分句的语义特征作为背景向量,输入到当前分句的音频合成中,并通过一定的后处理方法使音频衔接处波形振幅自然连接;具体包括:
3、获取训练数据,通过mfa模型对所述训练数据进行音频、文本对齐,对所述音频进行随机切分;
4、在端到端模型的模型基础上,添加语义特征提取模块、音频特征提取模块和向量嵌入模块;
5、改写损失函数,得到预训练好的语音合成模型。
6、优选的,通过mfa模型对原有训练数据进行音频、文本对齐。并且对原有音频进行随机切分,将50%原有(audio,text)处理成三段式({audio1,audio2,audio3},{text1,text2,text3})。
7、如一句话音频:“不得不说,今天的天气非常不错”被随机切分成:
8、text 1=“不得不说,”;
9、text 2=“今天的天气”;
10、text 3=“非常不错”;
11、剩下50%数据还是以(audio,text)格式保存。
12、优选的,在端到端模型模块基础上,添加一个基于transformer的语义特征提取模块t1、一个基于wav2vec或hubert的音频特征提取模块a1和向量嵌入模块e1。
13、优选的,替换端到端模型的textencoder内容编码器,改进后训练时的模型输入有两种情况:
14、(1)抽取到({audio1,audio2,audio3},{text1,text2,text3})格式保存的数据,则:
15、context_text1=t1(text1);
16、context_text3=t1(text3);
17、context_audio1=a1(audio1);
18、f_embedding=e1(feature_audio1);
19、其中,
20、feature_audio1为音频audio1的尾帧波形振幅;
21、模型输入为:
22、(a*textencoder(text2)+b*context_text1+c*context_text3+d*context_audio1+e*f_embedding)加权和;
23、输出为audio2的波形预测文件prediction_audio2;
24、(2)抽取到(audio,text)格式保存的数据,则按原有方式进行训练:即输入为textencoder(text2),输出为audio2的波形预测文件prediction_audio2。
25、优选的,改写损失函数:
26、new_loss=loss_端到端+l1_loss(feature_audio2,feature_audio1)
27、其中,
28、feature_audio2是合成prediction_audio2首帧振幅;
29、feature_audio1为音频audio1的尾帧波形振幅。
30、优选的,得到预训练好的语音合成模型:
31、当输入为(none,text)时候,它就会合成与text对应的单句话audio;
32、当输入为(text1,audio1,feature_audio1,text3,text2)时,它就会合成形如一个完整音频的中间片段audio2。
33、优选的,在实际流式合成时,当合成了audio2时,则可根据audio1尾帧的振幅,将audio2进行振幅归一化,使拼接处波形振幅一致,从而使audio1、audio2在播放时连贯自然。
34、基于上述提出的基于改进端到端语音合成模型提升流式语音自然度的方法,为了更好地实现本发明,进一步地提出一种基于改进端到端语音合成模型提升流式语音自然度的系统,包括:
35、分析模块、端到端模块、语音合成模块;
36、数据分析模块,获取训练数据,通过mfa模型对所述训练数据进行音频、文本对齐,对所述音频进行随机切分;
37、端到端模块,在端到端模型的模型基础上,添加语义特征提取、音频特征提取和向量嵌入;
38、语音合成模块,改写损失函数,得到预训练好的语音合成模型。
39、基于上述提出的基于改进端到端语音合成模型提升流式语音自然度的方法,为了更好地实现本发明,进一步地提出一种电子设备,包括存储器和处理器;所述存储器上存储有计算机程序;当所述计算机程序在所述处理器上执行时,实现上述的基于改进端到端语音合成模型提升流式语音自然度的方法。
40、基于上述提出的基于改进端到端语音合成模型提升流式语音自然度的方法,为了更好地实现本发明,进一步地提出一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机指令;当所述计算机指令在上述的电子设备上执行时,实现上述的基于改进端到端语音合成模型提升流式语音自然度的方法。
41、有益效果:
42、通过本发明训练的流式语音合成模型,可以确保在输入句子分割十分细碎的时候,分句与分句之间的合成由于具备上文context信息,能够在分句音频拼接后听起来连贯、自然,避免出现以往流式模型容易产生的分句间不连贯的问题。同时,由于模型输入具有给定上文context信息,就能与上文语音自然相连的特点,可以让流式合成对于输入文本切割的工作更轻松,能够自由按设置字数切割,确保每个合成的分句都是较少字数,且不需要韵律/标点断句等模块辅助分句,进一步提升流式合成的流畅度。
43、其次,在模型能确保和上文衔接自然的情况下,分句就不需要刻意按韵律断或者标点断。以往的语音模型我们往往是按韵律、标点断句,由于把词组都给打断了,旧有语音模型会合成很机械。但本发明所提出的模型,由于输入到模型有上下文信息,能保证它和上下文音频拼接时自然,输入的句子可以被切分的特别短,并且不需要辅助模块来帮分句,进一步节约合成时间,使流式合成延迟大大降低,提高流畅度
本文地址:https://www.jishuxx.com/zhuanli/20240819/275330.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。