复杂背景噪声环境下基于声谱图和长短时记忆网络的语音识别方法及系统
- 国知局
- 2024-08-22 14:26:13
本发明涉及语音识别领域,具体是复杂背景噪声环境下基于声谱图和长短时记忆网络的语音识别方法及系统。
背景技术:
1、传统语音识别系统在复杂噪声环境下存在性能差、识别率不高的问题,具体表现主要有以下几种:
2、1)噪声干扰:传统语音识别系统通常对背景噪声敏感,尤其是当噪声水平较高时。例如,在街道噪音、人群谈话声或机械噪声等复杂背景下,系统的识别准确率可能显著下降。
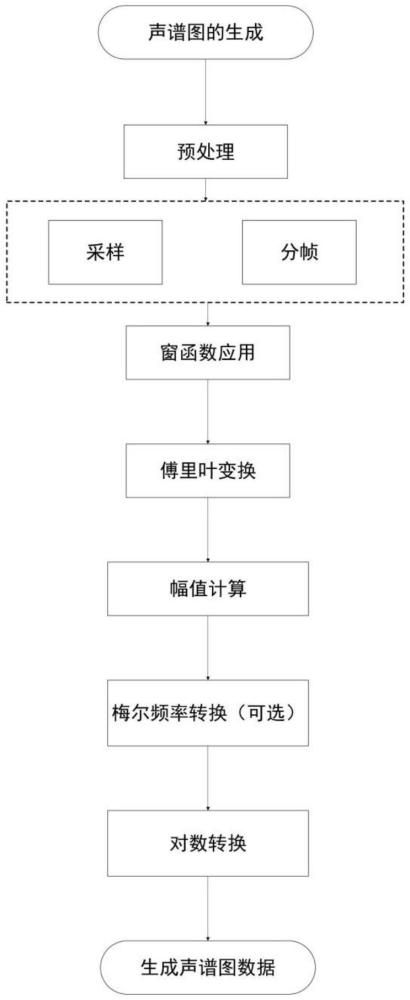
3、2)特征提取不足:早期的系统依赖于较为简单的声学特征提取技术,如线性预测编码(lpc)或梅尔频率倒谱系数(mfcc),这些方法在复杂噪声环境下可能无法有效区分语音和噪声。
4、3)模型泛化能力不足:传统模型,如隐马尔可夫模型(hmm)或基于gaussianmixture model(gmm)的系统,可能在噪声条件变化时泛化能力不足,难以适应不同类型的噪声环境。
5、4)语音和噪声难以分离:在复杂噪声环境下,传统系统往往难以有效地分离语音和噪声,尤其是当噪声与语音在频谱上有重叠时。
6、5)实时处理能力有限:处理复杂噪声通常需要更复杂的算法和更多的计算资源,这可能超出了早期系统的实时处理能力。
7、6)缺乏环境适应性:传统系统通常需要在特定的噪声环境中进行训练,缺乏对新环境的适应性,因此在未知的噪声条件下表现不佳。
8、7)缺乏有效的去噪策略:虽然一些传统系统尝试通过噪声抑制技术改善性能,但这些方法在复杂的噪声环境中效果有限。
技术实现思路
1、本发明的目的是提供复杂背景噪声环境下基于声谱图和长短时记忆网络的语音识别方法,包括以下步骤:
2、1)获取用于训练的音频信号,并生成对应的声谱图;
3、2)对声谱图进行处理;
4、3)利用所述声谱图构建语音识别模型;
5、4)获取待识别的音频信号,并生成对应的待识别声谱图;
6、5)将待识别声谱图输入至语音识别模型中,得到语音识别结果。
7、进一步,生成对应声谱图的步骤包括:
8、1.1)对音频信号进行数字化处理;
9、1.2)对数字化的音频信号进行分割,得到若干短时帧音频数据;
10、1.3)将每帧音频数据与一个汉宁窗函数相乘,以减少帧边缘的不连续性;
11、经过汉宁窗处理的音频数据如下所示:
12、
13、x′(n)=x(n)×w(n) (2)
14、式中,w(n)表示汉宁窗函数;x(n)表示原始音频数据;x′(n)表示经过汉宁窗加权处理的音频数据;n=0,1,...,n-1,n是窗口函数的长度;n为窗口函数总长度;
15、1.4)对相乘后的每帧音频数据进行快速傅里叶变换,分析每帧音频数据中不同频率成分的复数幅值x(k);
16、每帧音频数据在不同频率成分下的复数幅值x(k)如下所示:
17、
18、式中,k表示频率索引,在快速傅里叶变换后得到的频谱中,每个k对应一个特定的频率,具体取决于采样率和所分析帧的大小。每个k的复数幅值x(k)表示了该频率成分在音频帧中的强度和相位。
19、1.5)对频率成分进行对数变换。
20、进一步,相邻两帧音频数据之间具有重叠。
21、进一步,对频率成分进行对数变换前,还对频率成分进行梅尔尺度转换;
22、梅尔尺度转换后的频率m如下所示:
23、
24、式中,f为梅尔尺度转换前的频率。
25、进一步,对声谱图进行处理的步骤包括:
26、2.1)对声谱图进行标准化或归一化处理;
27、2.2)对声谱图进行噪声抑制、回声消除处理;
28、2.3)提取声谱图中的梅尔频率倒谱系数特征;
29、2.4)基于梅尔频率倒谱系数特征,采用时间扩展、时间压缩和/或音高变化的方式对声谱图进行数据增强,。
30、进一步,利用所述声谱图构建语音识别模型的步骤包括:
31、3.1)为声谱图打上语音识别标签,并划分为训练集、验证集和测试集;
32、3.2)对声谱图进行特征提取,得到梅尔频率倒谱系数;
33、3.3)构建lstm网络,所述lstm网络包括一个或多个lstm层;
34、lstm网络的前向传播过程中,每个lstm单元的输出ht如下所示:
35、ft=σ(wf·[ht-1,xt]+bf) (5)
36、it=σ(wi·[ht-1,xt]+bi) (6)
37、
38、ot=σ(wo·[ht-1,xt]+bo) (9)
39、ht=ot*tanh(ct) (10)
40、式中,xt是当前输入,ht-1是上一时刻的输出,ft、it、ot分别是遗忘门、输入门和输出门的输出,是候选细胞状态,ct是细胞状态,wf、wi、wc、wo和bf、bi、bc、bo是网络需要学习的权重和偏置参数;σ是激活函数;ct-1是上一时刻细胞状态;
41、3.4)利用训练集对lstm网络进行训练,并利用验证集监控过拟合和性能;
42、lstm网络中,参数通过梯度下降法进行更新,更新后的参数如下所示:
43、
44、式中,w′、b′为更新后的权重和偏置;α为学习率;l为损失函数;
45、损失函数l如下所示:
46、yt=softmax(w′y·ht+b'y) (13)
47、
48、式中,yt是音频的真实标签,是模型的预测标签;
49、3.5)利用验证集和测试集对训练后的lstm网络进行验证,若lstm网络的词错误率小于预设阈值,则输出语音识别模型。
50、进一步,所述lstm网络的损失函数为交叉熵函数,优化器为adam优化器。
51、进一步,lstm网络训练过程中,对学习率、批大小、lstm单元数进行更新。
52、进一步,将待识别声谱图输入至语音识别模型中,得到语音识别结果的步骤包括:
53、5.1)对待识别声谱图进行特征提取,得到待识别声谱图的梅尔频率倒谱系数;
54、5.2)将待识别声谱图的梅尔频率倒谱系数输入至语音识别模型中,得到语音识别结果;
55、5.3)对语音识别结果进行解码,转换为语音识别文本。
56、一种应用所述语音识别方法的系统,包括语音获取模块、信号处理模块、语音识别模块和识别结果输出模块;
57、所述语音获取模块获取待识别的音频信号,并传输至信号处理模块;
58、所述信号处理模块生成音频信号对应的待识别声谱图,提取待识别声谱图的梅尔频率倒谱系数,并传输至语音识别模块;
59、所述语音识别模块存储有语音识别模型;
60、所述语音识别模块利用语音识别模型对梅尔频率倒谱系数进行处理,得到语音识别结果,并传输至识别结果输出模块;
61、所述识别结果输出模块对语音识别结果进行解码,转换为语音识别文本,并输出。
62、本发明的技术效果是毋庸置疑的,本发明的有益效果如下:
63、1)提高识别准确度:本发明通过结合声谱图和lstm网络,能够更精准地从复杂背景噪声中分离和识别语音信息。声谱图提供了丰富的时间-频率信息,帮助算法更好地理解和处理语音信号,而lstm网络则能捕捉语音中的长期依赖关系,从而提高在变化语速和有暂停的语音中的识别准确度。
64、2)增强算法的鲁棒性:在多变的噪声环境下,本发明通过有效的特征提取和先进的序列建模,保持较高的识别性能。本发明提高了系统对于不同噪声水平和类型的适应能力,从而在各种复杂环境下都能保持稳定的识别效果。
65、3)优化去噪效果:利用声谱图和lstm结合的方法,本发明能够准确区分语音和噪声,尤其是在结合了注意力机制的lstm模型时,能够更有效地关注语音部分,减少噪声干扰,提高在嘈杂环境中的识别性能。
66、4)强化算法的适应性:lstm网络的灵活性使得算法可以通过训练适应不同的语音和噪声条件,从而在各种复杂环境下都保持较好的性能。
67、5)提升实时处理能力:本发明能够在实时或接近实时的条件下运行,适用于需要快速响应的应用场景。
68、6)广泛的适用性:这种算法不仅适用于通用的语音识别任务,还可以应用于特殊需求的场合,如在嘈杂的公共场所或工业环境中的语音识别,增加了其应用范围和灵活性。
69、综上所述,本发明在复杂背景噪声环境下的语音识别任务中,可以显著提升识别准确率和系统的整体性能,增强算法的鲁棒性和适应性,从而更好地满足实际应用中的需求。
本文地址:https://www.jishuxx.com/zhuanli/20240822/278651.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表