一种多翻译线程的盲文翻译任务调度方法及装置与流程
- 国知局
- 2024-08-22 14:56:29
本发明涉及计算机,尤其涉及一种多翻译线程的盲文翻译任务调度方法及装置。
背景技术:
1、盲人教育是一项关乎盲人群体未来发展的重要事业。随着科技的不断进步和社会的发展,盲人教育正面临着新的机遇和挑战。随着教育技术的不断改进和创新,盲人教育的方式也在不断演进。目前,在学校和社会中,针对于盲人的无障碍技术正在悄然兴起。该技术旨在打破盲人教育中的虚拟和物理限制,为盲人提供更多的学习资源和机会。例如,借助无障碍设备和应用程序,配备盲文电子书和辅助学习材料,提供无障碍的互联网资源和学习平台,确保盲人学生与其他学生享有相同的学习机会,因此,盲人阅读辅助产品及相关技术不断被提出,主要分为两类:
2、1)阅读器相关产品,这类产品以app和嵌入式设备为主,主要是用户采用拍照等方式主动将图像内容上传至设备中,设备采用视觉识别等方式将视觉信息转换为听觉或其它盲人能够识别的感觉信息,以此达到盲人阅读的目的。例如,罗伟等人提出的基于android的盲用手机阅读器设计,以及蔡玉树等提出的基于改进yolov5的盲人阅读辅助系统等,又如,公开号为cn107346629a的中国发明专利申请,提供了一种智能盲人阅读方法及智能盲人阅读器系统,其通过图像采集模块采用文本的图像信息上传到云服务器,进行处理得到识别结果,然后通过语音播放模块进行播放。
3、2)电子书城、电子图书馆等具有丰富阅读资源的公共平台。由于电子书城中存在各种各样的阅读资源,因此,被广泛使用,并由此衍生了各种根据用户偏好或兴趣进行自动推送阅读资源的方法。例如,庞晓艳提出的一种基于ti-idf内容推荐算法的盲人个性阅读服务系统设计,以及方彬提出的基于用户行为的盲人图书推荐方法。
4、然而,也正是由于电子书城中存在各种各样的阅读资源,但并不是所有的阅读资源都已经被翻译为盲文;另外,一些用户也需要上传待翻译文件进行翻译,或者将文件上传进行翻译后分享给其他用户;因此,这些需求最终都将触发该平台的翻译功能,以将其所需要阅读的文件翻译或转换为盲文。
5、也正是由于存在各种各样的阅读资源和翻译需求,因此,一旦用户需要阅读时,就需要将其进行翻译。通常,用户发起翻译请求,立即翻译并反馈给用户进行语音播放,或者连接相应的辅助设备,这样用户的体验是最好的。但对于电子书城这种公共平台,实际应用中,通常会在同一时段,甚至同一时刻由多个用户发起翻译请求,并且,大部分情况下,其所请求翻译的是大型文件,例如,名著的电子书,或者期刊等,这就使得需要考虑如何分配多个盲文翻译任务,以满足客户需求。
6、当同时存在多个盲文翻译任务时,通常会根据文件大小(或者说长短)来进行翻译任务的排序和分配等,或者根据发起翻译请求的先后顺序来排序。若仅仅根据文件大小来排序或分配,将面临以下问题:1)那么如何界定什么样的文件算大,什么样的文件算小?2)若采用一个预设阈值进行一刀切,那么对于该阈值左右的文件,其实际上相差不大,但两者翻译的先后顺序却差异非常大。若仅根据请求时间先后顺序,而忽略文件大小,那么就会存在因为当前翻译大文件而导致多个小文件较长时间不能够被翻译,随着时间的增长,待处理队列中的待翻译文件也会越来越多,降低用户体验。
技术实现思路
1、本发明的目的在于提供一种多翻译线程的盲文翻译任务调度方法及装置,部分地解决或缓解现有技术中的上述不足,能够提升用户体验。
2、为了解决上述所提到的技术问题,本发明具体采用以下技术方案:
3、本发明的第一方面,在于提供一种多翻译线程的盲文翻译任务调度方法,其包括步骤:
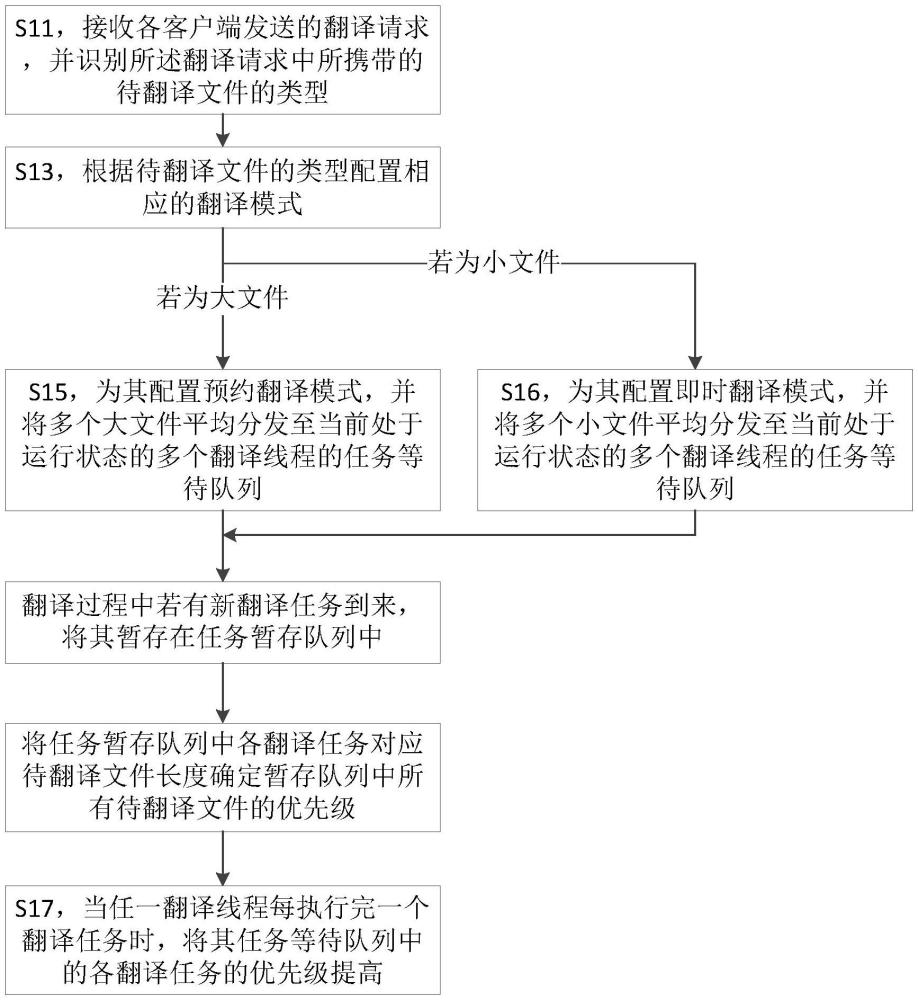
4、s11,接收各客户端发送的翻译请求,并识别所述翻译请求中所携带的待翻译文件的类型;所述待翻译文件的类型包括:长度大于或等于预设长度阈值的长文件,和长度小于预设长度阈值的短文件;
5、s13,根据所述待翻译文件的类型配置相应的翻译模式;所述翻译模式包括:预约翻译模式和即时翻译模式;
6、s15,若识别出所述待翻译文件为大文件,为其配置预约翻译模式,并将多个所述大文件平均分发至多个翻译线程的任务等待队列;
7、s16,若识别出所述待翻译文件为小文件,为其配置即时翻译模式,并将多个所述小文件平均分发至多个翻译线程的任务等待队列;
8、s17,当任一翻译线程每执行完一个翻译任务时,将其任务等待队列中的各翻译任务的优先级提高;
9、其中,初始状态时,当同一翻译线程的所述任务等待队列中同时存在多个所述大文件和多个所述小文件时,所述小文件的优先级高于所述大文件的优先级,且多个所述小文件按照达到时间的先后顺序进行优先级排序。
10、在一些实施例中,所述基于多翻译线程的盲文翻译任务调度方法还包括步骤:周期性地获取系统资源和当前待处理翻译文件中小文件的数量,并输入预先构建的翻译线程管理模型,得到当前需要同时开启的用于处理所述大文件的第一翻译线程目标总数,并根据所述第一翻译线程目标总数动态调整当前的第一翻译线程数量,其中,所述系统资源包括:cpu占用率和内存使用率。
11、在一些实施例中,所述基于多翻译线程的盲文翻译任务调度方法还包括步骤:将翻译过程中新收到的待翻译文件,为其创建新的翻译任务并存入对应翻译线程的任务暂存队列中;且当所述暂存队列中存在多个待翻译任务时,按照待翻译文件的长度从短到长的顺序确定各个待翻译文件的优先级,然后将各翻译任务转移至所述任务等待队列中。
12、在一些实施例中,预先构建所述翻译线程管理模型的步骤,具体包括步骤:
13、s21,根据不同cpu占用率和不同内存使用率下,翻译不同数量的待处理翻译文件所使用的第一翻译线程样本总数构建向量集,其中,不同数量的所述待处理翻译文件中小文件的数量不同,所述向量集中每个向量包括:cpu占用率、内存使用率、小文件的数量、第一翻译线程样本总数;
14、s23,针对所述向量中的每个变量进行区域划分,得到相应的模糊集合;所述模糊集合包括每个变量的一个分区,且每个变量的相邻分区之间有重叠区域;
15、s25,将每个所述向量映射到相应的模糊集合,得到相应的映射向量,并将所述映射向量输入初始模糊推理机,以构建所述cpu占用率、所述内存占用率和小文件数量到第一翻译线程总数的映射关系,得到所述翻译线程管理模型。
16、在一些实施例中,当根据所述第一翻译线程目标总数动态调整当前第一翻译线程数量,使得任一第一翻译线程即将被终止时,将所述任一第一翻译线程当前正在执行的翻译任务及其任务等待队列中的所有翻译任务分配至其他正在运行的翻译线程中,且根据所述待翻译文件的大小平均分配。
17、在一些实施例中,当根据所述第一翻译线程目标总数动态调整当前第一翻译线程数量,使得至少一个新翻译线程被开启时,根据文件大小将当前正在执行翻译任务的翻译线程的任务等待队列中的翻译任务平均的分配到所述新翻译线程中。
18、在一些实施例中,根据所述待翻译文件的类型配置相应的翻译模式的步骤,具体包括步骤:
19、s103,获取所述待翻译文件的决策指标参数,所述决策指标参数包括:所述待翻译文件的大小,以及服务端的当前cpu占用率和当前内存占用率;
20、s105,将所述决策指标参数输入预先构建的翻译决策推理机,得到所述待翻译文件采用相应翻译策略的概率p;所述翻译策略为即时翻译,或者预约翻译;
21、s107,将所述翻译策略的概率p映射到第一区间[a1,a2],得到映射后的概率p’,并生成随机数r,然后将所述随机数r映射到所述第一区间[a1,a2],得到映射随机数r’;
22、s109,判断所述映射随机数r’是否属于第二区间[a1,p’],若是,判定所述待翻译文件将采用相应的翻译策略,否则,判定所述待翻译文件将采用其他翻译策略。
23、在一些实施例中,预先构建所述模糊推理机的步骤,具体包括步骤:
24、s201,根据不同cpu占用率和不同内存使用率下,不同文件大小的样本翻译文件所预先标记的所采用翻译策略的概率构建模糊向量集,其中,所述模糊向量集中每个模糊向量包括:cpu占用率、内存使用率、文件大小、采用相应翻译策略的概率;
25、s203,针对所述模糊向量中的每个变量进行区域划分,得到相应的模糊集合;所述模糊集合包括每个变量的一个分区,且每个变量的相邻分区之间有重叠区域;进行区域划分时,采用非等距划分;
26、s205,将每个所述模糊向量映射到相应的模糊集合,得到相应的映射向量,并将所述映射向量输入初始模糊推理机,以构建所述文件大小、所述cpu占用率和所述内存占用率到相应翻译策略的概率的映射关系,得到所述翻译决策推理机。
27、在一些实施例中,将所述向量集中的每个向量映射到相应的模糊集合,得到相应的映射向量的步骤,具体包括:
28、根据所述向量中每个变量的实际值匹配到相应的分区;
29、若匹配到两个分区,计算所述实际值与两个分区各自的长度比,并将其中最大的所述长度比对应的分区作为所述变量的目标分区,以将所述模糊向量映射到相应的模糊集合;其中,所述长度比为所述实际值与每个分区中最近的端值之差值,和相应分区长度之比。
30、本发明的第二方面,在于提供一种基于多翻译线程的盲文翻译任务调度装置,其包括:
31、文件类型识别模块,用于接收多个客户端发送的翻译请求,并识别所述上传请求中所携带的待翻译文件的类型;所述待翻译文件的类型包括:长度大于或等于预设长度阈值的长文件,和长度小于预设长度阈值的短文件;
32、翻译策略决策模块,用于根据所述待翻译文件的类型配置相应的翻译模式;且当所述文件类型识别模块识别出所述待翻译文件为大文件,为其配置预约翻译模式;当所述文件类型识别模块识别出所述待翻译文件为小文件,为其配置即时翻译模式;
33、翻译线程管理模块,用于控制执行翻译任务的多个翻译线程的开启和终止;
34、翻译任务分发模块,用于将多个所述大文件和多个所述小文件平均分发至多个翻译线程的任务等待队列,并对所述待翻译文件进行优先级排序;以及当任一翻译线程每执行完一个翻译任务时,将其任务等待队列中的各翻译任务的优先级提高;其中,初始状态时,当同一翻译线程的所述任务等待队列中同时存在多个所述大文件和多个所述小文件时,所述小文件的优先级高于所述大文件的优先级,且多个所述小文件按照达到时间的先后顺序进行优先级排序。
35、在一些实施例中,所述翻译线程管理模块还用于周期性地获取系统资源和当前待处理翻译文件中小文件的数量,并输入预先构建的翻译线程管理模型,以得到当前需要同时开启的用于处理所述大文件的第一翻译线程目标总数;以及根据所述第一翻译线程目标总数动态调整当前的第一翻译线程数量,其中,所述系统资源包括:cpu占用率和内存使用率。
36、在一些实施例中,所述翻译任务分发模块还用于将翻译过程中新收到的待翻译文件存入对应翻译线程的任务暂存队列中。
37、在一些实施例中,所述翻译任务分发模块还用于当根据所述第一翻译线程目标总数动态调整当前第一翻译线程数量,使得任一第一翻译线程即将被终止时,将所述任一第一翻译线程当前正在执行的翻译任务及其任务等待队列中的所有翻译任务分配至其他正在运行的翻译线程中,且根据所述待翻译文件的大小平均分配;或者,当根据所述第一翻译线程目标总数动态调整当前第一翻译线程数量,使得至少一个新翻译线程被开启时,根据文件大小将当前正在执行翻译任务的翻译线程的任务等待队列中的翻译任务平均的分配到所述新翻译线程中。
38、在一些实施例中,所述翻译策略决策模块包括:
39、参数获取单元,用于获取所述待翻译文件的决策指标参数;所述决策指标参数包括:所述待翻译文件的大小,以及服务端的当前cpu占用率和当前内存占用率;
40、计算单元,用于根据所述决策指标参数和预先构建的翻译决策推理机计算得到所述待翻译文件采用相应翻译策略的概率p;所述翻译策略为即时翻译,或者预约翻译;
41、翻译策略单元,用于将计算得到的所述翻译策略的概率映射到第一区间[a1,a2],得到映射后的概率p’,并生成随机数r,然后将所述随机数r映射到所述第一区间[a1,a2],得到映射随机数r’,并判断所述映射随机数r’是否属于第二区间[a1,p’],若是,判定所述待翻译文件将采用相应的翻译策略,否则,判定所述待翻译文件将采用其他翻译策略。
42、有益效果:当采用多翻译线程并行的方式,并且,不同翻译任务对应的待翻译文件的长度不同,因此,各翻译线程的任务等待队列中各翻译任务的优先级排序,将严重影响系统运行效率。若单纯采用先来后到的顺序,即先来先服务模式,这会导致排在较长任务后面的用户体验不佳。另一方面,由于是基于概率的决策,因此有可能会有部分较短文件对应的翻译任务也配置了预约翻译模式,这就导致本来能快速完成的短文件由于长文件而耽搁,这延长了用户的平均等待时间。如果单纯采用短文件的翻译任务优先的模式,即越短的文件具有越高的优先级,这就会导致较长的文件可能一直无法执行,对于翻译长篇书籍的用户也不友好,使得用户体验降低。因此,本发明中,采用首先以短任务优先的方式确定任务初始优先级,越短的任务优先级越大,在等待队列中的排序也就越靠前,系统就会越快执行这些任务,减少了用户平均等待时长;同时在每执行完一个任务后,会将此时仍未执行的任务优先级提高,这样对于原本优先级低的长任务,经过一段时间后,其优先级会逐渐提高,在等待队列中的位置也会越来越靠前。
本文地址:https://www.jishuxx.com/zhuanli/20240822/280498.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表