基于置信度和变分自编码器蒸馏的联邦学习优化方法
- 国知局
- 2024-08-30 14:37:00
本发明属于跨数据中心分布式机器学习领域,适用于跨数据中心的协同计算场景,具体涉及基于置信度和变分自编码器蒸馏的联邦学习优化方法。
背景技术:
1、源于大数据的激增,机器学习取得了巨大的发展和成功,并广泛应用于公共智能设备和金融等领域。但在机器学习深入发展的同时,其广泛的应用也受到了大规模数据集缺乏的限制。一方面,高昂的数据收集和标注成本,使得单个组织难以收集足够充分的数据。另一方面,即使公司可能已经拥有足够数量的记录数据,它们仍然可能希望通过整合分布在其他机构的辅助特征来丰富其数据的特征空间。然而,机构之间共享数据或从用户设备汇总数据会导致隐私泄露的风险。尤其是在跨数据中心协同计算的场景下,由于不同数据中心数据不出域的特点,数据的共享传输和再处理更是难以满足,因此,如何有效利用分布在多个机构中的数据进行机器学习训练,并兼顾数据的隐私安全保护具有挑战性。联邦学习的方式由此得到广泛的研究和关注。
2、联邦学习与传统的分布式环境有很大不同,它基于分布在客户端的数据来训练机器学习模型。具体来说,在跨数据中心协同计算的场景中,选择一个数据中心作为服务器端,其他数据中心视为多个客户端,服务器需要在客户端不共享数据的情况下协同训练一个统一的适应性广泛的全局模型。在多个数据中心通过联邦学习挖掘数据特征的过程中,只需要交互梯度或模型参数等中间结果,以训练全局模型,无需传输原始数据。具体来说,在典型的联邦学习训练过程中,服务器从一组符合资格要求的客户端中采样,每个被选定的客户端从服务器下载当前模型权重,并基于自身设备的本地数据,在本地执行训练程序对模型进行计算更新。之后,参与当前轮次的客户端将本地的训练结果(诸如模型权重或梯度等中间结果)上传至服务器,服务器收集并聚合边缘设备的更新内容,最后对共享模型进行更新,得到一个具备更好泛化能力的全局模型。然后,新一轮的联邦训练从发布新版本全局模型开始。
3、然而,在跨数据中心协同计算的联邦学习系统中,各数据中心源于地域、业务场景和主要用户群体的差异,数据往往呈现类别标签倾斜、样本数量不均等非独立同分布的特点,这意味着各数据中心的本地模型训练会存在一定的偏好,不同数据中心的优化目标有着很大的不同,从而在协同训练的过程中造成客户端漂移和知识遗忘的现象,进一步导致聚合的全局模型精度下降以及模型训练收敛缓慢。针对联邦学习数据异构性问题的研究引起了国内外广泛学者的关注,大量的优化方案被提出。
4、现有的联邦学习异构性问题研究可以分为数据层面方法和算法层面方法。数据层面的数据异构解决方案旨在通过修正数据的不平衡性,从根本上缓解数据的非独立同分布特点,具体包括数据增强和客户端选择等方式。数据增强的方式可以将异质数据变得更加均质,但其部分方法需要客户端共享部分数据或具备额外的共享数据集,这在现实场景中往往是难以满足的,而对于无数据生成的方式则需要消耗大量的时间开销,且对数据的传输与分享会带来大量通信开销。客户端选择的方式虽然不会破坏客户端本地数据的分布,但基于一定准则进行挑选客户端的过程不可避免地带来了预处理等开销,且其未针对本地数据本身的异构特点进行处理,对于极端异构场景的适应性较差。此外,数据层面的方法在一定程度上忽略了对客户端本地异构数据信息的充分利用。
5、算法层面方法的方案旨在通过约束客户端本地训练过程来缓解经过异构数据训练后本地模型的漂移现象,包括正则化损失优化和蒸馏学习等方面。正则化损失优化可以有效缓解联邦学习客户端本地训练过程中的过拟合问题并且只对联邦学习过程进行了轻量化的修改,但其精度优化同样在一定程度上受限于算法的优化质量。蒸馏学习利用知识更全面的全局模型指导客户端本地模型的训练,从而缓解本地训练时对全局知识的遗忘,但其优化过程受到全局模型可靠性的影响,对全局模型不可靠知识的保留同样会影响模型的收敛和精度。此外,现有的许多方法不能有效利用不同客户端的标签分布信息,导致优化效果不理想。而这些信息至关重要,决定了标签异构的严重程度。
技术实现思路
1、针对联邦学习在数据异构环境下的客户端漂移导致的模型预测精度低的问题,提出了基于置信度和变分自编码器蒸馏的联邦学习优化方法。本发明主要分为两个部分:
2、第一部分,本发明提出了基于置信度蒸馏模块,以实现细粒度地区分和处理各类别样本的训练,使得客户端模型本地训练的过程中在保留全局知识和学习局部知识的冲突中找到一个好的平衡点。该模块首先引入模型置信度的概念和量化方法,利用模型(全局模型和客户端本地模型)在各类别数据样本上的分类器输出计算得到模型针对各类别的置信度水平;其次,在每一轮本地训练前,在得到全局模型和本地模型各类别置信度水平的基础上,计算得到置信度蒸馏的教师模型分布权重;然后在本地训练的过程中,针对具体的本地数据样本,利用教师模型分布权重修正全局模型概率分布,同时,根据具体数据样本的真实标签类别得到置信度蒸馏的学生模型分布权重,并利用其修正本地模型概率分布;最后,利用全局模型概率分布和本地模型概率分布定义置信度蒸馏项作为训练损失函数的一部分,并指导本地训练。
3、第二部分,本发明提出了基于变分自编码器的分类器校准和特征蒸馏模块,以更好地纠正模型的深层特征和分类器偏移。该模块首先在服务端收集各客户端模型对各标签类别的深层特征信息,并计算得到综合的各类别的深层特征向量的均值和方差,再利用高斯混合模型生成深层虚拟特征;其次,利用深层虚拟特征和类别标签的对应信息,对聚合的全局模型分类器层进行再训练,同时利用变分自编码器模型(variational autoencoder,vae)对上述深层虚拟特征和类别标签的对应信息进行归纳学习,并于下一轮次将vae模型解码器下发选中的客户端;再次,客户端模型在本地训练后,利用vae解码器生成各类别的深层虚拟特征,对本地模型的分类器层进行再训练;此外,考虑到上述操作对模型分类器层的额外修正,从而可以在客户端训练过程中对模型特征层的学习施加更多的关注,因此本发明利用全局模型和本地模型的特征层分布,定义特征蒸馏项作为训练损失函数的一部分,进一步指导本地训练。
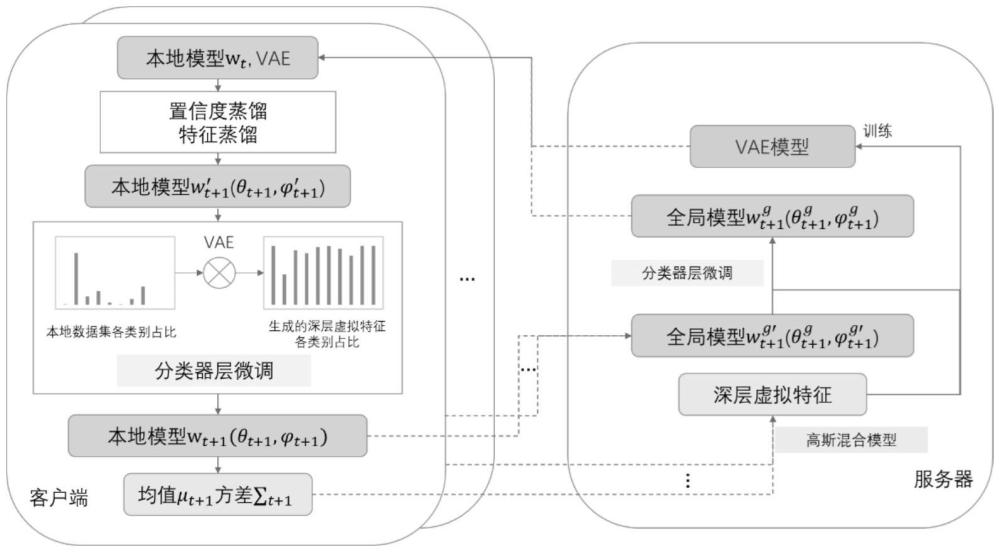
4、结合典型的联邦学习训练过程,基于置信度和变分自编码器蒸馏的联邦学习优化方法具体实现包括如下步骤,其中基于置信度蒸馏模块主要涉及步骤(2.1)至步骤(2.3),基于变分自编码器的分类器校准和特征蒸馏模块涉及步骤(2.4)、步骤(3)、步骤(5)和步骤(6):
5、步骤(1).在每一个通信轮次,服务端根据采样比率r在所有客户端集合k中随机采样r×|k|个客户端,构建客户端集合kt,t表示当前通信轮次数,被选中的客户端下载当前通信轮次的全局模型权重wt和全局vae模型。对于每一个客户端k∈kt,基于当前通信轮次全局模型权重wt初始化本地模型为
6、本发明中服务器的全局模型和客户端的本地模型具备相同的结构,对全局模型或本地模型可以分解为深层特征提取器fθ和分类器给定样本特征x,深层特征提取器fθ将其映射为向量f,分类器将f映射为向量z,进而对向量z进行概率计算得到分类预测,因而整体模型参数为
7、步骤(2).客户端接收到服务器下发内容后,基于客户端的本地数据,在客户端进行本地训练,计算更新本地模型。客户端的本地训练程序包含e次循环训练,每一次循环训练包含如下步骤。
8、步骤(2.1).客户端在本地数据集上计算得到各标签类别的全局模型的置信度水平βglobal和本地模型的置信度水平βlocal,并基于二者的差值计算得到置信度蒸馏的教师模型(全局模型)权重αt。其中,表示数据样本的特征集合,表示数据样本的标签集合。
9、步骤(2.2).针对每个本地数据集的具体数据样本根据其真实标签类别y得到置信度蒸馏的学生模型(本地模型)分布权重αs。其中,x表示该样本的特征,y表示该样本的真实标签类别。
10、步骤(2.3).构建置信度蒸馏损失项以实现细粒度地区分和处理各标签类别样本的训练,使得客户端本地模型在本地训练的过程中,于保留全局知识和学习本地知识的冲突中找到一个好的平衡点。
11、在本地训练的过程中,针对每个本地数据集的具体数据样本利用步骤(2.2)得到的学生模型分布权重αs,修正得到本地模型在该样本上的概率分布pk,利用步骤(2.1)得到的教师模型权重αt,修正得到全局模型在该样本上的概率分布pg。然后,利用修正后的全局模型概率分布pg和本地模型概率分布pk定义置信度蒸馏项作为训练损失函数的一部分,并指导本地训练,置信度蒸馏项公式如下:
12、
13、其中,pk(i|x)表示针对样本特征x的本地模型概率分布pk的第i类的输出,pg(i|x)表示针对样本特征x的全局模型概率分布pg的第i类的输出,c为总类别数。
14、步骤(2.4).构建特征蒸馏损失项以纠正本地模型的深层特征。
15、在本地训练的过程中,针对每个本地数据集的具体数据样本可以得到全局模型在该样本上的深层特征提取器输出fg和本地模型在该样本上的深层特征提取器输出fk。然后,利用fg和fk定义特征蒸馏项从而可以在客户端训练过程中对本地模型特征层的学习施加更多的关注,激发后续阶段的分类器层微调的效果。特征蒸馏项公式如下:
16、
17、其中,mse表示均方误差。
18、步骤(2.5).构建本地模型训练的总损失函数本地模型训练的总损失函数由步骤(2.3)提出的置信度蒸馏损失项步骤(2.4)提出的特征蒸馏损失项和传统联邦训练交叉熵损失项共同组成。客户端本地模型依据总损失函数在本地数据集dk上最小化训练损失,从而优化联邦学习中客户端的本地训练过程。本地模型训练的总损失函数计算公式为:
19、
20、其中,1y(c)在标签类别c与样本真实标签类别y一致时值为1,否则为0。
21、步骤(3).客户端利用下载的vae模型生成各标签类别的虚拟特征,并使用虚拟特征和类别标签的对应信息微调本地模型的分类器层,进一步优化上述步骤训练得到的本地模型。之后,统计并上传本地模型在本地数据集上的各标签类别的深层特征信息(深层特征均值和方差等)至服务器。同时,上传客户端本地模型至服务器。
22、步骤(3.1).经过步骤(2)后客户端的本地模型更新为本发明让客户端利用从服务器下载的vae模型,生成各标签类别的虚拟特征集合并使用虚拟特征和类别标签的对应信息再训练本地模型,微调本地模型的分类器层权重进一步优化步骤(2)训练得到的本地模型。
23、步骤(3.2)经过步骤(3.1)的本地模型微调后,客户端的本地模型更新为为统计更新后的本地模型在本地数据集上的深层虚拟特征信息,针对每个本地数据集的具体数据样本客户端本地模型的深层特征提取器fθ将样本特征x映射为向量f,其对应的标签类别为y。然后,客户端统计本地模型在本地数据集上的所有深层特征提取器输出向量,得到各个标签类别的特征向量的均值和协方差等深层特征信息,并将其上传至服务器。同时,客户端上传本地模型至服务器。客户端k各标签类别的深层特征向量的均值和协方差的计算方式如下:
24、
25、
26、其中表示客户端k的本地数据集中包含的c标签类别的样本数量,表示客户端k的本地模型针对第j个c标签类别样本在c维度的深层特征提取器输出向量。
27、步骤(4).服务器在接收到各客户端的本地模型后,聚合得到全局模型。服务器接收到各客户端上传的本地模型后,对各本地模型权重进行聚合更新,得到新的全局模型。全局模型权重w′t+1聚合公式为:
28、
29、其中,为被选中的第k个客户端上传的本地模型权重,|dk|表示被选中的第k个客户端本地数据集大小。
30、步骤(5).服务器微调全局模型。服务器接收到各客户端上传的本地模型的各标签类别的特征信息后,计算得到综合的各标签类别的特征向量的均值μc和方差∑c,并利用均值μc和方差∑c经由高斯混合模型生成各标签类别的虚拟特征集合之后使用深层虚拟特征和类别标签的对应信息再训练全局模型,微调全局模型的分类器层权重进一步优化步骤(4)聚合得到的全局模型,得到新的全局模型wt+1。对全局模型的分类器层这一深层结构进行再训练,能够纠正和改善全局模型的分类预测效果。综合的各标签类别的深层特征向量的均值μc和方差∑c计算公式如下:
31、
32、其中,nc表示该通信轮次被选中的所有客户端的本地数据集中包含的c标签类别的样本数量。
33、步骤(6).服务器训练vae模型。服务器使用步骤(5)中生成的虚拟特征集合和类别标签的对应信息训练全局vae模型,使得全局vae模型能够更好地归纳学习深层虚拟特征和类别标签的关系知识,进而能够生成类别标签对应的更逼真的深层虚拟特征,以便后续下发给客户端使用。
34、本发明有益效果:
35、本发明提出的联邦学习优化方法由基于置信度蒸馏模块和基于变分自编码器的分类器校准和特征蒸馏模块两部分构成。
36、(1)基于置信度蒸馏模块通过提出和量化模型置信度的概念,对比全局模型和本地模型的置信度水平差异,更细粒度地区分和处理各类别样本的训练,使得客户端模型尽量保留全局模型中置信度较高的类别知识信息,同时从本地数据中学习本地模型置信度较高的类别知识信息,从而在保留全局知识和学习局部知识的冲突中找到一个好的平衡点。这有效优化本地模型的训练过程,缓解客户端漂移问题,可以在不损害隐私的同时不增加通信负担,有效提高了模型的预测精度。
37、(2)基于变分自编码器的分类器校准和特征蒸馏模块通过引入变分自编码器对深层特征信息进行归纳学习,通过特征蒸馏和模型分类器微调纠正模型深层特征和分类器偏移,进一步提高了全局模型预测的准确性。
本文地址:https://www.jishuxx.com/zhuanli/20240830/283033.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表