肺部CT图像弱监督多实例学习的生物标志物的识别方法
- 国知局
- 2024-09-05 14:29:21
本发明属于医学图像处理和计算机视觉领域,涉及利用深度学习神经网络框架,对计算机断层扫描(computed tomography,ct)图像进行识别,具体涉及到肺部ct图像弱监督多实例学习的生物标志物的识别方法。
背景技术:
1、目前,在肺癌的各类治疗手段中,免疫疗法作为一种新兴的治疗手段引起人们的了广泛关注。然而,免疫治疗方案的制定需要通过复杂的生物标志物免疫组化染色检查,十分费时费力。因此,急需一种高效、精准、无创的生物标志物的识别方式。近年来,随着胸部ct图像的计算机辅助诊断(computer aided diagnosis,cad)系统以及深度学习等相关技术的发展。一些深度学习算法已经开始应用于肺部图像的疾病诊断任务。我们观察到,ct图像可以从宏观层面反映出肺部肿瘤的形态信息以及肿瘤所在的微环境信息,因此通过对ct图像的分析来对肿瘤的生物标志物表达水平进行分析是可行的。但是目前针对生物标志物的识别的相关研究较少。受到弱监督的多实例学习(multiple instance learning,mil)算法已经在病理图像方面广泛应用的启发,该类算法能够通过利用整张图像级的弱标签,实现对目标数据的拟合而无需对病灶区域进行标注。我们认为,利用该种方法直接利用ct级别标注信息来识别生物标志物表达水平也是可行的,进而省略精确标注的步骤。
2、目前,大多数的mil方法都专注于基于2d病理图像的分类研究。虽然可以直接利用这些方法,通过采用横向ct切片作为单个实例定义来直接识别生物标志物表达水平,但发现这种方式缺乏ct图像中轴向方向的信息会影响识别性能。同时,也有一些将小的3d立方体作为3d医学图像实例的mil方法,这需要一个3d特征编码器来从3d实例中提取特征,显著增加了训练参数的数量和网络训练的难度。因此,有必要设计一种适用于3d图像的mil方法。此外,大多数现有的mil方法研究的是包级融合,并依赖于包级监督来驱动训练,而忽视了代表性实例的选择。在任务中,由于与生物标志物识别方面相关的视觉线索较弱,仅仅使用包级监督很难学习到与生物标志物相关的有效信息,需要有一种合理的策略来选择代表性实例来指导训练。
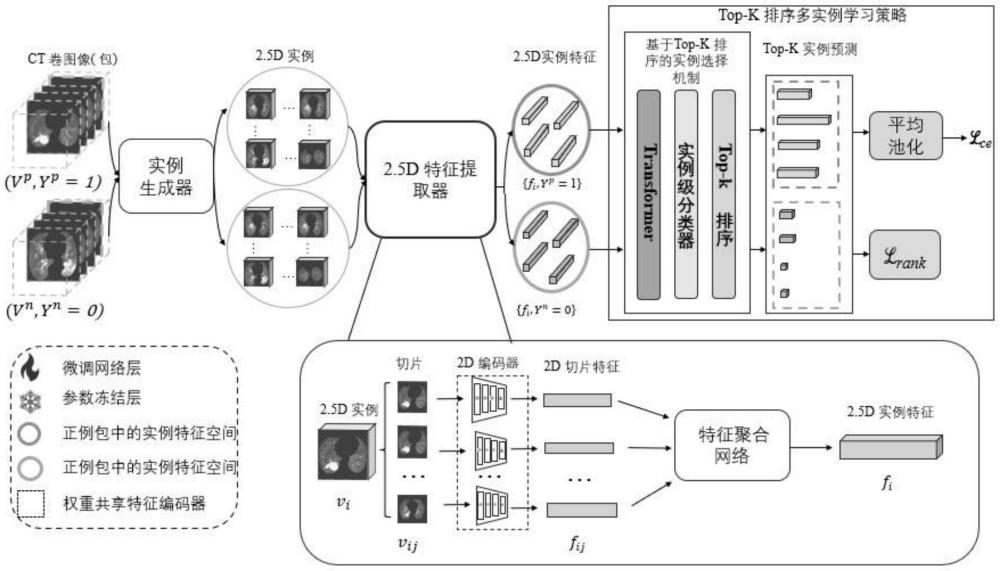
3、为了解决上述这些问题,本发明提出了一种2.5d top-k排名的mil方法。具体来说,为了解决3d图像的特征提取问题,设计了一个2.5d实例特征提取器,将轴向方向上的几个连续横向ct切片视为一个实例而非单个ct切片。除此之外,为了帮助模型更加聚焦于关键实例的识别,而非基于整个包级别的整体信息,额外地引入了一种基于top-k排名的多实例学习策略来更加精准的进行识别。
技术实现思路
1、为了克服现有方法对三维ct数据泛化性能的不足以及对异常实例识别关注度不足的缺点,本发明提出了一种基于2.5d实例选择弱监督多实例学习的生物标志物ct影像识别方法。首先,需要先根据前文定义的每个微小ct卷的实例定义。考虑到在要解决的问题中,标注数据较少,因此需要通过一定的方式对输入数据进行增强以扩充训练数据量。由于考虑到本发明中神经网络的输入是单个ct切片的图像特征,传统的针对与图像的随机数据增强方式不能直接引入本工作中,为此,设计了一种针对与本任务的特殊的数据增强方式:在每次将图像送入网络训练前,针对一个ct图像中的切片特征,先通过平均采样的方式获取每个实例的中心切片,在通过设置迁移量,让输入特征在一定范围内进行随机迁移,获得2.5d实例。然后,利用一个在大规模自然图像数据集预训练的神经网络来逐层地提取每个ct切片的特征信息,并通过一个2.5d实例特征生成模块通过切片特征聚合生成单个2.5d的实例特征。最后,引入一个基于实例选择的实例挑选机制以及实例损失函数帮助网络聚焦于显著实例的筛选,提升识别模型的精度。
2、本发明的具体技术方案为:
3、肺部ct图像弱监督多实例学习的生物标志物的识别方法,包括如下步骤:
4、1)收集初始数据:对于生物标志物的识别任务,收集的初始数据包括:所要识别的肺部ct图像以及每一例图像的对应生物标志物表达水平标注。
5、2)数据预处理:将步骤1)中的ct图像数据使用自动化的肺部分割方式对肺部组织进行分割,排除肺外组织的干扰,以便后续网络的训练和测试。
6、3)多实例学习获得实例特征:
7、3-1)多实例学习:利用多实例学习框架来解决此任务,在多实例学习框架中,一个图像被视为包含多个实例(instance)的包(bag)。其中包级别的标签是由实例级别的标签所决定的:若一个包中包含至少一个特殊实例,则该包被标注为特殊包,反之,若一个包中没有特殊实例,则该包为普通包。而在训练过程中,模型仅能获取包标注,而实例级别标注未知。在本方法中,将包含多张切片的ct图像视作一个包,每个包中包含多个2.5d实例,判别生物标志物的信息特征存在于包中的某个实例之中,并利用多实例学习的方式学习这种潜在的映射关系。
8、3-2)对单个2.5d实例进行定义:首先需要对2.5d实例进行定义,由于单个ct图像中的实例不应该仅限于单个ct切片,应该考虑到ct图像的三维信息,因此将单个实例设定为多个切片之间的组合,即:一个实例是一个包含多张ct切片的微小ct图像。选取每个实例的中心切片,并以该切片为中心,向外扩张数个ct切片,将这些切片视为一组,作为单个2.5d实例。
9、3-3)使用一个已经在大规模数据集(imagenet(deng j,dong w,socher r,etal.imagenet:alarge-scale hierarchical image database[c]//2009ieee conferenceon computer vision and pattern recognition.ieee,2009:248-255.))中预训练过的特征提取网络,(如resnet等,he k,zhang x,ren s,et al.deep residual learning forimage recognition[c]//proceedings of the ieee conference on computer visionand pattern recognition.2016:770-778.)对步骤3-2)中定义的2.5d实例中的单层ct图像进行特征提取,得到每一个ct切片的图像特征。此外,由于特征提取网络是在自然图像训练的,与本发明要解决的问题有差异,因此,需要在特征提取网络之后,引入一个小型的残差模块,该模块能够对特征提取网络输出的特征进行微调,以弥补不同模态图像之间的域差异。
10、3-4)在得到ct切片的图像特征之后,通过一个门控注意力模块,对单个2.5d实例中不同切片特征的注意力加权聚合,为每个2.5d实例生成实例特征。
11、门控注意力的聚合方式具体实现如下公式所示:
12、
13、
14、式中,i代表每个ct图像中的2.5d实例,j代表每个实例中的切片数,aj代表单个实例中不同切片对该2.5d实例特征的贡献程度,其值的计算由门控注意力机制生成。式中w、u和v均为可训练的网络参数,sigmoid函数为门控函数,控制每个切片的特征eij是否能够对实例特征产生贡献。此外,考虑到在每个切片的特征层面上也可能不同的判别特征,因此使用tanh作为激活函数,负责计算每个切片特征eij对实例特征贡献的正负以及大小。而eij代表通过特征微调提取的单个切片特征。通过该式可以获得聚合了多个切片特征的2.5d实例特征fi。
15、4)基于实例排序挑选的多实例学习:
16、4-1)构建基于top-k排序的多实例学习网络:
17、为了捕获ct图像的整体信息,本方法先使用一个transformer模型来对2.5d实例信息进行丰富,具体来说,在步骤3-2)对2.5d ct图像定义的过程中,单个2.5d ct图像只整合了前后数个切片的切片信息。为了建模ct图像的三维信息,使用一个transformer模块来对单个ct图像中的不同实例之间的互信息进行建模,该模块通过自注意力的方式对全局信息进行建模,而非局限于局部信息,以充分发掘ct图像的整体信息。
18、然后选用一个分类网络对每个ct图像中多个实例(2.5d ct图像块)进行回归分类,区分每个实例是否包含高生物标志物表达的信息。接下来,将生物标志物表达水平不同的ct图像中的2.5d实例,根据模型的预测概率进行top-k排序,选择出每个包中生物标志物表达水平最高的实例作为关键实例。然后通过交叉熵损失以及基于排序的多实例损失来训练网络,网络优化方法为指数平均梯度下降,通过这种方法,网络能够学习到不同实例的分布,得到训练好的实例级别的多实例学习网络。
19、4-2)将步骤3)中得到的2.5d实例特征,根据其所属ct图像生物标志物表达水平的不同,以两两一组送入步骤4-1)的基于top-k排序的多实例学习网络中,训练网络模型。
20、4-3)通过多个损失来监督网络的学习过程:
21、基于排序的多实例损失函数如下:
22、将两张输入的ct图像,根据其标签的不同,分别表示为vp和vn,分别代表不同标签的ct图像,对于正样本ct图像中,正例包的选定的前k个实例表示为ωp,取预测为正例概率最高的前k个实例构建集合对于负样本ct图像中,定义负例包的选定的前k个实例表示为ωn,取预测为正例概率最高的前k个实例构建集合根据多实例学习的范式,可以知道:正样本中一定包含至少一个正样本实例,而负样本中一定不会包含正样本实例,基于这一点,设计一个基于排序的多实例学习损失公式如下:
23、
24、式中,引入了一个归一化损失来防止模型对高生物标志物表达图像中实例过拟合,α是一个超参数,用于控制稀疏约束项的权重。归一化损失的具体公式为:
25、
26、网络训练的总损失是由排序损失和交叉熵损失加权得到,总损失函数如下:
27、
28、式中,β是一个用于调整损失权重的超参数,为标准交叉熵损失;
29、5)推理过程:
30、经过步骤4)的训练过程后,将将网络的参数进行冻结,可以利用基于top-k排序的多实例学习网络来对单张ct图像进行肺部生物标志物的识别,具体的识别推理过程如下:
31、5-1)将待检测的ct图像按照步骤3-2)划分成不同的2.5d实例后,送入步骤3-3)中的特征提取网络提取ct切片特征。在得到ct图像的切片特征后,将切片特征送入步骤3-4)的门控注意力模块中,得到2.5d ct图像块实例特征。
32、5-2)将实例特征送入训练后的基于top-k排序的多实例学习网络中,检测每个实例包含高生物标志物表达区域的概率。
33、5-3)根据图像中每个实例的预测概率进行排序,选择概率最大的k个实例,并将其预测结果进行平均化处理,作为最终的ct图像识别结果。
34、本发明的有益效果是:
35、本发明基于深度神经网络,将多实例学习框架应用于ct图像上的生物标志物识别工作,通过利用门控注意力机制将2d图像特征聚合为2.5d实例特征,在不引入过多额外参数的情况下,提升了网络对于3d图像的泛化能力。同时,设计了一个基于2.5d实例排序的多实例学习方法,使网络更加聚焦于训练图像中的关键实例,而非图像整体信息。解决了生物标志物识别困难、mil方法在ct图像上泛化性能低等关键问题。本发明具有以下特点:
36、1、所使用的数据易于收集,符合临床筛查数据的特点,仅需要ct检查图像即可,无需复杂的免疫组化检查,且识别准确性良好;
37、2、通过对已经在大规模数据集中预训练的特征提取网络进行微调,本发明在不引入过多额外网络参数的情况下,实现了模型能力的迁移。此外,通过设计一个基于门控注意力方式来实现从2d特征到2.5d特征的迁移,使其更加适合医疗影像中的三维数据特征;
38、3、设计了一个基于排序的多实例学习损失,使网络更加聚焦于关键实例的识别,而非整体图像的信息,提升识别精度;
39、4、在生物标志物的识别任务上的表现明显优于其他异常检测方法,且训练和测试运行速度较快,有助于新方法的改进迭代。
本文地址:https://www.jishuxx.com/zhuanli/20240905/286728.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。
下一篇
返回列表