基于逆强化学习的多模态场景驾驶行为建模方法及系统与流程
- 国知局
- 2024-09-05 14:39:45
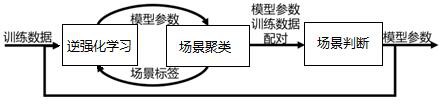
本发明涉及智能驾驶,具体涉及基于逆强化学习的多模态场景驾驶行为建模方法及系统。
背景技术:
1、无人驾驶,是指让汽车自身拥有环境感知、路径规划并自主实现车辆控制的技术。目前,无人驾驶车辆的需求在于能够准确模拟人工驾驶行为以适应混编环境。
2、当前,对于无人驾驶车辆的智能驾驶通常采用匀速模型或者智能驾驶模型,匀速模型(如经典的匀速跟随模型)和智能驾驶模型(如智能驾驶模型,idm - intelligentdriver model)是用于模拟车辆在不同交通条件下的行为的数学模型。然而,这些模型往往基于简化的假设,可能无法完全捕捉到人类驾驶员在复杂交通环境中的决策过程和行为意图。
3、目前,存在将逆强化学习应用于智能驾驶中,逆强化学习(irl)是一种机器学习方法,它试图从观察到的行为中推断出决策者的目标或偏好。在智能驾驶领域,irl可以用来从人类驾驶员的行为中学习驾驶策略。但是目前将逆强化学习应用于智能驾驶中的建模算法线性奖励函数特征近似,其无法充分表达复杂的驾驶场景和人类驾驶员的偏好,在实际驾驶中,奖励函数可能需要考虑多种因素,而这些因素往往是非线性的。在没有足够的先验知识的情况下,irl算法可能难以从非线性奖励函数中学习到有效的驾驶策略。
4、驾驶行为可能在不同的驾驶场景和驾驶员之间表现出多样性(即多模态性)。现有的irl算法可能难以适应这种多样性,导致学习到的策略在不同场景下的泛化能力受限。在一个特定场景下学习到的控制参数可能无法直接应用于其他场景,这限制了模型的鲁棒性和实用性。
5、因此,目前将逆强化学习应用于智能驾驶中的驾驶行为建模方法由于受到线性奖励函数的限制,无法适应复杂的混编交互场景。
技术实现思路
1、基于上述背景技术所提出的问题,本发明的目的在于提供基于逆强化学习的多模态场景驾驶行为建模方法及系统,解决了目前将逆强化学习应用于智能驾驶中的驾驶行为建模方法由于受到线性奖励函数的限制,无法适应复杂的混编交互场景的问题。
2、本发明通过下述技术方案实现:
3、本发明第一方面提供了基于逆强化学习的多模态场景驾驶行为建模方法,包括如下步骤:
4、步骤s1、建立逆强化学习-场景聚类模型,将专家轨迹作为训练数据输入至所述逆强化学习-场景聚类模型中进行循环训练,得到模型参数-训练数据配对数据;
5、步骤s2、构建全局代价函数,利用所述模型参数-训练数据配对数据对所述全局代价函数进行优化;
6、步骤s3、利用优化后的全局代价函数进行场景判断,得到驾驶场景,并输出所述驾驶场景对应的模型参数。
7、在上述技术方案中,通过构建逆强化学习-场景聚类模型,以专家轨迹作为训练数据通过逆强化学习从专家轨迹中推力得到奖励函数,进而通过奖励函数从采样轨迹中找到专家轨迹的最佳代理,将该最佳代理作为模型参数,基于该模型参数进行场景聚类,即可以实现在匹配的驾驶轨迹的状态下,寻找该驾驶轨迹状态下所对应的驾驶场景,并将其进行聚合,将驾驶轨迹与驾驶场景进行匹配,得到模型参数-训练数据配对数据。
8、在现有的逆强化学习模型,是直接对逆强化学习模型得到的模型参数及特征权重向量对优化代价函数进行训练,这就导致了其忽略了驾驶行为不同驾驶场景下所表现出来的多模态性。而在本方法中,将模型参数与训练数据进行匹配,将匹配后的模型参数-训练数据配对数据对全局代价函数进行优化,其核心的目的在于输出相应场景的控制参数时能尽可能地模仿专家的驾驶习惯。完成对全局代价函数的训练后,对任意初始状态都可以输出特征权重向量,根据特征权重向量即可从该初始状态对应的采样轨迹中选出奖励最大的轨迹,该轨迹满足驾驶行为不同驾驶场景下所表现出来的多模态性。
9、在一种可选的实施例中,所述步骤s1中将专家轨迹作为训练数据输入至所述逆强化学习-场景聚类模型中进行循环训练包括如下步骤:
10、根据所述专家轨迹的初始状态,生成专家轨迹对应的采样轨迹;
11、通过特征函数将所述专家轨迹和所述采样轨迹映射至特征空间中,得到采样特征;
12、利用最大熵求解法对所述采样特征进行求解,得到模型参数;
13、基于所述模型参数进行场景聚类,得到驾驶场景下的专家轨迹;
14、将所述模型参数与驾驶场景下的专家轨迹进行配对生成模型参数-训练数据配对数据。
15、在一种可选的实施例中,根据所述专家轨迹的初始状态,生成专家轨迹对应的采样轨迹包括如下步骤:
16、获取在复杂交互环境下时刻的轨迹状态,将时间长度的轨迹状态进行整合生成第个专家轨迹,其中,为第个专家轨迹的初始状态;
17、根据所述初始状态,生成第个专家轨迹的采样轨迹,其中,为采样轨迹的总数,并将第个专家轨迹和采样轨迹的集合记为。
18、在一种可选的实施例中,利用最大熵求解法对所述采样特征进行求解包括:
19、以第个专家轨迹的采样轨迹构建目标函数;
20、利用最大熵求解法对所述目标函数进行求解,得到第个专家轨迹对应的特征权重向量;
21、其中,所述目标函数构建如下:
22、;
23、;
24、;
25、上式中,表示特征函数,表示第个专家轨迹的第个采样轨迹的采样特征,表示特征向量的长度,表示第个专家轨迹对应的特征权重向量。
26、在一种可选的实施例中,基于所述模型参数进行场景聚类包括如下步骤:
27、根据专家轨迹对应的特征权重向量采用聚类算法对专家轨迹进行分类,将具有相同标签的专家轨迹分类至同一集合中,得到场景轨迹集合;
28、利用最大熵求解法对场景轨迹集合中的数据进行求解,得到场景轨迹集合对应的特征权重向量;
29、将场景轨迹集合对应的特征权重向量与场景轨迹集合对应的特征权重向量对应的场景集合进行匹配,得到模型参数-训练数据配对数据。
30、在一种可选的实施例中,利用所述模型参数-训练数据配对数据对所述全局代价函数进行优化包括:将场景轨迹集合中每条专家轨迹的初始状态作为所述全局代价函数的输入数据,场景轨迹集合对应的特征权重向量作为所述全局代价函数的标签。
31、在一种可选的实施例中,所述全局代价函数包括损失函数,其中,所述损失函数表示如下:
32、;
33、其中,表示损失函数,表示交叉熵函数,表示对场景轨迹集合中第个数据预测的特征权重向量,表示第个场景轨迹集合对应的特征权重向量。
34、本发明第二方面提供了基于逆强化学习的多模态场景驾驶行为建模系统,包括:
35、配对模块,所述配对模块用于建立逆强化学习-场景聚类模型,将专家轨迹作为训练数据输入至所述逆强化学习-场景聚类模型中进行循环训练,得到模型参数-训练数据配对数据;
36、函数优化模块,所述函数优化模块用于构建全局代价函数,利用所述模型参数-训练数据配对数据对所述全局代价函数进行优化;
37、输出模块,所述输出模块用于利用优化后的全局代价函数进行场景判断,得到驾驶场景,并输出所述驾驶场景对应的模型参数。
38、在一种可选的实施例中,所述配对模块包括:
39、采样子模块,所述采样子模块用于根据所述专家轨迹的初始状态,生成专家轨迹对应的采样轨迹;
40、映射子模块,所述映射子模块用于通过特征函数将所述专家轨迹和所述采样轨迹映射至特征空间中,得到采样特征;
41、求解子模块,所述求解子模块用于利用最大熵求解法对所述采样特征进行求解,得到模型参数;
42、聚类子模块,所述聚类子模块用于基于所述模型参数进行场景聚类,得到驾驶场景下的专家轨迹;
43、场景配对子模块,所述场景配对子模块用于将所述模型参数与驾驶场景下的专家轨迹进行配对生成模型参数-训练数据配对数据。
44、在一种可选的实施例中,所述聚类子模块包括:
45、分类单元,所述分类单元用于根据专家轨迹对应的特征权重向量采用聚类算法对专家轨迹进行分类,将具有相同标签的专家轨迹分类至同一集合中,得到场景轨迹集合;
46、权重单元,所述权重单元用于利用最大熵求解法对场景轨迹集合中的数据进行求解,得到场景轨迹集合对应的特征权重向量;
47、配对单元,所述配对单元用于将场景轨迹集合对应的特征权重向量与场景轨迹集合对应的特征权重向量对应的场景集合进行匹配,得到模型参数-训练数据配对数据。
48、本发明与现有技术相比,具有如下的优点和有益效果:
49、通过本发明可以有效自监督地挖掘大规模驾驶轨迹数据集里的多个模态,并通过特有的交互特征集合对策略进行提取,最终输出一个鲁棒的全局代价函数和多模态场景自适应驾驶策略。使用“模型参数-训练数据”配对训练全局代价函数,使其能根据车辆的状态判断其对应的场景并输出对应的模型参数。
本文地址:https://www.jishuxx.com/zhuanli/20240905/287539.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。