一种基于上下文感知的文档级关系抽取方法
- 国知局
- 2024-09-05 14:52:03
本发明涉及自然语言处理领域,尤其涉及一种基于上下文感知的文档级关系抽取方法。
背景技术:
1、一篇文档由多个句子组成,每个句子中又对应着多个单词,一个单词或多个单词对应着一个实体节点,任意两个实体节点构成了一个实体对,而文档级关系抽取正是为了提取文档中的实体对之间的上下文关系。
2、目前,为了解决文档级关系抽取,基于图的模型是当前文档级关系抽取的主流方法之一,该类方法虽然能有效解决实体节点之间的长距离依赖问题,但是由于在构造实体节点时往往未充分考虑句子上下文、文档主题、实体对距离、实体对相似度等额外信息,从而导致关系抽取的准确率较低。
技术实现思路
1、本发明的目的是提供一种基于上下文感知的文档级关系抽取方法,能够准确地进行文档级关系抽取,实现实体对之间准确的关系预测。
2、本发明采用下述技术方案:
3、一种基于上下文感知的文档级关系抽取方法,依次包括以下步骤:
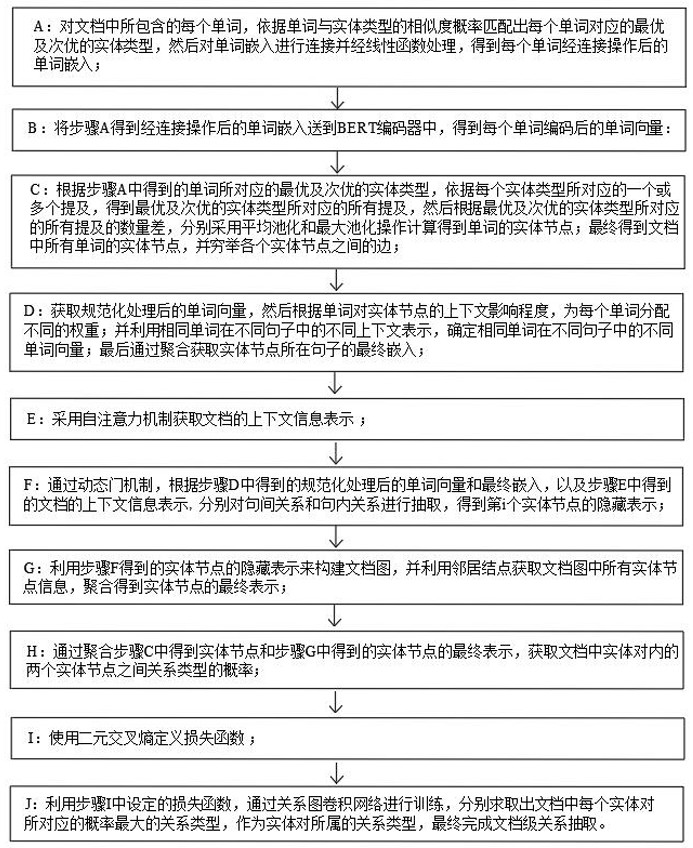
4、a:对文档中所包含的每个单词,依据单词与实体类型的相似度概率匹配出每个单词对应的最优及次优的实体类型,然后对单词嵌入进行连接并经线性函数处理,得到每个单词经连接操作后的单词嵌入xj;
5、b:将步骤a得到经连接操作后的单词嵌入xj送到bert编码器中,得到每个单词编码后的单词向量:
6、c:根据步骤a中得到的单词所对应的最优及次优的实体类型,依据每个实体类型所对应的一个或多个提及,得到最优及次优的实体类型所对应的所有提及,然后根据最优及次优的实体类型所对应的所有提及的数量差,分别采用平均池化和最大池化操作计算得到单词的实体节点;最终得到文档中所有单词的实体节点,并穷举各个实体节点之间的边;
7、d:获取规范化处理后的单词向量,然后根据单词对实体节点的上下文影响程度,为每个单词分配不同的权重;并利用相同单词在不同句子中的不同上下文表示,确定相同单词在不同句子中的不同单词向量;最后通过聚合获取实体节点所在句子的最终嵌入si;
8、e:采用自注意力机制获取文档的上下文信息表示c;
9、f:通过动态门机制,根据步骤d中得到的规范化处理后的单词向量和最终嵌入si,以及步骤e中得到的文档的上下文信息表示c,分别对句间关系和句内关系进行抽取,得到第i个实体节点的隐藏表示;
10、g:利用步骤f得到的实体节点的隐藏表示来构建文档图,并利用邻居结点获取文档图中所有实体节点信息,聚合得到实体节点的最终表示;
11、h:通过聚合步骤c中得到实体节点和步骤g中得到的实体节点的最终表示,获取文档中实体对内的两个实体节点之间关系类型的概率;
12、i:使用二元交叉熵定义损失函数:
13、j:利用步骤i中设定的损失函数,通过关系图卷积网络进行训练,分别求取出文档中每个实体对所对应的概率最大的关系类型,作为实体对所属的关系类型,最终完成文档级关系抽取。
14、所述的步骤a中,设文档d中共包含有n个句子,即文档sz表示第z个句子;文档d中共包含有k个单词,整个文档最终由单词表示为:d={w1,w2,...wk};单词与实体类型的相似度概率的计算公式如下:
15、(rank1,rank2)=rank(sigmoid(cos(g(sz),g(wj))·cos(g(tj),g(wj))));
16、其中,rank1表示最大概率,rank2表示次大概率,rank(·)是返回概率从大到小排序的函数,sigmoid(·)为将输出的数值压缩到0到1之间的函数,cos(·)为余弦相似度的计算函数,g(sz)为第z个句子的嵌入,g(wj)为单词wj的嵌入,g(tj)为单词wj所对应的实体类型嵌入;
17、在对单词嵌入进行连接,然后通过线性函数得到经连接操作后单词嵌入xj时:
18、xj=w1·[g(wj);g(trank1);g(trank2)]+b1;
19、其中,g(trank1)和g(trank2)分别表示与单词wj相似度概率最大的两个实体类型嵌入,w1和b1分别是第一可训练权重参数和第一可训练偏置参数,[;]表示嵌入的拼接操作。
20、所述的步骤b中,编码后的单词向量hj为:
21、[h1,h2,h3,....,hj]=bert([x1,x2,x3,....,xj]);
22、其中,hj为单词wj编码后的单词向量。
23、所述的步骤c中,在采用不同的池化操作计算得到单词的实体节点ei时,采用下述公式:
24、
25、其中,mp是实体节点所对应的提及,是由所有实体节点对应的提及所构成的提及集合,q是概率差阈值;
26、所述的步骤d包括以下具体步骤:
27、d1:使用tanh函数,将每个单词的单词向量规范化至[-1,1]之间;
28、
29、其中,表示第i个实体节点所在句子si中第j个单词规范化后的单词向量,w2和b2分别是第二可训练权重参数和第二可训练偏置参数;
30、设第i个实体节点所在的句子si由j个单词组成,利用bert编码器将句子si表示为其中,表示第i个实体节点所在句子si中第j个单词的单词向量;
31、d2:通过互注意力机制,根据实体节点所在句子中的各个单词对实体节点的上下文影响程度大小,为每个单词分配不同的权重,对实体节点的上下文影响程度越大的单词权重越高;
32、
33、其中,表示第i个实体节点所在句子si中第j个单词的权重;
34、d3:根据相同的单词在不同句子中的不同上下文表示,通过设置第三可训练权重参数w3,确定相同的单词在不同句子中不同的单词向量;
35、d4:根据得到的句子中每个单词不同的权重,以及句子中每个单词的单词向量,通过聚合得到实体节点所在句子的最终嵌入si;
36、
37、所述的步骤e中,采用自注意力机制获取文档的上下文信息表示c为:
38、
39、其中,dk表示k矩阵的列数,即向量维度,kt表示k矩阵的转置,k和v分别为文档转化而来的键矩阵和值矩阵。
40、所述的步骤f中:
41、在进行句间关系抽取时,使用下述公式得到第i个实体节点的隐藏表示:
42、
43、进行句内关系抽取时,使用下述公式得到第i个实体节点的隐藏表示:
44、
45、其中,w4、w5、b4和b5是分别为第四可训练权重参数、第五可训练权重参数、第四可训练偏置参数和第五可训练偏置参数,是逐元素相乘操作。
46、所述的步骤g中:
47、假定在第l层,是第i个实体节点ui的隐藏表示,是第i个实体节点的邻居节点集合,是邻居节点集合中任意一个实体节点的隐藏表示,则第l+1层的第i个实体节点的隐藏表示为:
48、
49、其中,σ是激活函数,w6和w7分别是第六可训练权重参数和第七可训练权重参数;实体节点最终表示为:
50、
51、其中,是实体节点ui在第y层的隐藏表示,是实体节点ui在第0层的隐藏表示,是实体节点的邻居节点个数。
52、所述的步骤h中,文档中实体对内的两个实体节点之间关系类型的概率为,
53、p(r|ei,ej)=sigmoid([ei;ei]τw8[ej;ej]+b6);
54、其中,p(r|ei,ej)表示实体对(ei,ej)在给定关系类型的概率,w8和b6分别为第八可训练权重参数和第六可训练偏置参数。
55、所述的步骤i中,损失函数为:
56、
57、其中,是关系类型集合,是指示函数,r表示实体关系预测的概率。
58、本发明基于文档图及图卷积网络,在构造实体节点时充分考虑句子上下文、文档主题、实体对距离、实体对相似度等额外信息,从而实现实体对之间准确的关系预测,能够准确地进行文档级关系抽取。
59、首先,本发明在得到的单词与实体类型的相似度概率中,选取最大概率及次大概率所对应的实体类型,作为单词对应的最优及次优的实体类型,并首先通过对单词嵌入进行连接,然后再通过线性函数得到经连接操作后单词嵌入,以准确构造经连接操作后的单词嵌入。
60、其次,本发明根据最优及次优的实体类型所对应的所有提及的数量差,分别采用平均池化和最大池化操作计算得到单词的实体节点;最终准确构建文档中所有单词的实体节点,为增强图推理能力奠定基础。
61、再次,本发明充分考虑到每个单词受上下文影响,全方位关注所有单词在不同上下文语境下的感知情况,通过确定句子中每个单词不同的权重,以及句子中每个单词的单词向量,使每个单词尽可能的得到与之对应的上下文,为实体节点的精确构建提供了必要条件。
62、从次,本发明采用自注意力机制获取文档的上下文信息表示,避免了现有技术中直接采用句法树提取时严重破坏文档原始结构的弊端;
63、最后,本发明通过动态门机制,充分考虑到句内关系推理时句子的上下文上下文,以及句间关系推理时句子上下文和整个文档的主题信息,能够更为准确的进行句间关系和句内关系抽取;
64、另外,本发明通过将具有上下文感知的实体节点的最终表示与原始的实体节点连接,能够有效避免在多层变换后的模型出现过拟合,使本发明中的模型更具鲁棒性。且本发明通过特殊设计损失函数,使后续训练得到的关系图卷积网络更为准确。
本文地址:https://www.jishuxx.com/zhuanli/20240905/288576.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 YYfuon@163.com 举报,一经查实,本站将立刻删除。